Thanks everyone who joined and assisted with logic of PD cohorts.
We updated the concept set for “ingredients that cause parkinsonism, excluding those that are used in PD patients”
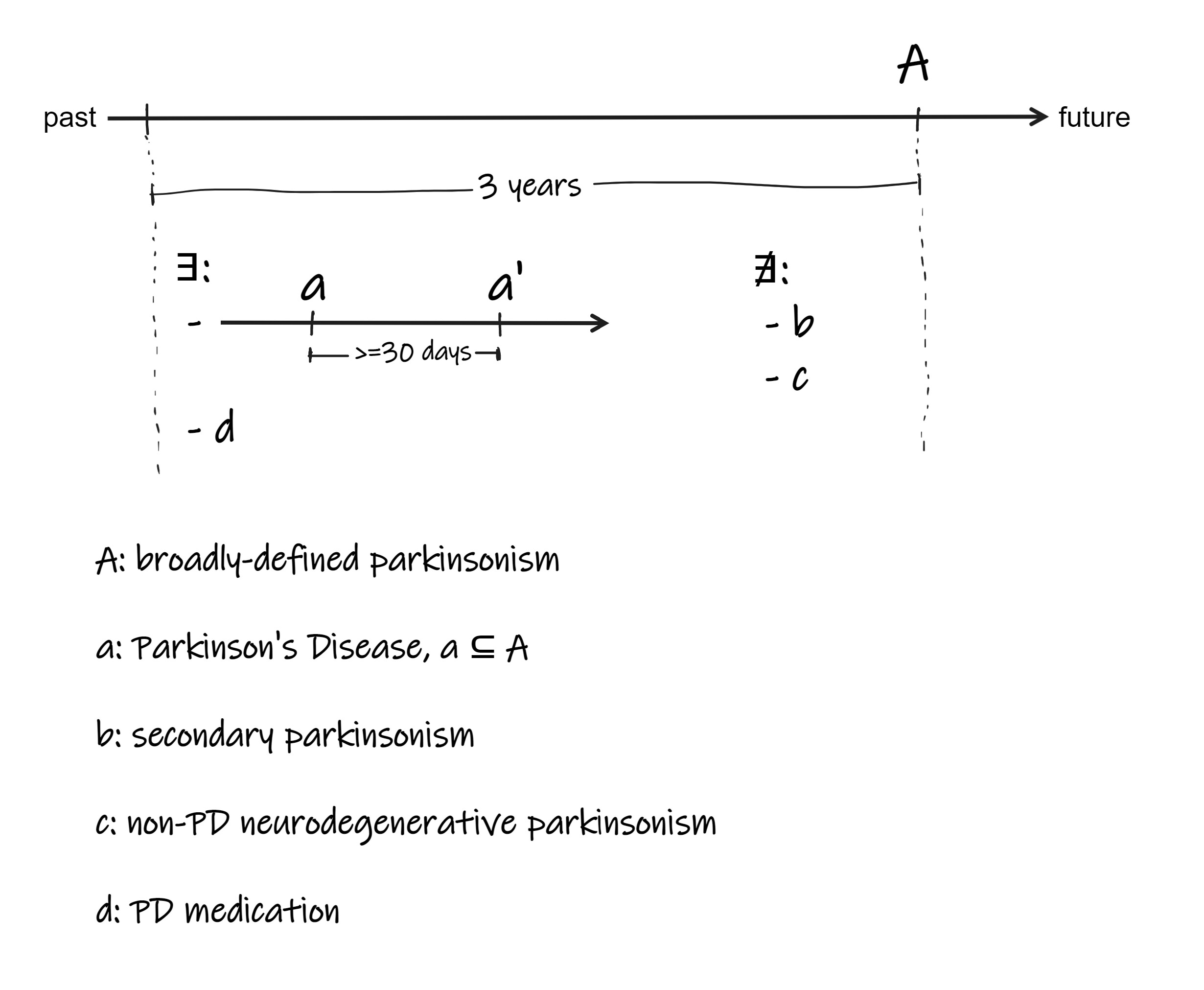
We require more discussion about latest vs earliest index/entry date.
For now, we will work with the “prevalent” cohorts based on “latest event” entry date still.
@Azza_Shoaibi is going to do a logic/quality check on the following cohorts and associated concept sets.
Then, they should be run on Cohort Diagnostics and I’ll review, comment and approve for a network study of prevalence within databases.
Unanimity cohort definitions
#1781748 [Pheb2023][ucepd] Persons with Parkinson’s disease unaminity
#1781760 [Pheb2023][ucepd] Persons with Parkinson’s disease unaminity with PD meds
#1781843 [Pheb2023][ucepd] Persons with Parkinson’s disease unaminity wo confounding meds
#1781844 [Pheb2023][ucepd] Persons with Parkinson’s disease unaminity w PD wo confounding meds
Tiered consensus without specialty:
#1781814 [Pheb2023][ucepd] Persons with Parkinson’s disease tiered consensus wo specialty 1yr (1 of 3)
#1781815 [Pheb2023][ucepd] Persons with Parkinson’s disease tiered consensus wo specialty 2yr (2 of 3)
#1781816 [Pheb2023][ucepd] Persons with Parkinson’s disease tiered consensus wo specialty 3yr (3 of 3)
Tiered consensus with specialty – this allows for precedence in neurologist diagnosed PD (vs non-PD) with 6 different cohorts: 2 specialty (neuro vs non-neuro) and 3 individual years of lookback in a progressive tier.
#1781732 [Pheb2023][ucepd] Persons with Parkinson’s disease tiered consensus w specialty neuro1year (1 of 6)
#1781809 [Pheb2023][ucepd] Persons with Parkinson’s disease tiered consensus w specialty neuro2year (2 of 6)
#1781810 [Pheb2023][ucepd] Persons with Parkinson’s disease tiered consensus w specialty neuro3year (3 of 6)
#1781811 [Pheb2023][ucepd] Persons with Parkinson’s disease tiered consensus w specialty noneuro1yr (4 of 6)
#1781812 [Pheb2023][ucepd] Persons with Parkinson’s disease tiered consensus w specialty noneuro2yr (5 of 6)
#1781813 [Pheb2023][ucepd] Persons with Parkinson’s disease tiered consensus w specialty noneuro3yr (6 of 6)
We discussed two other models (future discussion)
-
Incidence estimates for a PD cohort:
– this requires tracking the date of earliest broad parkinsonism occurrence to be used as incidence date of PD even if a 3 year timeframe to meet a cohort defintion for PD is met 5-10 years later. We do not wish to capture the date when the cohort defintion is met. We also wish to only look at the last 3 years of observation time (because of concern of false positive PD idetnified with a 3 year time frame before a later 3 year timeframe identifies a non-PD neurodegenerative parkinsonism). -
Cohort analysis – assessing persons going in and out of a cohort.
Would like to generate a cohort definition and model such that we model, over time, patients enter the cohort once they meet criteria (3 year timeframe) and can EXIT the cohort once they do not meet criteria (3 year timeframe). We are very interested in the 5-10% of patients that start with not-PD (but meet entry criteria), then meet PD cohort defintion, then exit the definition when it becomes clear later that they do not actually meet a PD cohort defintion. -
We discussed PheValuator and will defer xSpec and xSens cohorts until more clarity about the timeframes needed for proper analysis are worked out.