@schuemie In the spirit of LEGEND, just out today in BMJ
Angiotensin converting enzyme inhibitors and risk of lung cancer: population based cohort study
| OHDSI Home | Forums | Wiki | Github |
@schuemie In the spirit of LEGEND, just out today in BMJ
Angiotensin converting enzyme inhibitors and risk of lung cancer: population based cohort study
(rolling eyes)
Some (negative) controls would have been helpful!
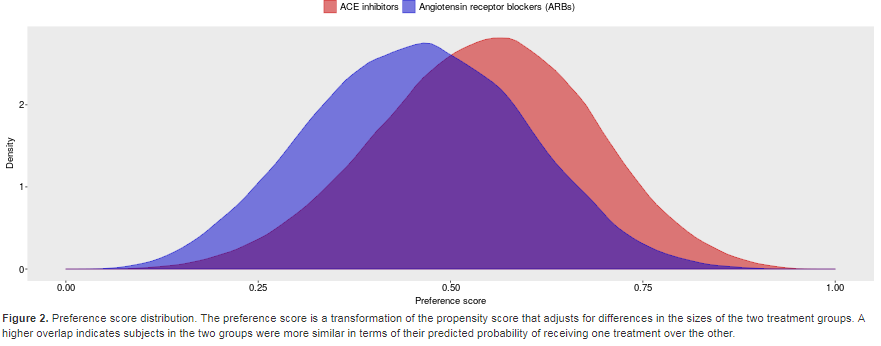
Also, it is not obvious they performed propensity score adjustment, although in all DBs in LEGEND there was high PS overlap to begin with:
Thanks!
LEGEND can add so much more to this ACE vs ARB conversation! First thing I did when I saw this was run over to our results, no different in malignancy. I’d be curious what it is for lung cancer or if we can replicate their CPRD results
This BMJ paper was actually the featured paper on my JournalWatch e-mail for today. And the accompanying editorial (https://www.bmj.com/content/363/bmj.k4337) praised the “rigorous analytical approach” and seemed to believe the results, stating that “concerns about the long term risk of lung cancer should be balanced against gains in life expectancy associated with use of ACEIs”. They also
Dear all, I see your comments and read the paper because I was curious. From an Epi perspective this is actually an analysis carried out well. It certainly will be good to see replication and the effect size is small leaving space for some residual confounding. I do not believe this could have been easily addressed with negative controls, since the relationship is not easy and may be affected my multiple issues, which are not always addressed through negative controls (indication, diagnostic bias, lag times) The authors did use an active control group already, which addresses most of the confounding. Would be interesting to see other results, but requires careful analysis
Yes, I realize many would consider this to be a well executed study, and I agree there are many studies that are published that are worse. However, in OHDSI we have been developing best practices that this study does not adhere to. We’ve started formulating these best practices here, although they’re far from complete. Let me discuss these best practices by comparing this paper to our own Keppra study:
OHDSI’s general principles are:
Transparency: others should be able to reproduce your study in every detail using the information you provide.
Prespecify what you’re going to estimate and how: this will avoid hidden multiple testing (fishing expeditions, p-value hacking). Run your analysis only once.
Validation of your analysis: you should have evidence that your analysis does what you say it does (showing that statistics that are produced have nominal operating characteristics (e.g. p-value calibration), showing that specific important assumptions are met (e.g. covariate balance), using unit tests to validate pieces of code, etc.)
Let’s start with transparancy:
Hick’s et al. do a good job of providing the READ codes used to find the outcome, and mention they define the outcome as ‘a diagnosis of incident lung cancer’, suggesting any first occurrence of one of these codes was considered an outcome, but they could have been more explicit. No exact definition is given of the exposures, and how the covariates are defined. In constrast, our paper includes the full protocol and analysis source code, so leaving no ambiguity.
Prespecify
It does not seem Hick’s analysis was preregistered anywhere, leaving us to wonder whether p-hacking took place, and also doesn’t allow us to monitor publication bias. In constrast, our Keppra protocol was registered on the OHDSI Wiki, including full specification of the analysis code.
Validation of your analysis
The assumption that using an active comparator guarantees no confounding is hard to defend, and nowhere do Hick’s et al check this assumption. Even though one could argue that negative controls might not be able to detect all forms of bias, that is no excuse not to include them as Hick’s et al did. Our Keppra study included 100 negative control outcomes, showing negligable residual confounding. Because Hick’s et al did not use propensity scores, they were not able to check whether covariate balance was achieved. In contrast, in the Keppra study, we observed balance on al >10,000 covariates (unfortunately not included in the paper).
Another form of validation would be to replicate this study in other databases. Hick’s et al solely relied on CPRD, in our paper we already included 7 databases.
The paper by Hick’s et al. does not go into how their analysis process was validated, and although I’m sure they’ve done a good job, there’s no way for me to check. There is no way any of us can see whether result is real, or simply the consequence of an error when copy-pasting values from one place to the other, or whether a programming error was made (again, negative controls would have been helpful). In contrast, our code is publicly available for review, and has many mechanisms in place to safeguard validity .
Finally, as argued at the OHDSI Symposium as well as our recent paper, isolated, one-off studies such as this one tend to be hard to reproduce because of study bias, publication bias, and p-hacking, as also covered in my points above. Preferably we would include lung cancer as one of the outcomes in our current LEGEND study on hypertension treatments.
Dear Martijn,
I have thought about your response and extract that what you would like is:
transparency, pre specification and validation of analysis as per OHDSI’s principles. I think these are excellent principles and much align with the principles in the pharmacoepi community, which have been described by specified by RECORD(PE) (ISPE working group), and a joint paper by ISPE and ISPOR last year.
I have no specific interest in this paper nor the McGill group, and do not know what was done exactly, but I was triggered by your comment of “the rolling eyes”, which to me indicated you thought this was done badly.
I personally believe it is wise to not jump to conclusions and respect what as been done, until we can prove the opposite. Let me offer you my perspective from a farepi perspective
Prespecification: every study in CPRD needs to be pre-specified and submitted and approved by ISAC, so I believe that they have pre-specified the analysis and codes, and that if you would request it is available, did you do try?
Transparency, in the EU all studies need to be registered in EU PAS, I do not know for Canada, but again would assume that all codes can be easily made available if you would require. Transparency can also be provided on request, one may just ask. Regarding the Keppra study you reference, I noticed that the links to codes do not all work (e.g. convulsions), so the best better alternative for transparency might be to include them in the appendixes which is what the ISPE /RECORD PE community requires.
We totally agree that analyses will need to be repeated in other databases to look at consistency of an association and that a single database study does not do the job, however the lack of this does not necessarily invalidate the current analysis, it is just not clear whether other sources would show the same. I would strongly argue against you that using negative controls and p-value correction does the job of dealing with undetected bias/confounding. It is nice as a concept and sensitivity analysis, but just taking 100 events which do not seem to be related to a drug and model their estimates, which will be an amalgamation of all types of biases/confounding that may exist do not necessarily deal with the bias and confounding that exist in a specific association and database. I personally do believe that the bias in specific associations need to be addressed by association specific sensitivity analyses, using different designs and definitions and cannot be just dealt with in an automated pipeline, which is a mixture of all types of potential problems. As epidemiologists we would like to see the impact of the different assumptions, reason about it and not assume we could deal with it by adjustment for an unknown mixture of errors. It requires clinical domain specific insight
As a default all scientists have a code for integrity and I start from the belief these scientists did the best they could. McGill is one of the most well established epid teaching& research centers, and we cannot assume their code, conduct or conclusions would be wrong without any empirical evidence of such, I therefore do not want to believe in p-hacking, publication bias etc. unless I would have strong evidence of such.
I think we both agree that this is a study that needs replication, but for now the investigators seem to have done a thorough job, it is for the community out there to demonstrate they did not, and demonstrate the opposite in a Popperian manner (empirical falsification), but this needs to be based on evidence and not on assumptions or just beliefs coming from differences in community and principles. Until that evidence is there I personally believe we need to be cautious in jumping to conclusions and give the benefit of the doubt. It would be great if the OHDSI community can generate evidence, and analyse database specific and show the impact of different assumptions.
My concern remains that they show increased lung cancer with increased cumulative duration of ACEIs, but it appears to be compared to ARBs for all time. I am curious how lung cancer risk increases in ARBs as cumulative duration increases. If it rises as quickly, then that would offset the bottom of Table 2. Not clear why they didn’t show that.
Still worth looking into lung cancer, especially with a possible physiological explanation.
Thank you for sharing this interesting paper @jon_duke
@hripcsa made good point.
I don’t want judge this paper but I have concerns, too.
Confounding by Indication
Personally, I prefer ARB for patients with genuine hypertension. But I prescribed ACEI for patients with hypertension and ‘myocardial infarction’ or ‘heart failure’. Because ACEI has much more concrete evidence for MI and HF than ARB (Only some of ARBs are proven to be beneficial in these population. Guidelines also prefer ACEI to ARB in patients with HF or MI). In the baseline demographic table, the proportion of statins is much higher in ACEI group compared to ARB (35.3 % vs 25.5%). They adjusted age, sex, cohort entry year, BMI, smoking status, alcohol, and lung diseases only. They didn’t show how many patients had concomitant cardiovascular disease, such as ischemic heart disease or heart failure.
Imputation of missing values
Authors used multiple imputation for variables with missing values. The exact number of missing values (smoking, BMI) is not shown in paper. The absolute risk difference was so subtle. So we cannot ignore the effect of imputation, either.
Still, it would be worth replicating this study. Korean National claim database has information for smoking status.
Team:
I don’t know whether ACE inhibitors increase the risk of lung cancer relative to ARBs, but I do know that’s a question that hasn’t been definitively answered by existing randomized clinical trials, and it’s unlikely in the near future that there will be any direct head-to-head comparisons of ACEs vs. ARBs in any clinical trials that will be sufficiently powered and with adequate follow-up time to provide strong evidence about this question. So, from that perspective, I’m excited by the opportunity for observational database analysis to ‘fill the evidence gap’ by providing reliable evidence through population-level effect estimation to make a causal inference about the comparative safety of these two products. If reliable evidence were generated and the insight was sufficiently compelling (e.g. we were quite confident that one drug class was notably worse than another), then I could imagine a scenario how this evidence could meaningfully inform medical practice by supporting clinicians and patients in making better benefit-risk trade-offs when considering alternative therapies.
To realize this opportunity, however, the entire research community - including all of us in OHDSI, but also all others in epidemiology and statistics and medical informatics- need to develop and empirically evaluate scientific best practices for how to generate reliable evidence from observational data, and we need widespread adoption and adherence to those best practices so that any new evidence can be objectively assessed to determine the degree of confidence we should have that the evidence is truly reliable (and if you like to think in Bayesian terms, the degree to which the new information generated should shift your prior beliefs into a posterior distribution). If observational data sciences is going to truly move the needle and legitimately impact medical practice, we have to move beyond our current paradigm where study quality is based on qualitative review of some high-level checklist and study results are evaluated subjectively based on expert interpretation of the limited information shared in a publication. We need data to support the use of our data, and evidence that our real-world evidence is worth listening to. @schuemie and @Miriam2 seem to be in agreement that transparency is a core tenet of sound research practice, but to put a finer point on it, transparency is not simply registration of a study, but it should involve the pre-specification of a complete protocol (with fully specified cohort definitions and analysis design decisions), public sharing of all analysis code, and public disclosure of the full resultset for all stakeholders to review and interpret for themselves. Every study conducted should be accompanied by an empirical evaluation that quantifies the degree to which the unknown question of interest is answerable given the data and methods applied. This includes question-specific study diagnostics, such as quantification of clinical equipoise from the propensity score distribution, evaluation of balance pre- and post-adjustment of all observable baseline covariates. It should also include empirical calibration using negative controls and positive controls to estimate the empirical null distribution representing the residual systematic error and to demonstrate that summary statistics (including confidence intervals and p-values) exhibit nominal operating characteristics (e.g. show that a 95% confidence interval actually has 95% coverage probability, and that only 5% of negative controls falsely generate a statistically significant estimate, evenly distributed above and below the null). I agree with @Miriam2 that use of negative controls is not a definitive proof that all systematic error has been fully accounted for, but I do not think ‘definitive proof’ is the threshold we should be expecting to determine a recommended best practice. Use of negative controls has repeatedly been shown to be a useful diagnostic and has regularly uncovered some residual error that materially impacted the interpretation of study results (see the tremendous example from @jweave17’s presentation at OHDSI Symposium). So I can’t see an argument to discourage the use of negative controls as part of best practice except for the pragmatic reality that ‘its a lot of work to include negative controls in your study if you aren’t using the OHDSI tools’. My retort when I hear this: if you are really want to improve the scientific integrity of your study, then either do the extra work following your legacy workflow or adopt the OMOP CDM and OHDSI tools and apply this best practice with comparatively little extra effort.
What I do take offense to and strongly disagree with, is any assertion that the quality of observational evidence should be in any way determined by the perception of the ‘expertise’ and ‘credentials’ of the investigator team. Personally, I find this a form of intellectual discrimination, and I think the notion that one could potentially judge the merits of a scientific publication on the basis of the organizational affiliation of the authors is inappropriate and unacceptable. Scientific evidence should be evaluated on the merits of the science, not the perceptions about the scientist. I fully support disclosure of scientist’s conflict of interest, and all studies should report financial support provided for the conduct of studies. But I also think we must disentangle motivation for conducting a given study from the legitimacy of evidence generated given that a study has been conducted. I do not think it is appropriate to consider a study as ‘likely good’ simply because it came from an investigator affiliated with an esteemed academic institution, nor should it be acceptable to discredit a study as ‘likely low quality’ simply because an investigator worked at some lesser-known institution. We shouldn’t be making any assumptions about an individual’s or institution’s code of conduct - good, bad, or indifferent. Anyone who shares an interest in generating reliable evidence from observational data to improve health of patients is welcome and encouraged to participate in OHDSI. If our field of observational healthcare data analysis is ever to be regarded as a legitimate science across disciplines and the medical practice, we need to become objectively grounded in empirical evidence that allows for fully transparent and verifiable repeatability, reproducibility, replicability, generalizability, robustness and calibration.
In my opinion, the LEGEND-hypertension study that @schuemie and @msuchard presented at the OHDSI Symposium a couple weeks ago is a MAJOR step forward to demonstrating and empirically evaluating an objective process for evidence generation and dissemination. They showed that the ‘learning healthcare system’ they created produces reliable evidence at scale, by systematically and consistently applying a best practice analytical approach commonly used throughout the epidemiology community (e.g. propensity-score adjusted new user comparative cohort design) and following Hernan and Robins’ recommendations of trying to emulate a target trial to answer the specific causal research questions of interest, and transparently applying that analysis across all pairwise comparisons of first-line antihypertensive regimens (both at ingredient and class-level, both mono- and combination therapy) for a large panel of 58 clinical outcomes of interest (e.g. effectiveness outcomes, like myocardial infarction, stroke, and heart failure, as well as safety outcomes, like angioedema, cough, renal failure, hyperkalemia, and gout). They showed macro-level diagnostics for LEGEND, empirically demonstrating that the evidence generated does not fall victim to the publication bias and p-hacking that we been shown to be rampant in the existing medical literature, and also highlighting that LEGEND produced effective estimates that were concordant with the randomized trial meta-analyses in 28 of 30 evaluations that could be performed. They also show the power of OHDSI large-scale analytics network approach, because not only have they generated population-level effect estimates within databases that are temporally aligned and fully inclusive of the uncertainty- due to both random and systematic error that has been observable- within any given database, thereby covering the ‘strength of association’ viewpoint of the Bradford-Hill causal considerations, but also showing the value of adding the ‘consistency’ viewpoint from Bradford-Hill in two dimensions: consistency across databases (e.g. data from claims and EHRs, data from US, Europe, and Asia), and consistency across methods (e.g. propensity score matching vs. stratification, on-treatment vs. intent-to-treat). LEGEND also allows for examination of ‘specificity’ (is a purported effect only observed in a particular context?), and ‘temporality’ (when does the outcome co-occur relative to exposure?). There is still a lot more we all can learn and apply from Bradford-Hill’s 1965 sermon on causality, and I’m confident that other causal viewpoints can be systematically evaluated if we all work together to evolve a common scientific best practice.
The LEGEND-Hypertension study did not examine lung cancer as an outcome, so cannot provide direct evidence to support or refute the findings by Hicks et al. But the LEGEND study did examine incidence of all malignant neoplasms; the random-effects meta-analysis across 8 databases that compared new users of monotherapy ACE inhibitors vs. new users of monotherapy Angiotensin Receptor Blockers yielded a calibrated estimate of 0.99 (0.86-1.16) in the on-treatment analysis, and a calibrated hazard ratio of 1.00 (0.90-1.13) in the intent-to-treat analysis. The LEGEND analysis was based on >2,100,000 new users of ACEis and >600,000 new users of ARBs, so likely represents the most comprehensive comparative assessment of cancer risk ever conducted for these two hypertensive agents. The LEGEND estimates are supported by passed diagnostics for clinical equipoise, covariate balance, and systematic error calibration across each of the databases and across the various analysis design variants. Since the LEGEND analyses were a priori specified and remain fully verifiable in the publicly-available source code, our results cannot be legitimately criticized as posthoc or cherry-picked arguments to support or refute any other published findings, but rather fall firmly within the broader fabric of collective evidence we sought to generate to provide a more holistic picture of the comparative benefit-risk profile of antihypertensive therapies.
So I don’t know whether ACE inhibitors increase the risk of lung cancer relative to ARBs. But because of LEGEND, I do know that our OHDSI network does not demonstrate any evidence to suggest that ACE inhibitors may increase the risk of malignant neoplasms relative to ARBs - not in US, not in Germany, not in Japan, not in Korea, not in claims data, not in EHR data. Moreover, the LEGEND analysis bounds that uncertainty such that we can comfortably believe that any increased risk, if present, is unlikely to be greater than 16%. If a similar level of analytic rigor were to be performed on the unknown question of lung cancer risk, I believe observational data could meaningfully contribute to our understanding of the effects of these medical products and potentially inform therapeutic decision-making. In absence of following these best practices, I think we can neither conclude there is or there isn’t an effect, but unsatisfactorily must settle with ‘we still don’t know’.
The single most important thing that can help OHDSI right now is open debate, both about OHDSI’s methods and about what OHDSI believes about other methods. As an OHDSI forum, the discussion will be one-sided, but I very much encourage continued discussion from all sides. And I thank those for speaking up where OHDSI has no clothes (or no software in the case of broken links, but more importantly on the core issues). So thank you, Miriam. Please don’t stop.
On reputation, yes of course research group will inform your priors, like it or not and admit it or not. And not doing so would be throwing away information. But I do agree that reputation should never become a formal criterion to judge a study or else it the field becomes stagnant. (And I am not sure the field has not become stagnant. Given the availability and access to data, and CPU cycles, and modern analytic solutions, and better understanding of causality, it does seem that this particular paper could have been done many years ago. The state of the art has not moved that much.)
Even if negative controls are not proven yet, I can’t imagine not also trying skin cancer and bladder cancer and sarcomas etc. to see if the same method and database broadly support cancer. And other similar diseases. And also, I can’t imagine not also comparing thiazide diuretics and calcium channel blockers to ARBs to see if they also cause lung cancer. It makes no sense not to do that today. There may be concern about multiple hypotheses, but as long as you register your study ahead of time stating that lung cancer is the primary hypothesis, adding other hypotheses will only help your argument.
Lastly, there just is not enough diagnostic information. The Table shows imbalance in the raw groups, and it remains unclear whether the linear model on a few variables has really balanced the two groups on the important variables. I believe there needs to be better diagnostics.
Note that publication bias and p-hacking are seldom done with nefarious intent, and is no criticism of the integrity of a research group.
Journal editors receive many more papers than they can publish, and tend to prioritize studies showing benefits or harms that may impact medicine over studies that ‘fail’ to show an effect. Unfortunately, this preference introduces publication bias.
I’ve seen many researchers who, when their study produces an unexpected result (often: ‘no effect’), they critically review and perhaps revise their design and/or implementation. When an expected result is produced, people tend to trust the methodology more and be less critical. That in itself already constitutes p-hacking.
These statements and this wonderful thread highlight the community’s genius and potential to rapidly improve observational research. Those proposing innovative methods outside of OHDSI will struggle to find a better space in which to let the data and methods and experts all “speak for themselves”.
You are being too nice today, Martijn. P-value hacking contradicts the idea of a p-value, where you assume random sampling, not peeking at some preferred outcome.
What we need to figure out a way in our methodology is how to answer the question “Are there any nasty effects we should know about?” We ran into that problem when prepping for the LEGEND presentation. We cannot go traditionally, pose a hypothesis (ACE inhibitors cause more cancer than ARBs) and test it, and do that repetitively honest to God for the entire 1.6M combination of things.
Dear Patrick /George/Christian and Martijn
Thank you for responding to this discussion, even if I feel that a small comment has turned into a significant topic, I am happy to take this on
We agree that we do not know now whether ACE-I have increased risk against ARBs for lung cancer and we know there will be no clinical trials which will investigate this head on, subsequent studies will need to show.
We share the excitement of the opportunity of real world evidence to look broader, and we have worked on this and advocated this jointly on many occasions and therefore we do not need to debate this.
Rather I would like to go to the second and third paragraph which is about communities and principles and best practices and the reputation of institutes
OHDSI, ENCePP, ISPE, ISPOR are all in great alignment that best practices are needed to generate reliable evidence from secondary use of health data. OHDSI, ISPOR and ISPE have created best practice guidance, all advocating for posting protocols, and transparency. The ISPE and ISPOR principles have been published jointly ( see Wang SV, Schneeweiss S, Berger ML, Brown J, de Vries F, Douglas I, Gagne JJ, Gini R, Klungel O, Mullins CD, Nguyen MD, Rassen JA, Smeeth L, Sturkenboom M; joint ISPE-ISPOR Special Task Force on Real World Evidence in Health Care Decision Making. Reporting to Improve Reproducibility and Facilitate Validity Assessment for Healthcare Database Studies V1.0. Pharmacoepidemiol Drug Saf. 2017
Sep;26(9):1018-1032). Moreover the RECORD guidance was adopted to a PE version by an ISPE working group which was accepted in BMJ. Whereas you seem to advocate the OHDSI community I feel we all strive for the same thing: transparency, ability to reproduce and also provide and discuss contradictory information if necessary. THERE IS NO DIFFERENCE
Transparency indeed starts by publicly registering a study, which is part of the ENCePP CoC, and available in the EU-PAS registry, it is followed by having detailed statistical analysis plans and registering the results (all according to GVP). The ISPE-ISPOR guidance and RECORD-PE advocate for transparency at the level of making it understandable to the reader what has been done.
Not every reader understand analytical code, so the choice is to either post just all you do, or to make an attempt in explaining to your audience what was done. I see that the ISPE-ISPOR community approach is to make it understandable to the audience and have more details available when needed, whereas the OHDSI approach is JUST to make all code available. I have learned that optimal communication is not to overload and have everybody figure out (which they cannot), but to be able to speak into the ears of the listener. I feel OHDSI can do better there in terms of transparency, if the wish is that all can understand, a translation needs to be made in a way that it is comprehensible, the upcoming RECORD-PE guidance tries to do this.
We seem to disagree on the value of negative controls, I do agree this is a good diagnostic, but would never advise my students to calibrate their p-values, for the reasons provided. Throughout the discussions on propensity scores, disease scores, I have always propagated that these are black box methods, whenever your sample size allows, it would be good to understand what is actually driving the change in estimates, for transparency reasons. Any method amalgamating many different things to my perspective is not transparent, in every study we need to understand what drives the change. That is independent of the OMOP CDM or Sentinel, or study specific CDM
We also disagree on the impact of expertise and credentials of institutions. I would like to argue based on Rothman’s causality theorem: I believe that long term expertise is a necessary factor to do proper studies but not sufficiently so. As in every area, you only become a champion if you are well trained (you need a lot of training to become a Olympic champion), pharmacoepidemiology studies based on health data are difficult and subject to many biases and confounding, I guess we agree. Many papers have been written on this and even brought the area in discredit (especially about beneficial effects). Putting data in the same format and making scripts available makes it more easy to apply a method or available program, by people who do not really understand and not well trained. It really requires knowledge and expertise to know what you are doing for example data science, pharmacology, clinical and epi expertise. We have learned it may go wrong many times, and my perspective is that together as epidemiologists, pharmacists and engineers we can progress the field, transparently but also in an educated and careful manner. I was lucky enough to experience this with great engineers such as Martijn Schuemie and Peter Rijnbeek who taught me a lot and vice versa they also profited from the pharmacology and epidemiology expertise available so we all learned and gained a lot. I personally believe we need to work on the intersections of the fields to progress, nowadays no one should believe he can do it alone, therefore I would plea for OHDSI community to engage and build bridges with the ISPE and ISPOR community an scientists and not judge them.
For example as epidemiologist I do not fully believe in the negative controls, they are a perfect and fancy diagnostic tool, but not the solution to deal with bias and confounding and not transparent, and moreover build on ‘published (p-hacked) data. I am happy to debate and test this further.
I cannot comment on the presentation of the LEGEND study as I was not at the OHDSI symposium, I looked at the presentation I could find on the internet and saw that the question is one that has been addressed several times in the epidemiology community on mono, double and combination therapies for hypertension, this is not new and a difficult area. The online slide set seemed theoretical, and I do not feel capable to comment. Looking at effectiveness of these strategies is very challenging and I feel that the approach presented has many areas for improvement, which go beyond what I would like to discuss here
I general I would like to make the point that I feel that OHDSI can grow by learning from the pharmacoepidemiology community and respecting it, and vice versa. We all have our perspectives, judging each other, or believing a study was done wrongly without proof does not really help, I would prefer as a larger community and being part of multiple communities we are able to be open and ask questions and reflect and look at all perspectives, without jumping to conclusions. That in my perspective is the only way to progress together in a truly transparent manner
Best wishes, Miriam
On the paper, I would say that (if I am right about how they did it) the bottom half of Table 2 about cumulative dose is actually deceptive. And that was the main piece that originally built credibility for me. And failure to try other cancers and other drugs was a lost opportunity. The publication is much less strong than it could have been (if it would have been borne out) and harmful if it turns out to be confounding. So then, one could argue that, based on this publication, the reputation of that group should fall a little, if we are to base our future assessments on reputation.
I agree about better explanations. OHDSI’s LEGEND publication is not written yet, but will need to have good explanations. But I disagree that code should be withheld from readers to protect them from misusing them.
I agree that OHDSI can grow from others but disagree with the phrasing. OHDSI is part of the pharmacoepidemiology community, not outside of it. The publications of its members have been used for decades.
Thank you @Miriam2 for engaging in this conversation. It is still unclear to me why you oppose our use of negative controls. Having lots of experience does not guarantee having an unbiased estimator. Yes, if we think hard we may find theoretical examples of biases not covered by our negative controls. But I have simply seen to many papers published by highly experienced authors where the use of negative controls would have informed them that their design is severely biased. But they didn’t use them (like this paper we’re discussing), so their paper is out there, and readers cannot distinguish these papers from the ones that have little to no bias.
Everyone knows vaccines aren’t 100% effective, and there may be side effects. Yet I still recommend we use them all the time, because the alternative is much worse.
Hi George,
I feel I am misunderstood, so let me try again. the points I was trying to make is that proper education and training is needed to be able to do this work, it is a necessary factor but not a sufficient one. Of course the best methods need to be used and all needs to be done to clarify whether there is bias or residual confounding, which is likely with such a small increase in risk, that is our duty as scientists in the area of public health. I do believe that indeed reputation falls when you have done something obviously wrong, which is also why scientists would not want that in the first place.
The other point I tried to make, is that demonstration that the result in the paper is not correct can only be done by providing the evidence. Not following OHDSI principle does not make the results wrong, OHDSI cannot force scientists in the area to follow its rules. The community should try to refute the results based on transparent science and evidence, and thereby convince other scientists this is the best method. OHDSI transparency principles are great.
I hear you disagree the phrasing on OHDSI and pharmacoepi, I apologize, I know (as being part of the 2 communities) that many OHDSI members are part also of ISPE. I just observe that OHDSI painfully so (to me), does not get the stage it may deserve for example at ISPE. I think what helps is to question why that is, because a better interaction would help a lot to get the OHDSI methods accepted in the area and to move the field forward jointly.
Dear Martijn let me try to explain about the negative controls. The principle of calibration is very nice and well accepted in the analytical field such as chemistry. In that area a benchmark is done where the truth is known.
In the field of health data and observational studies we do not have an actual true negative (where we know the truth), all we know is based on prior studies being, absence of evidence is not the same as evidence of absence, especially not in an area of publication bias. So to start out with, negative controls may not be true negatives actually (exposure needs to accrue for drugs to really get all the issues out, and many drugs have not been studied for all potential outcomes) Subsequently, each drug-outcome association may be plagued by different biases with secondary use of health data, the most well known outcome misclassification, exposure misclassification, Berkson bias, protopathic bias, confounding by indication etc. I have learned that each association has its own characteristics based on local practice, reimbursements, prescribing habits (unfortunately otherwise life would be easy). Taking 100 negative controls (each may be plagued by different amounts of these factors), and calibrating for it, does not do the job for me, it is non-transparent, what drives these associations, and then you would be correcting for something that is not transparent anymore for me. I agree fully with Patrick it is nice diagnostic tool, and it might and could be used if it is easy (which it is with OHDSI tools and CDM), however there are valid alternatives as well, which are to explore the potential biases carefully and report them, each of those can and should be addressed in different ways/different designs, and quantitative bias adjustments can and should be done. I hope this clarifies where I come from, I guess I do not believe you can do this well in a fully automated fashion, it would create erroneous results. What is needed is the tools to rapidly inspect the data, and OHDSI has built great tools for that for which epidemiologists are very grateful, and then careful thought and understanding of what is happening. I believe that is how trust is built, but would welcome others in this conversation
Thanks, Miriam, for the follow up. I agree, and I am curious to see if OHDSI confirms the lung cancer finding, comparing propensity adjustment versus just including the paper’s variables in the outcome model, and looking a little more deeply into cumulative dosing.
One minor point about negative controls. It is not really automated in OHDSI. It remains a laborious process. After using the large-scale knowledge bases to filter out the obvious non-negative ones, there is a committee that goes through the controls one by one looking for plausible connections that would disqualify them. I agree there is so much we don’t understand, so the committee can only do so much, but I don’t want readers of the thread to misunderstand the process. We do still use expert opinion to help hone the list.
In fact, I think it would be interesting to measure the effect of manual honing. Compare distribution of negative effects that come straight out of Laertes (the automated part) versus the final curated list. Where do the filtered ones end up for studies we have already completed. For that matter, compare both of those to a random sample of outcomes that have not been filtered at all.
I’d like to respond to the points raised by Miriam:
Negative controls might not really be negative
I am not worried about this for the following reasons:
Negative controls all have different biases.
That’s why you need so many of them. By having a large sample of possible biases, and showing our design is unbiased for all, we can have increased confidence our design is unbiased for the specific biases for our research question of interest.
We rely on statistics all the time. We often do not know whether and how in one person an exposure causes an outcome. But we perform statistics over many unique individuals to produce population-level estimates, and trust the result anyway. I’m not sure why that wouldn’t apply to many unique exposure-outcome relationships.
Black box analytics are bad
Observational data is fraught with unknowns. Unknowns with respect to chemistry and biology, the health care system, human nature, etc… It represents a highly complex system with feedback and feedforward loops, and thus with unpredictable behavior. In my experience, any mental model we may have of how things work quickly falls apart when you checked against real data.
Take for example the lung cancer paper. Here the author’s expertise informed them that a handful of variables added to the outcome model will be sufficient to correct for confounding. I believe they are deceiving themselves that reality is that simple, but they also did not allow for a way to check their assumptions are correct. A propensity model would have learned the differences between the two exposure groups from the actual data used in the study, rather than assume these are fully known without error. It would also not be a real black box, since a propensity model can be explored. And most importantly, propensity models can be evaluated in their ability to balance covariates.
I guess what I’m trying to say is that black box or not, there are always unknowns and uncertainties. Hick’s et al.'s added BMI to their model, but the mechanisms by which BMI is related to lung cancer are not fully explained. To me, that also constitutes a black box. I would rather rely on a formal evaluation framework that tests whether the study design works than rely on subjective appraisal of the study design and whoever developed it.