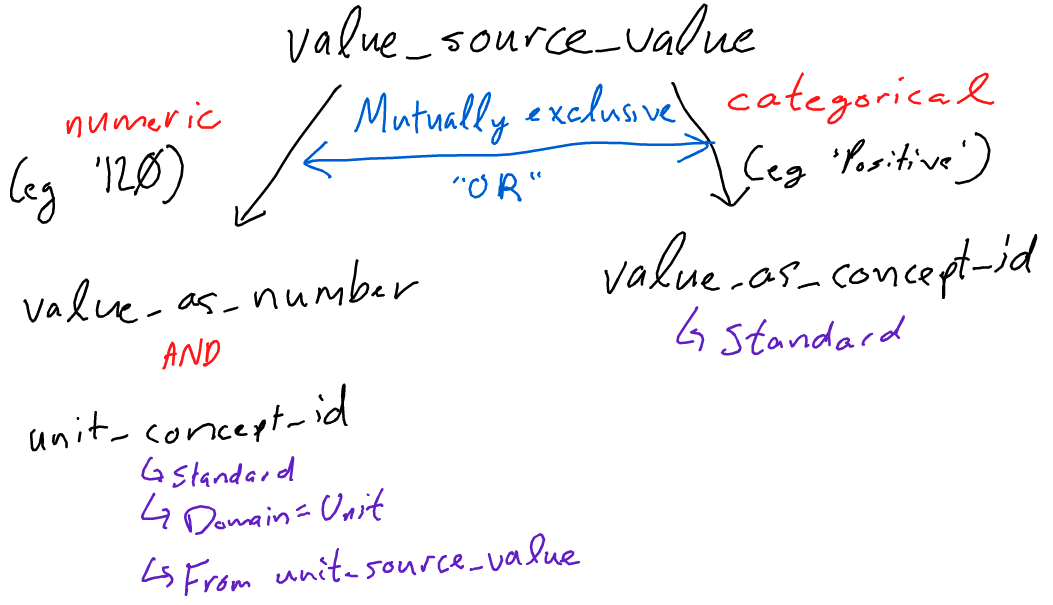
For the measurement table, there are two fields in which results could go:
value_as_number OR value_as_concept_id .
Based on my understanding, these two fields are mutually exclusive. If the value_source_value is a number, the row should be populated with a value_as_number. Similarly, if the value_source_value is a string, the row should be populated with a value_as_concept_id field. The logic is as follows:
Recently, however, I discovered that some EMRs have internal mechanisms that can populate the value_as_concept_id field based on the value_as_number. For instance, if the ‘value_as_number’ is 200 for a measurement_concept_id that is Heart Rate and a unit_concept_id that is Beats per Minute', some EHRs can deduce that the value_as_concept_id` should be one that specifies ‘High’ (a correct deduction).
In this case, can we accept BOTH a ‘value_as_concept_id’ and a ‘value_as_number’ field? Or are the two intended to be mutually exclusive (regardless of whether or not they are concordant)?
Numeric and categorical are not mutually exclusive. As in your example you have 200 beats per minute and an attribute in the source data indicating this is ‘high’ fill in both value as number and value as concept id. This assumes that both the numeric and categorical values are in the source data. The ETL should not make assumptions about what categorical value (value as concept_id) should be based upon numeric values.
I would accept BOTH a ‘value_as_concept_id’ and a ‘value_as_number’ field. Then in the value_source_value field, I would put a concatenation of the two, e.g., “200 : High”. This way, you know the value in both columns are from source.
Perhaps use a pipe instead of a colon as pipes are not in common EHR use but the colon is. Colons are also used as ‘Key : Value’ pairs, so it adds further confusion.
Example: 200 | High
I would interpret this differently. In this example, I look at the value “high” as a description of the result (200 beats/min). Ideally, the range low and high field would be filled out and the value “high” wouldn’t be needed. In either case, I might only keep the value_as_number field populated and maybe put the “high” in the source value as additional value. @Christian_Reich what do you think?
I think for most measurements they are mutually exclusive. Otherwise our data will be mess to analyze. (and we will have huge variability). Think HIV viral load. Not many OHDSI network studies currently use internationally a logic for numbers.
Current model does not have a “flag” formally.
Current model can classify into 3 classes. (if you need more, it is a gap (extend the model) or it needs to be another row) (what I would maybe prefer in some cases)
possible classes now are
<low, >high and between low and high. The idea is that for each row you also deposit high low reference values. (which feels quite redundant btw)
It seems like there is a bit of ambiguity and disagreement on this front. What is an appropriate forum where the OHDSI community could hopefully come to a consensus on this front?
You are in the right place. We are going to discuss it when we revise the MEASUREMENT table. The other thing we need to discuss is the relationship between pre-coordinated (“Positive Covid test”) vs post-coordinated (“Covid test” - “Positve”), and the use of “Yes” and “No”. This is helter-skelter right now. So, please keep us focussed.
Can you, please, elaborate why?
Let’s say, if I want to define a cohort of patients with tachicardia, I could use any definition: “value_as_number >100” or “value_as_concept_id ='High”'.
I believe researchers are interested not in exact numbers, but ranges. Basically, there are 3 ranges: below, above and inside min / max of normal.
Value_as_concept_Id can have more ranges, for example, “above” can be “high” and “very high”.
Thus, value_as_concept_id can give us reacher number of possible covariates in PLP (I’m not a data scientist, so correct me if I’m wrong here), but value_as_number allows to define custom range.
This way, I would like to allow both of them to be populated.
I do not think your assertion “researchers are interested not in exact numbers” is correct, at least not from a data fidelity perspective. Researchers I think want to use data categorized into neat buckets during the analysis phase, but I don’t think researchers want to loose fidelity within the source data repository like an OMOP warehouse.
I think measurements.value_as_number should be populated with numeric values only. If you want to derive additional observation that the measurement fell within a range, that is what I would do instead of storing a category value in the measurements.value_as_concept_id = “high”. Having the value_as_concept_id = “high” doesn’t tell me what the threshold was used to make that determination.
If things change in the future where the range threshold change, you can go back to the exact measurement value to re-categorize and re-run your analysis. I don’t think it is a big burden to derive such categories from exact values during analysis. That is just my opinion having worked with numbers and leveraging those raw numbers for different analysis and studies over time.
As an example - lets say the measurement is electrocardiograph lead aVF ST at J+60ms (LOINC.3019957) with the exact value of 125 uV and for analysis of ST Elevation Myocardial Infarction the threshold is >= 100uV in today’s criteria. So what I think you are suggesting is to store the text value “>100” in measurements.value-as_number=">100" and measurements.value_as_concept_id=45879210 (“Above”). What if 2 years down the road we change the analysis threshold to above 200uV in lead aVF for STEMI? What is stored in the measurements table is still correct, but without knowing the exact aVF ST at J+60ms value, I don’t know if this measurement really qualifies for the new 200uV threshold.
I say no, if your source data has a number, a range and a textual result you should capture all that information in a single measurement record. Yes, analysts will have to account for both possibilities, numeric and text, but that is done all the time. Are those on the side of mutually exclusive arguing that if both values exist in the source data that two records be created, or only numeric or the text be recorded?
Hello everyone.
I am not a Data Scientist, just a Medical Doctor involved in research.
And excuses for my poor English as I am a francophone (Togo, West Africa).
[value_as_number OR value_as_concept_id] OR [value_as_number AND value_as_concept_id] seems to be the topic of discussion.
The answer depends on the [value_source_value]
We know that for some Lab tests the result depends on the type of Machine (Analyzer) and the Standards used. For each measurement_concept_id to define the value_as_concept_id (“High” and “Low”) we have to take in consideration these informations (Analyzer and Standards used).
Science is progressing and if today we are more interested in the value_as_concept_id in decision-making, we may need the value_as_number in the future.
Example: for HIV the value_as_concept_id “Positive” or “Negative” are highly used for diagnostics but while following up a treated patient the value_as_number “Viral load” is very important.
The challenge is to find a way out in building:
[value_as_number OR value_as_concept_id] AND [value_as_number AND value_as_concept_id]
This will be more sustainable
@ Dr_Amadou, what you described is perfect. I was working on an example where I see different results from different labs on standard blood work, but your example illustrates the point better than the example I was building.
One additional caveat I will add is on the psychology of how we react to labels has been well documented over the years. It is very possible that a provider might treat a patient, opposed to another patient with the same numerical result, differently due to the different labels labs put on said ranges. From a data nerd point of view, I would love to see a study done on treatment plans created where the the numerical data is in the fuzzy range but defined by the different range labels.
Lab systems is a very good example - in our system we often get source data that include the Normal range, a low and high value. One way I am presently mapping some lab and device generated measurements is:
Store the numeric value in measurement.value_as_number
Store the units as a concept in measurement.unit_concept_id
The ETL determines whether the value is within range and set the measurement.value_as_concept_id=“Below” | “Above” | “Normal”. You can use other concepts per the appropriate concept context.
The measurement.measurement_source_value contains the lab system name, device name/model, etc. If the laboratory source value is normalized and stored in #1-#3, the original value and range information is appended to the source ID here as well. For example, if one electrocardiograph device reports amplitude in units of millimeter (mm) and another reports in milli-volts, both are normalized by the ETL to micro-volts (uV). Another is example I deal with is weight adjusted echo measurements (for veterinary patients weight varies greatly).
I agree with this sentiment; there are many contingencies for whether we would want one or both values. One caveat, however, is that a measurement_concept_id may only really lend itself to one particular result. Going off of your example:
HIV viral load may be logged with the concept ID ‘HIV viral load’ (4201046) and we would expect a quantitative value in the value_as_number field (as a float).
HIV status, however, may be logged with the concept ID ‘Finding of HIV status’ (4276586). This kind of ‘categorical’ result should be logged in the value_as_concept_id field (with a ‘Negative’ or ‘Positive’).
Therefore, I have the following questions:
If a source value provides us with two pieces of information (e.g. ‘zzz | Positive’), should we accept both pieces of information (e.g. value_as_number = ‘zzz’ and value_as_concept_id = ‘Positive’) in one record or should the information be triaged into two separate records, if possible?
NOTE: I personally advocate for the latter approach but I recognize the potential technical limitations of such a proposal.
Are there any measurement_concept_ids that may unequivocally lend itself to having both a value_as_concept_id and a value_as_number? My understanding is that every record should only represent one particular finding and that the measurement_concept_id defines whether or not a result is inherently numeric in nature (e.g. viral load) or categorical (HIV status).
As brought up by @mkwong in his last comment: should we trust ETLs to make this determination of what the value_as_concept_id based on what I imagine is a number in the source_value field? It is a case of inductive reasoning (albeit done by a machine) which - in my opinion - should be the responsibility of researchers.
My apologies if some of my conceptions are not well grounded; I am relatively junior to the OHDSI community.
As per @mkwong comment: I thought that it’s not required to infer if values are below/above the normal range during the ETL.
a) For using measurements as criteria when constructing a cohort we usually prefer exact numbers and not just above/below
b) For using measurements as covariates, the inference takes place during the analytical stage when a value is compared to range_low/range_high. @schuemie can correct me if I’m wrong.
I don’t see why storing both value_as_concept_id and value_as_number in one record is an issue. But if you split them into two records, you may have issues with constructing cohorts that rely on having X occurrences of a measurement.
We normally don’t want to store the result against the rules, right? So quantitative scale consist with value_as_number, while ordinal, qualitative and nominal scales - with value_as_concept_id.
Another story is ‘Quantitative or Ordinal scale’ in LOINC (antimicrobial testing concepts only) and a batch of mixed SNOMED concepts where the scale type is not even defined. A test result can be legitimately stored as either a number or a concept or even both at once. Why is it a problem? You can look into figures or concepts during analysis.
This discussion shows very well why the original numerical result should be always preserved. The issue is that some of the systems record both numerical result and its interpretation according to some criteria/standard that isn’t even specified. When it’s just above/below/between the normal range and once you have range high/low captured, it might be omitted since you can repeat the logic during the analysis. But when it comes to other categorical responses (no matter ordered or not, e.g. 1+, 2+, 3+, positive, reactive, intermediate), you might want to store it as value_as_concept_id. The major reason is simplification of the studies - no need to care about the normal ranges then. So the question is: do we allow to add value_as_concept_id to the value_as_number when measurement_concept_id is of quantitative scale? I’d say “yes” and the reason is that we’ll never clean it up. People do not follow the scales. What we’ve seen many times in the source within one single test is a mixture of numerical/categorical values and a lot of different descriptors in the same field (quality of the sample, level of alert, etc.).
A possible improvement would be an introduction of the interpretation_concept_id filed which implies an additional interpretation (that not expected directly within this test) of the numerical result. But this would be a great amount of work on the ETL side to sort this out.
This concept implies the antibody test and hasn’t scale type specified though. But from the context, it should not be numerical.
I’d not suggest splitting the records. 1 record = 1 test. Even though you have one number + several interpretations, keep the number and try to map to one single concept. ‘Abnormal presence of’ is a good example.
Please see above.
100% agree. Let’s at least sort out what is provided by the source.