Here’s a buch of cases where the same concept can have different meaning.
For example it can be temporary HCPCS codes (like Q2042 and Q2041).
OHDSI has to have unique identifier (concept_id) for each concept,
in Athena you can see Q2041 Axicabtagene ciloleucel
which is YESCARTA (current concept meaning).
but then you may notice that
It was Remapped to Injection, von willebrand factor complex (human), wilate, 1 i.u. vwf:rco
and this statement was true before 1-Jan-2019 (the date Q2041 become YESCARTA)
So, to represent Q2041 as YESCARTA in 2019
and Q2041 as von willebrand factor complex we need to make two entries in the CONCEPT table
concept_id
concept_code
concept_name
valid_start_date
valid_end_date
12345678 (new concept_id)
Q2041
YESCARTA
01-01-2019
31-12-2099
40664685 (old concept_id)
Q2041
von willebrand factor complex
01-01-1970
31-12-2018
and respectively CONCEPT_RELATIONSHIP will have these relationships:
40664685 (old concept_id) Maps to von willebrand factor complex concept
12345678 (new concept_id) Maps to YESCARTA concept
@Dymshyts is warning everybody in the community about a change in the vocabulary rules. For a few select databases, concept_code is no longer a unique identifier: NDC, HCPCS and DRG. You now need to also check the validity dates.
Why is this important? If your tool or analytic depends on them being unique speak up or hold your piece forever.
Concept_id values of course remain unique identifiers for all Concepts.
I want to understand the impact. Is a concept code unique within a domain or vocab when joining through the concept relationship table via ‘maps to’ and is standard or is there a potential for duality here as well?
This is not relevant to anything inside the OMOP CDM System, because there all Concepts are referred to by their concept_id. And that is unique.
However, if you do something with the concept_code, e.g. look them up in your ETL or so, so far all you had to do was to group by concept_code and vocabulary_id, and you had a unique result. This is still the case for most vocabularies, but not all any longer.
If they are standard, they will be mapped to themselves in concept_relationship as usual. If they are non-standard (which is usually the case for NDC), they will be mapped to appropriate standard concepts.
The impact is: when you have HCPCS, DRG or NDC in your data, you will be joining these codes to the Concept table to get concept_ids.
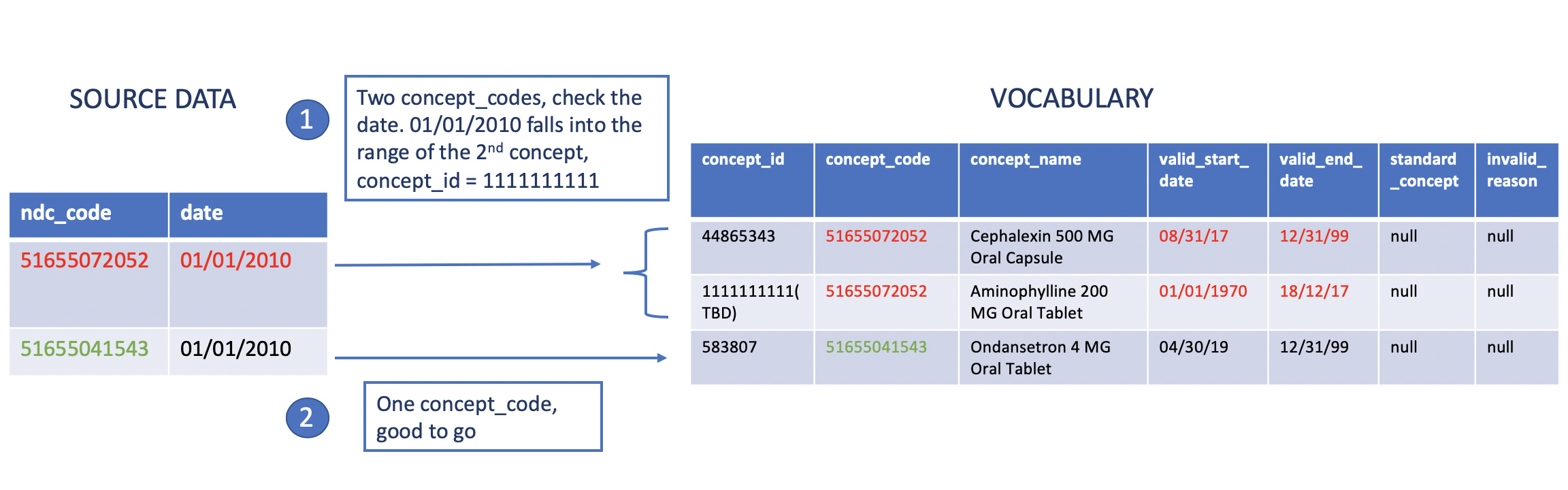
At this point, you need to check if there are two or more valid (non necessarily standard, just having invalid_reason = null) concepts with the same concept_code within one of these vocabularies.
If they exist, you will have take the date of the record and see if it falls inside one of the valid_start_date - valid_end_date periods.
See the picture below:
Ok, I see. There is a temporal dimension to these codes which changes there context completely. We must check when they existed to understand their clinical meaning.
We build a large standard mapping which includes C1 and C2 for all concepts. Time in the above situation (NDC) is when the drug was used? If so mapping must be done with the actual fact.
We are changing this regardless but maybe sooner :slight_smile
Add a new concept invalid reason ‘R’ for Re-used or Re-purposed. Above example has a valid_end_date 18/12/17 which means concept given today’s date is invalid, so there should be a reason why it is no longer valid.
Remove valid_start/end date and invalid reason from concept relationship. Currently you only create valid relationships and leaving these values in concept relationship will only cause confusion when ETL needs to start checking dates for Re-purposed concepts.
Explain that ETL needs to check the valid date range of the source concept for those vocabularies where a source code may be repurposed.
I disagree with removing the valid_start/end date since there are many researchers that are not just using current codes but are attempting to do analyses over time. Removing any relationships that are no longer valid will eliminate the possibility of doing any retrospective work.
I think you misinterpreted the request to remove valid date range and invalid flag from concept_relationship. If you check concept relationship you will see that all relationships are valid.
select invalid_reason, valid_end_date, count(*)
from concept_relationship
group by 1, 2
invalid_reason
valid_end_date
count
2099-12-31
41991208
So those fields, in concept relationship, provide no value. But that does not mean the elimination of the possibility of doing retrospective work, because the ‘Maps to’ relationship still exists for concepts that have been determined to be no longer valid.
select concept.invalid_reason, count(*)
from concept
JOIN concept_relationship ON concept_id_1 = concept.concept_id
WHERE relationship_id = ‘Maps to’
group by 1
invalid_reason
count
4507504
D
343228
U
292964
The concept became invalid (which is where you need to check the valid date range), but the relationship has not been removed. The possible confusion about which table one needs to check for valid date range and the invalid flag is the reason I suggest they be removed from Concept Relationship.
Right. We use them only for development purpose. So in production those fields seems to be redundant. Anyway, I would keep them for cases like these:
You create custom relationships originating from 2 billion concepts, then you fix them and fill valid_start/end date and invalid reason. So, it’s fine to give the users CONCEPT_RELATIONSHIP with these fields, so they can use them.
Look, you have concept A (1970 -2017) and B (2017 - 2099). In both cases you need to check the valid_start/end dates. So, both of them should have invalid_reason =‘R’, right?
Well, the convention is that NULL is valid today. The fact that there may be another Concept with invalid_reason=‘R’ will be apparent if they search for the concept_code. They’ll find one with R, and one with NULL, and they know, hopefully, what to do with that. We need to explain that well in the Book of OHDSI.
Still, it may be confusing, look:
I have my source concept, and I join it with concept, concept_relatationship, and I end up with two standard target concepts. I don’t even know that it is a problem, because it looks like the ordiary mapping to several standard concepts. Usual queries will now know whether duplicate is in the CONCEPT or CONCEPT_RELATIONSHIP.
Means, that we need to add the check by the valid dates for all the concepts, which makes invalid_reason=‘R’ unecessary, or to check all the concepts whether they have the same concept_code but with invalid_reason=‘R’ (which is one more step anyway).
So, looks like if you assign ‘R’ to only one of them, It doesn’t really help.
Hm. I am not following. What mapping are you talking about? This is a lookup.
So, the user has a source code in hand and looks it up in the CONCEPT table, filtering for the right vocabulary_id. Instead of one two (or more) concepts show up, one with invalid_reason=NULL, and the other one invalid_reason=‘R’. The user will then say “Uh-oh, I need to disambiguate using the valid dates”. And do that.
Ok, I agree.
Concept with the previous meaning will have invalid_reason =‘R’
With the current meaning invalid_reason = NULL.
In ETL you will need to check whether the event_date belongs to CONCEPT valid start - end date inteval for all concepts, anyway.
After 5 years, we finally made it, not in the publicly available OHDSI vocabulary yet, but only in our local JnJ version. Hope, the OHDSI vocabulary team will adopt our approach soon or release something similar that allows to work with the codes changing their meaning
Great! The problem is we can’t run the UPDATE/INSERT against the vocabulary as the end product. The whole system how the vocabularies are staged in the dev environment has to be overhauled.
Have you done a step closer, Dima?
Not necessary, do everything the way you’re doing now, and then do a little postprocessing.
drop INDEX “idx_unique_concept_code”
;
CREATE UNIQUE INDEX idx_unique_concept_code ON concept (vocabulary_id, concept_code, valid_start_date) WHERE vocabulary_id NOT IN (‘DRG’, ‘SMQ’) AND concept_code <> ‘OMOP generated’
;
insert new concepts into concpet table and corresponding tables (concept_relationship, concept_ancestor),
;
update old concepts
Yeah, but we can’t solve one problem by creating another with potentially more negative impact.
These concepts have to be under control in the reproducible refresh process.
We do make exceptions and shortcuts here and there, but we’ve already been in a situation where the technical dept-associated costs were more than the actual maintenance costs.
There should be a solid reason to get there back.