family history of type 2 diabetes (DM2)
0 = no relative with DM2,
1 = at least 1 second degree relative with DM2 ,
2 = 1 first degree relative with DM2,
3 = 1 first degree relative and at least 1 second degree relative with DM2,
4 = 2 or more first degree relatives with DM 2
What I have thought of so far:
0 → 4334340 no family history diabetes type 2
1 → Observation_concept_id: 4051106 family history diabetes type 2
Value_concept_id: 44783070 Second degree blood relative
Value as number: 1
Qualifier value: 4172704 >
Categories 2 and 4 I could map according to the approach for category 1
However, I can not think of how to map category 1. Maybe I could split it up into two parts (“first degree relative” and “at least 1 second degree relative with DM2”) and then combine with fact_relationship? Or is it so complex that we should rather think about using the 2 billion approach?
One out of many is to model the problem as ‘DM2 risk score’ (on scale 0 to 1) and assign each scenario a score value and record it that way.
Certain data are hard to represent it such a way that an international network study would use it in the same way accross datasets.
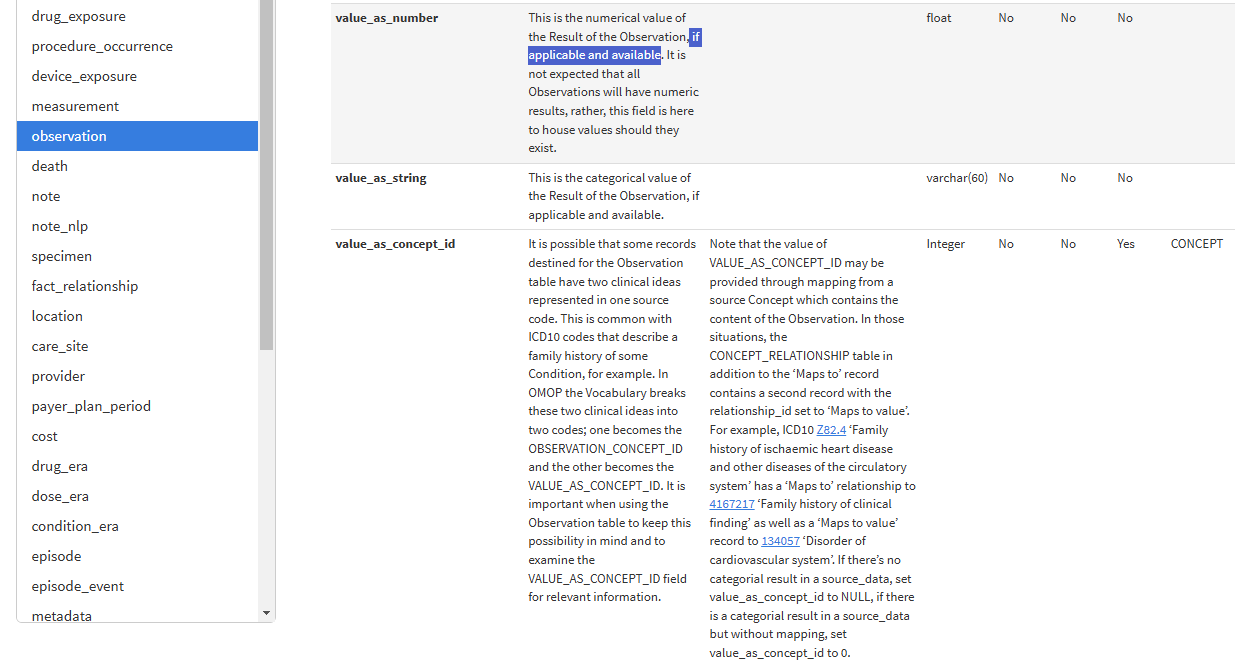
value as concept id and value as number are typically mutually exclusive. (not sure if the spec says so explicitly)
it does not. Maybe it should strongly recommend it at least.
Moreover, for a given concept of measurement, it should perhaps explicitly declare it to be categorical or numeric and imply if researcher should expect value to be number or value as concept.
Every good data dictionary of a good clinical trial is stating that. Well, it is EHR context here, not a clinical trial but still a bit relevant.
Per my old paper on data sharing:
You are right, this is a concept that is too specific for inclusion in a network study, hence that gives more freedom in finding an approprioate solution for our use case. A ‘DM2 risk score’ approach sounds nice, but available risk score concepts in the field of diabetes in athena are too specific. Hence maybe we will consider a 2billion concept or generally dividing the categories into family history of T2D and no family history of T2D.
Thanks for the CONSIDER statement, this is really helpful for us as we are working on harmonization of clinical studies and FAIRification.