Clinical Definition
One can find a nice, updated definition for anaphylaxis developed by the Anaphylaxis Committee of the World Allergy Organization (WAO) here:
Turner PJ, Worm M, Ansotegui IJ, et al. Time to revisit the definition and clinical criteria for anaphylaxis?. World Allergy Organ J. 2019;12(10):100066. Published 2019 Oct 31. doi:10.1016/j.waojou.2019.100066
They have revised the definition for anaphylaxis as:
Anaphylaxis is a serious systemic hypersensitivity reaction that is usually rapid in onset and may cause death. Severe anaphylaxis is characterized by potentially life-threatening compromise in breathing and/or the circulation, and may occur without typical skin features or circulatory shock being present. [1]
The paper also provides amended criteria for the diagnosis of anaphylaxis:

[1]
Phenotype History
Previously, the Observational Health Data Sciences and Informatics (OHDSI) community conducted a population-based network retrospective cohort study to characterize the background rates of adverse events of special interest (AESI) for the COVID-19 vaccine, using observational data from 13 databases in 8 countries [2, 3]. Many phenotypes were defined for the AESIs, including one for anaphylaxis.
For the study mentioned above we defined anaphylaxis as all events of anaphylaxis, indexed on a condition of anaphylaxis. Requiring a clean window of 30 days, cohort exit is 1 day after start date. The condition codes/concept were exclusive to anaphylaxis shock due to serum and the unspecified (general) parent code anaphylaxis (without its descendants).

The cohort definition settled on can be found here:
FDA AESI Anaphylaxis events
This definition was based on the FDA definition of anaphylaxis published here:
Center for Biologics Evaluation and Research Office of Biostatistics and Epidemiology. CBER Surveillance Program: Master Protocol Assessment of Risk of Safety Outcomes Following COVID-19 Vaccination. https://www.bestinitiative.org/wp-content/uploads/2021/08/COVID-19-Vaccine-Safety-Inferential-Master-Protocol-Final-2021.pdf.
Other definitions were considered - using a more inclusive/broader concept sets. However, the evaluation in US data sources concluded that including a broader set of codes do not have a material difference on the number of cases detected.
Then along came careful IPCI review
Following the initial AESI work, an additional study was started. The “Adverse Events of Special Interest within COVID-19 Subjects” [4, 5] extends the prior OHDSI work by characterizing the background rates of these AESIs in subjects after their COVID-19 disease (instead of the general population). It is relevant to know how often these AESIs occur amongst patients who suffer the condition vaccines aim to prevent to provide a counterfactual for risk evaluation.
As an OHDSI community, we have seen the power of evaluating phenotypes with Cohort Diagnostics [6], and even with the well-established AESI phenotypes, we still executed Cohort Diagnostics with this study. In fact, we were leveraging Cohort Diagnostics to help each Data Partner review the performance of the AESIs in their data. The expectation was that Cohort Diagnostics would educate Data Partners on when they might need to censor their data within the study (e.g., a data set that lacks inpatient data should not contribute evidence to an AESI that is looking for inpatient data like hemorrhagic stroke). Each Data Partner was asked to review each phenotype within the study using Cohort Diagnostics and assess its performance. The Cohort Diagnostics for this study can be found here:
https://data.ohdsi.org/Covid19SubjectsAesiIncidenceRate/
@mdewilde, @AzzaShoaibi, and myself sat down to evaluate the performance of the AESIs in the Integrated Primary Care Information Project (IPCI). IPCI “is a database containing longitudinal, routinely collected data from computer-based patient records of around 350 GP practices throughout The Netherlands. The IPCI database was initiated in 1992 by the Department of Medical Informatics of the Erasmus University Medical Center in Rotterdam with the objective of enabling better post-marketing surveillance of drugs” [6,7].
As we worked through Cohort Diagnostics, there were AESIs we were expecting to censor from use. For example, since IPCI is a GP database we know inpatient focused definitions like 346-Encephalomyelitis are not appropriate for use within the data. When looking at Cohort Diagnostics we see very low counts of encephalomyelitis. This made sense to us, as IPCI does get some notes from hospital data which make it into the CDM, however we know we do not have good capture of inpatient data and it makes sense to censor it for the study.

However, when we moved on to the phenotype anaphylaxis, we were surprised to learn from Cohort Diagnostics that there were no subjects in IPCI. Based on how anaphylaxis was defined we believed IPCI should have some subjects. A quick look in the EHDEN Database Catalog Concept Browser, an ACHILLES like tool currently only available to EHDEN Data Partners, we can see subjects associated with anaphylaxis. The question was, why were we not seeing them in Cohort Diagnostics for this study?
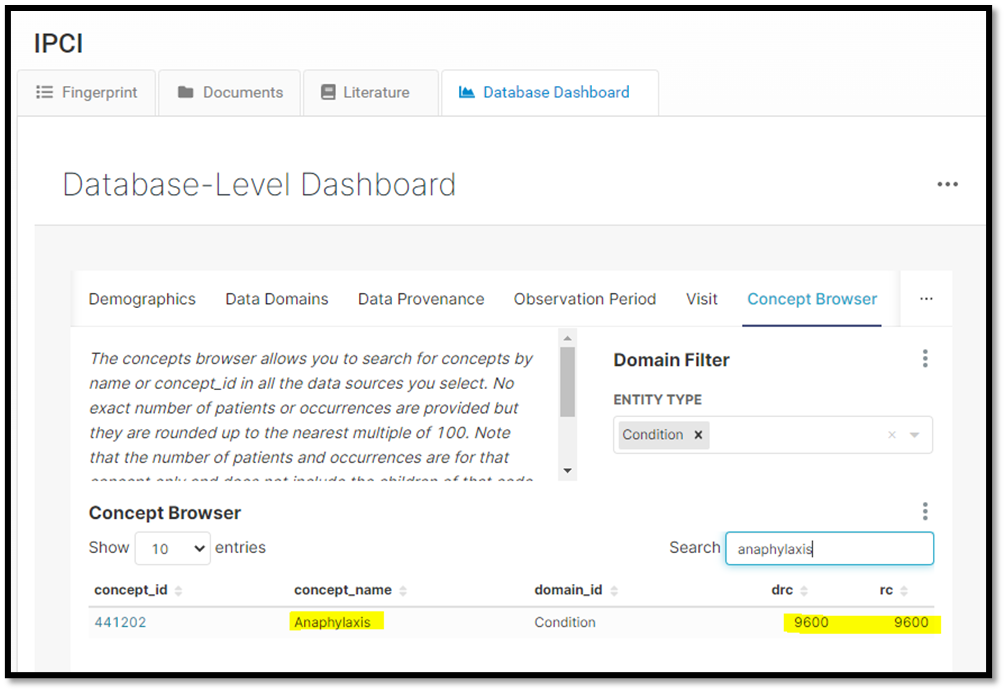
@mdewilde, who has access to the CDM and raw data, was able to quickly find subjects with anaphylaxis. He could see that everything was mapped to 42536383-Anaphylactic shock. IPCI uses ICPC codes in which Erasmus had to map to standard terminologies; their anaphylaxis code was mapped to this standard terminology. “Anaphylactic shock” sounds like a perfectly appropriate concept that should be part of our phenotype. Reviewing the phenotype FDA AESI Anaphylaxis events again we found this concept was not part of the definition! So what happened?
Two things are at play here:
- First, the definition was rigorously tested on mainly US datasets which use ICD9/ICD10 codes. All those codes primarily hang off the standard concept that was used in the original phenotype.
- Second, based on the Vocabulary there are no source codes that are used in the clinical setting that are associated to 42536383-Anaphylactic shock, thus making it an easy standard code to skip over. If the Vocabulary tells us there are no source codes associated with a standard code, it would seem likely that no CDMs would use it in a mapping.
Now that we have learned that IPCI has mapped to this standard code that we previously lacked, we reviewed the phenotype once more to see if any other concepts should be included. Here is the updated definition, the main difference being the concept sets.
[COVID AESI] Anaphylaxis broad events
Reflections:
@mdewilde reflected on this exercise:
Having a library of phenotype definitions prevents us from reinventing the wheel over and over again. We can reuse well thought definitions and get uniformity over different studies. Diabetes in study A can use the same definition as in study B.
On the other side, there is some danger to reuse a phenotype. It’s very easy to pick a phenotype and reuse it in other studies. Not all phenotypes will have a perfect fit to all the different databases or vocab versions. Decisions can be made with a specific study in mind that would not work as expected for other studies. It can be that you need a group of conditions and for some databases only a part of that group will be found, causing unwanted and unexpected bias in the results. Even if phenotypes are validated over many different databases and proofed to give good results for many years, apply on another database can suddenly give different insights and needs adjustments to the definition. Same goes for changes over time on the same set of databases: updated data, new source codes, modifications of the concept mappings can all give different results. And not to forget the changes in the vocab versions with new standard concepts and/or changes in the concept hierarchies may need adjustments to the phenotype definition, especially in the drug domain.
Phenotypes need constant maintenance and validation to make sure they keep working on different databases and vocab releases. Reusing a phenotype for a study is very easy, but needs some discipline to keep validating if it (still) fits the study requirements, sets of target databases, the new available data, and CDM versions. Using the Cohort Diagnostic tool is a great starting point to validate the phenotype definitions and the results in different databases.”
Moral of the story
Cohort Diagnostics is an important part of the study process and should be run, even on well-trodden phenotypes. Just because a phenotype is good on some datasets, does not mean you can infer that the phenotype will be good on all databases. There is nothing incorrect about the previous definition, just it works well in a ICD9/ICD10 world and might have missed subjects in other databases.