Friends,
Over the years, we’ve had a number of threads started about vocabulary versioning and managing change (e.g. here, here, here) but it’s time to come back to this thought because I’ve personally experienced the brunt of being embarrassed by the vocab management process. Or as @Christian_Reich calls it, “egg on face” moment. ![]()
The Situation: In N3C we built a COVID phenotype that looks across conditions and measurements. This phenotype is soon to be celebrating its first birthday ![]() . Last week I was on the N3C Phenotype & Data Acquisition Office Hours, when a lovely collaborator from an OMOP site stopped by and reported this Issue: Non-standard OMOP concepts in phenotype. I was flabbergasted. I would never dare to put non-standard concepts in a concept set – @Patrick_Ryan has taught me better than this.
. Last week I was on the N3C Phenotype & Data Acquisition Office Hours, when a lovely collaborator from an OMOP site stopped by and reported this Issue: Non-standard OMOP concepts in phenotype. I was flabbergasted. I would never dare to put non-standard concepts in a concept set – @Patrick_Ryan has taught me better than this.
Well… it turns out the site was right! The Vocabulary had updated and depreciated a number of our OMOP Extensions we originally used to find COVID. This, in itself, makes complete sense. It’s understood that newer concepts may exist to substitute. What didn’t make sense: I could not after reviewing the vocabulary release notes determine which vocabulary release this depreciation became effective. When I inquired with @mik, he mentioned the Valid Start/End Dates may not correspond with the release in which this depreciation occurred.
The Underlying Use Case: I’ve been running COVID studies for the last year and have a number of phenotypes using these depreciated concepts. I need the ability to tell people when they were really effective through and in what version of the vocabulary they are no longer usable. The only way to do this today is to manually look at the delta from release to release to determine when the depreciation occurred. The problem is, I don’t maintain the Vocabulary (![]() those who do)… I should not have to do the dirty work of following the bread crumbs of a release. The concept table or other metadata associated to the Vocabulary files should have the ability to tell me when the concept entered into existence and when it was depreciated.
those who do)… I should not have to do the dirty work of following the bread crumbs of a release. The concept table or other metadata associated to the Vocabulary files should have the ability to tell me when the concept entered into existence and when it was depreciated.
We all have stories like this. @Christophe_Lambert mentioned some of his own problems with depreciated concepts in ETL in a community discussion this year.
The Other Problem: This week I wanted to run an analysis using the newly minted J&J vaccine concepts in OMOP data. I know that J&J codes were released by CPT4 in January. What I don’t know from the concept table is when these codes went into existence. The non-standard CPT4 code has been given this record:
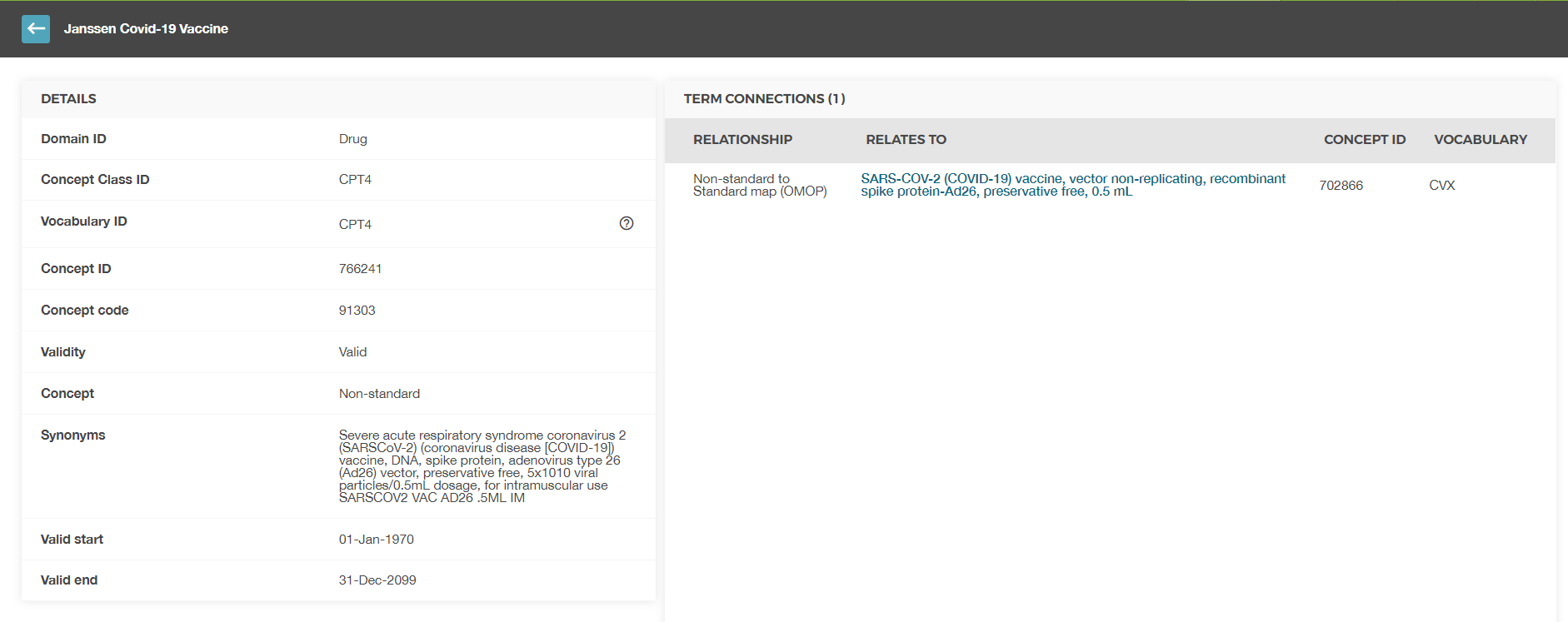
I understand from our tribal memory that we use the 1970s to invoke something that we don’t know when it went into existence. However, we know the time and space when this code was issued. It may be that the data from CPT4 is difficult to ascribe this date field. I can concede that.
Ok, so I don’t know when this code came into existence from its non-standard but if I look up the standard code, it’s a little better:

Still. I actually don’t know when it was released and available for OHDSI Vocab users to build concept sets. Why does this matter? I’m trying to understand the moving pieces of OMOP. If I can stratify when the concept was issued and available in the concept table, I can identify which CDMs I work with that have updated their vocabulary to include this. It allows me to know whether they may have used the concept ID, as issued, or mapped into a 0 - no matching concept.
I understand these use cases were rare before March 2020. However, it’s time to expose that we need a better system for change management in OMOP Vocabulary releases. I heard similar concerns from All of Us sites during their semi-annual meeting last week. I’m adding my friends in network research (@cukarthik @samart3 @roger.carlson @clairblacketer @DaveraG @Harold_Lehmann @stephanieshong @callahantiff @ericaVoss @Rijnbeek @MPhilofsky @gregk @Adam_Black @Andrew) who no doubt feel this pain.
The time is now to address this use case. It can’t be ignored anymore.