Thanks for starting this thread @schuemie. I really appreciate the ability to have open discussions with differing points of view which is fundamental to science and an open source software community. It’s one of the things that makes OHDSI great.
To summarize my response in a single sentence: You are missing a specification of the system you are building and the lack of a specification is leading you to an implementation that is more complex than it needs to be.
A specification is a document that describes what the system should do. The description is agnostic about how the system is implemented. A specification could be implemented in any general purpose programming language. A specification should also be minimal in the sense that it should give the minimum set of requirements necessary to accomplish the desired behavior. Everything I’ve read so far about system design recommends that a system have a design spec especially if it might involve distributed or concurrent processes. Terminology used in the specification needs to be clearly defined. The specification should be written before the implementation but the spec does not need to be set in stone. The waterfall model of development apparently does not work so we should think of the spec and the implementation as being developed through an iterative process. What I see is that significant progress is being made on Strategus without a formal specification or much feedback/discussion from HADES developers.
Your description above is a starting point but I think it includes some details that are not necessary and lacks at least one key component, a module repository manager.
System Specification
Let’s define the system under consideration as the sum total of all requirements you described above. The complexity of the system can be loosely defined as the number of units of information that a programmer needs to have in their mind when working on a part of the system. The same system can be modularized in different ways and some modularization schemes will be more complex, and thus harder for developers to work on, than others.
A module is a part of the system that represents a set of responsibilities needed for the system. The system can be partitioned into modules by partitioning responsibilities. Modules can be “written with little knowledge of the code in another module” and “reassembled and replaced without reassembly of the whole system.” [1] Since modules are a partitioning, the responsibilities of one module should not overlap with the responsibilities of another module. A module is a mapping from inputs (e.g. JSON file, data) to outputs (e.g. csv files). Modules have an interface that describes how a module interacts with the rest of the system and an implementation that is internal to the module. Modules have both an implementation and interface that can change over time. The set of responsibilities associated with a module is defined when the system is designed and is expected to remain fairly constant over time.
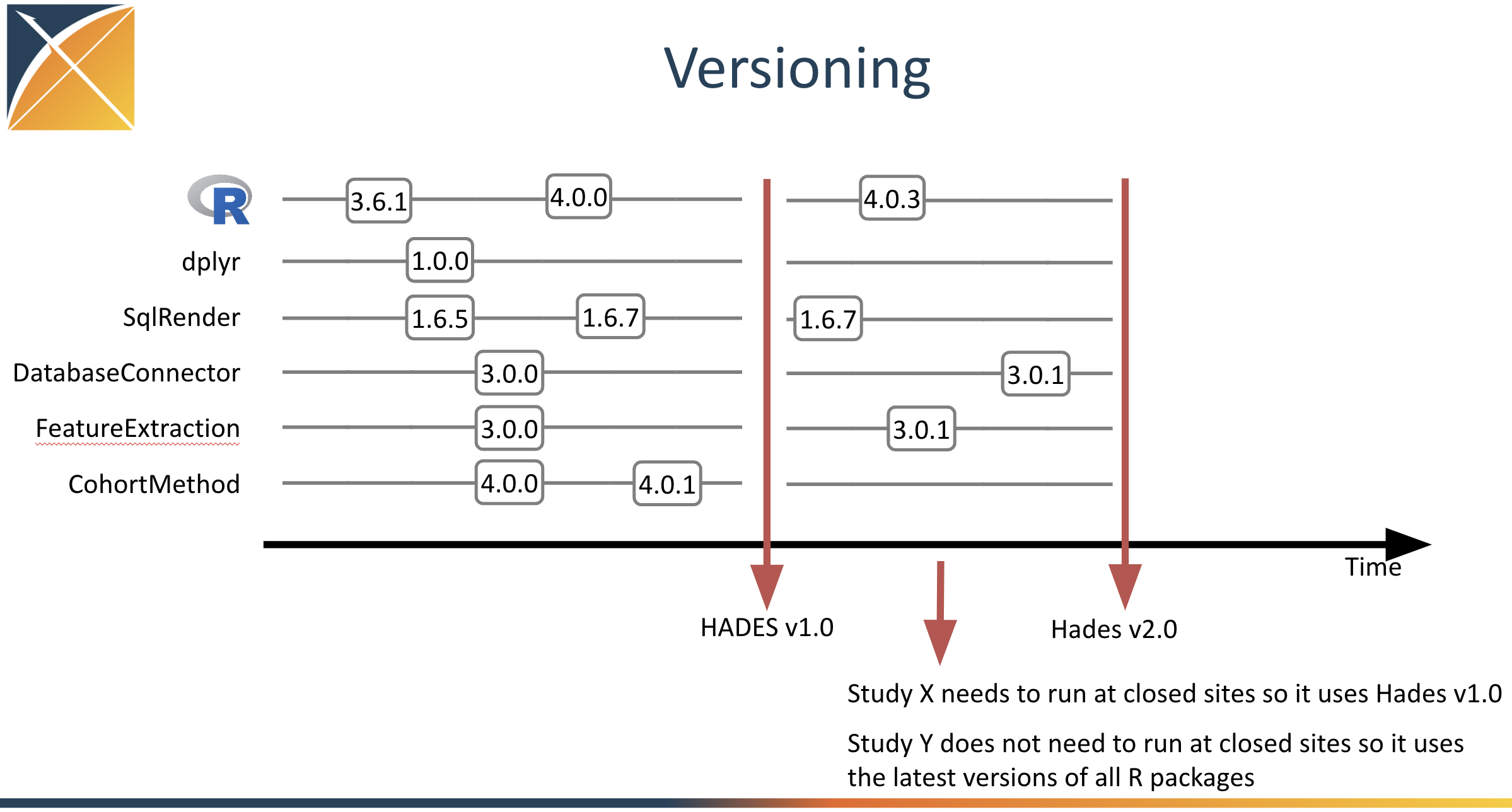
A module version is a module at a point in time. Whenever a module’s implementation or interface changes, a new module version is created.
A study specification is a plain text file that describes how modules (i.e. building blocks) are put together to make an OHDSI study. Study specifications are the input to Strategus.
A site consists of three things
- a place where modules can be installed
- an environment for strategus to select modules and run them
- One or more databases that are needed as input to the modules
Multiple versions of the same module can be installed at a site. Strategus automatically selects the correct module version to run during study execution.
There is one missing component to the system that I’d like to add. A module repository manager is the shared place where modules are installed from. Sites install modules from the module repository manager.
Study requirements
Let’s describe the study as an ordered set of module versions. (In reality I think this should be a partially ordered set since some modules can be executed concurrently but a complete ordering is simpler for this first pass).
Study Alpha = {A1, B1}
Study Beta = {A1, B2}
Study Gamma = {A1, B2, C1}
A study may not contain two different versions of the same module.
Since modules are partitions of responsibilities I’m not sure why one would need to use two different versions of the same module in a single study.
Modules in a must be executed sequentially from right to left. For example in study Alpha = {A1, B1}, the module B1 would be executed before module A1.
Module repository manager requirements
- The module repository manager must make all module versions available to all sites at all times. Any site can ask the repository manager for a specific module version at any time.
- The module repository manager also guarantees that the most recent version of all modules can be used together in a study.
- Given a date, the module repository manager can return the complete list of module versions that were “the most recent versions” on that date. For each date the module repository manager returns a list of all modules that were available on that date and guaranteed to work together.
Module requirements
When a module is installed it is installed with all required dependencies. A key question is if modules need to specify their complete list of recursive dependencies or just their direct dependencies. Either way when a module is installed it must be treated as essentially self contained and be able to support its interface. An installed module = a module that has everything it needs to support its interface.
Site requirements
A site should be able to execute any study at any point in time.
Sites are able to install any module version from the module repository manager. Sites may have multiple versions of the same module installed at the same time.
Strategus requirements
Strategus is responsible for the execution of studies at a site. Strategus may or may not have access to the module repository manager but will have access to all installed modules at a site. At the beginning of each study Strategus instantiates an execution environment. In the execution environment all required modules for each study are made available. Since studies cannot contain multiple versions of the same module the execution environment will also not support multiple versions of the same module. After study execution the execution environment is completely removed and does not persist.
The input strategus receives is represented as an ordered set of studies.
{…, Gamma, Beta, Alpha} which is the same as {…, {A1, B2, C1}, {A1, B2}, {A1, B1}}
Strategus can be in one of the following states:
- Waiting for study
- Instantiating study execution environment
- Executing study modules in order
- Removing study environment
The state transition here is pretty simple 1 → 2 → 3 → 4 → 1
I do think that state 3 might need to be modified if we want to have concurrent execution of modules and we need to consider how an error state might be handled.
This is a first pass at a specification for the system you’re describing that needs iteration and refinement. I think this system could be implemented in R using functions and packages to represent the modules. After all, there are already tons of modules implemented in R using functions and packages. I don’t think there is a need to come up with a new representation of what a module is in R.
Since we want studies to execute with the exact same code every time I think it would make sense for a study to include a complete list of all recursive dependencies (renv.lock file). This is exactly the use case for renv. It looks to me like the current implementation of strategus is using renv to create a whole new implementation of modularization in R where modules include a complete list of their recursive dependencies (example). Your current implementation has both packages and “modules” essentially doubling the number of Hades analytic code repositories. I don’t think modules need to contain a complete list of recursive dependencies for this system to work.
I’ve been critical of using R packages for studies in the past and now I’m advocating their use for modules so I want to clarify my perspective.
- Study specification = plain text file(s) that describe what the study is
- Modules = R packages and functions that partition the responsibilities of the system
Reference & resources
- Parnas’ paper on modules: https://www.win.tue.nl/~wstomv/edu/2ip30/references/criteria_for_modularization.pdf
- Leslie Lampour Lecture: https://youtu.be/-4Yp3j_jk8Q
- TLA+: The TLA+ Home Page
- A Philosophy of Software Design by John Ousterhout
 I am not sure if I answered all of your questions directly, but if there’s something you’d like me to dig into specifically, please let me know and I’ll try to answer.
I am not sure if I answered all of your questions directly, but if there’s something you’d like me to dig into specifically, please let me know and I’ll try to answer.