dear all,
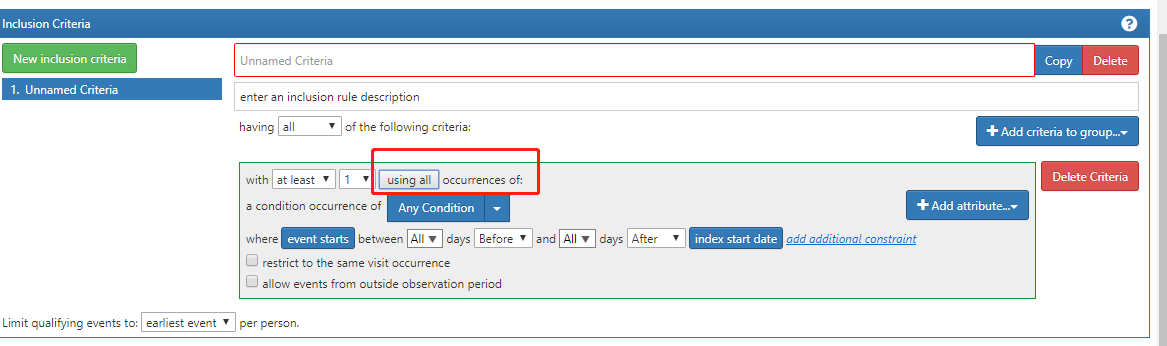
when I use the atlas to construct a cohort, I find I can’t understand the difference between using distinct and using all like the two pictures. what is it?
thank you very much!

2 Likes
Hi @pandamiao,
Let’s assume we have a concept_set with >1 concept_id. And we have 2 patients:
Person A has 3 occurrences of only one concept_id,
Person B has 2 occurrences: once for each concept_id
When ‘using all’ is chosen, then there is no matter how much distinct concepts are found. So there are 3 ‘all’ events for person A and 2 events for person B.
On the other side, when ‘using distinct’ is enabled, then cohort builder is counting how much distinct concepts are met per person.
In this case, we have just 1 ‘distinct’ event for person A, and still 2 events for person B.
Speaking about use cases: it’s often required to find out treatment resistant patients ( and resistance is defined as using >N different drugs of a certain drug group. ) Let’s say we would like to find out patients who used > 3 antidepressants during year.
One way: create separate concept sets for each active ingredient, make a complex Drug exposure criteria for each of them, and combine them into a group with logic ’ having at least 3 of the following criteria’ :
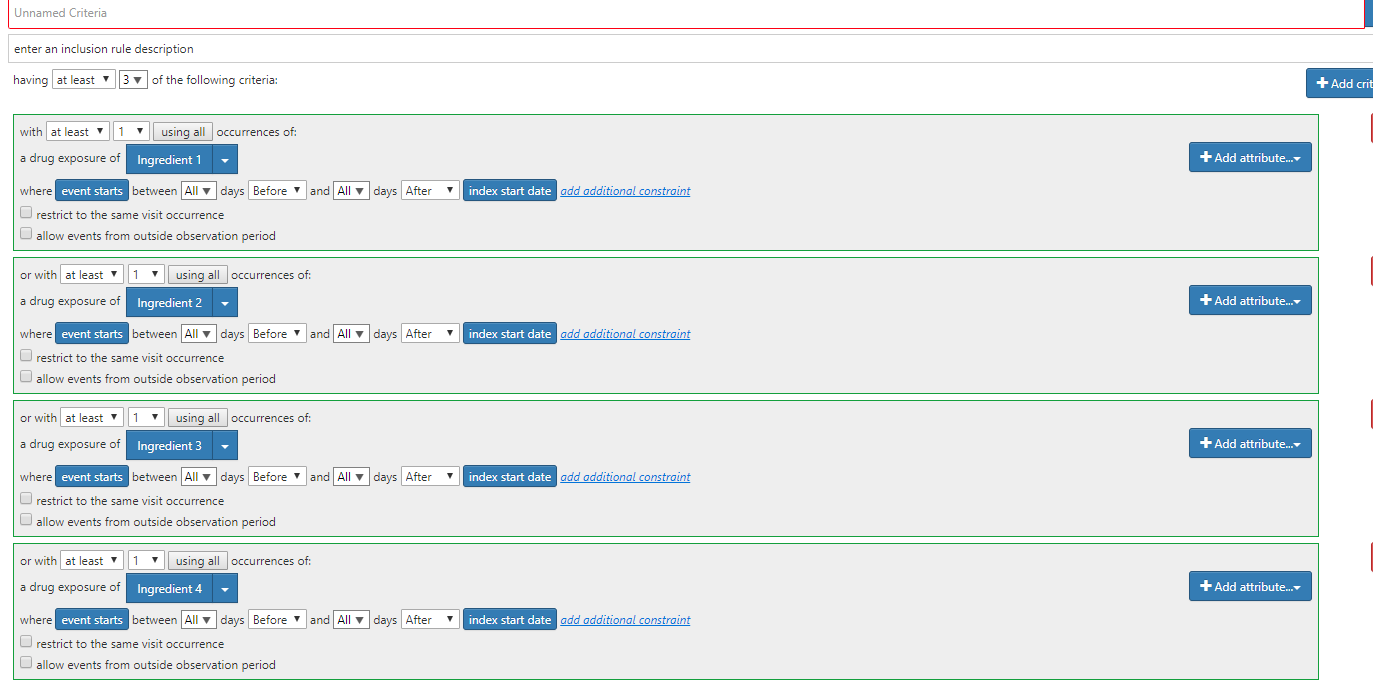
It will take a day to create concept sets, one more day to do the cohort definition. Odd waste of time and coffee ![]()
To avoid this, we can create just one concept set which includes all ingredients and use it in Drug Era criteria, with ‘using distinct’ chosen :

Seems much more efficient.
If dosage also matters, then we can update our cohort to capture different dosages of drugs and use ‘Dose Era’
1 Like
Eldar has explained it well. Thanks @Eldar.
At a more basic level: you have 2 choices of ‘counting things’ when you have your ‘window criteria’ (the type of criteria where you say ‘have at least 1 occurrence of {Condition} Between 30 days before and 0 days before index’.
The first choice is just to just count all the observed events. This is the ‘using all’ option next to ‘with at least N’…
The other choice is to count distinct ‘concept_ids’ from the observed events. This is the ‘using distinct’ option. Each cohort criteria type looks for a specific field in the CDM domain’s table to use for the distinct value: condition uses ‘condition_concept_id’… drug exposure uses ‘drug_concept_id’. visits use ‘visit_concept_id’. I tried to make it consistent but it doesn’t always satisfy all needs. Additional ‘distinct options’ that I’d like to put in:
- Distinct visits (distinct visit_occurrence_id)
- distinct dates (distinct {domain}_start_date ie: distinct condition_start_date)
- Distinct visit dates (distinct visit_start_date of the associated visit).
that will make it easier to do things like ‘at least 3 occurrences on different dates in the past 6 months’.
It’s on the roadmap…but I think this would be useful.
@Chris_Knoll the “on distinct dates” part can be important, so glad to see it is on the roadmap. Duplicates (or things that look like duplicates) can be relatively common, depending on how the ETL is done. In claims data, for example, one can get two records for an infused medication on the same day. One with a modifier and one without. For example there is a modifier for wastage so one might see a record for the amount used and a second record for the amount wasted with the quantities for the two records summing to the amount billed/reimbursed. It happens with chemotherapy a lot, but depends on whether wastage is required to be reported. (We just went through this exercise as part of putting together chemotherapy regimens.)
 thank you very much @Eldar, get it!
thank you very much @Eldar, get it!
yeah, thank you very much @Chris_Knoll, I get what you said, and I also think it is useful.
Hello Everyone,
I came across the below cohort definition in Atlas here. Am just trying to learn Atlas features better. This cohort is to identify people who had ACE/ARB as 1st line drug and CCB as 2nd line drug
From the screenshot below, Am I right to understand that the criteria exactly 1 using distinct standard concept will look for only one concept_id?. A patient might have multiple antihypertensives but he will selected only if he has history of only one concept id (which is a hypt drug from concept set)
If we look at the cohort here, it is basically making sure that person has only ARB/ACEi drug (only one drug from ARB/ACEi - only one concept id) has a history of antihypertensive monotherapy.
I think considering the idea of cohort definition, it shouldn’t be exactly 1 as patients can switch between different drugs under same drug class. So just wanted to confirm my understanding of the Atlas feature before we debug the Atlas cohort definition
Can help me with the below?
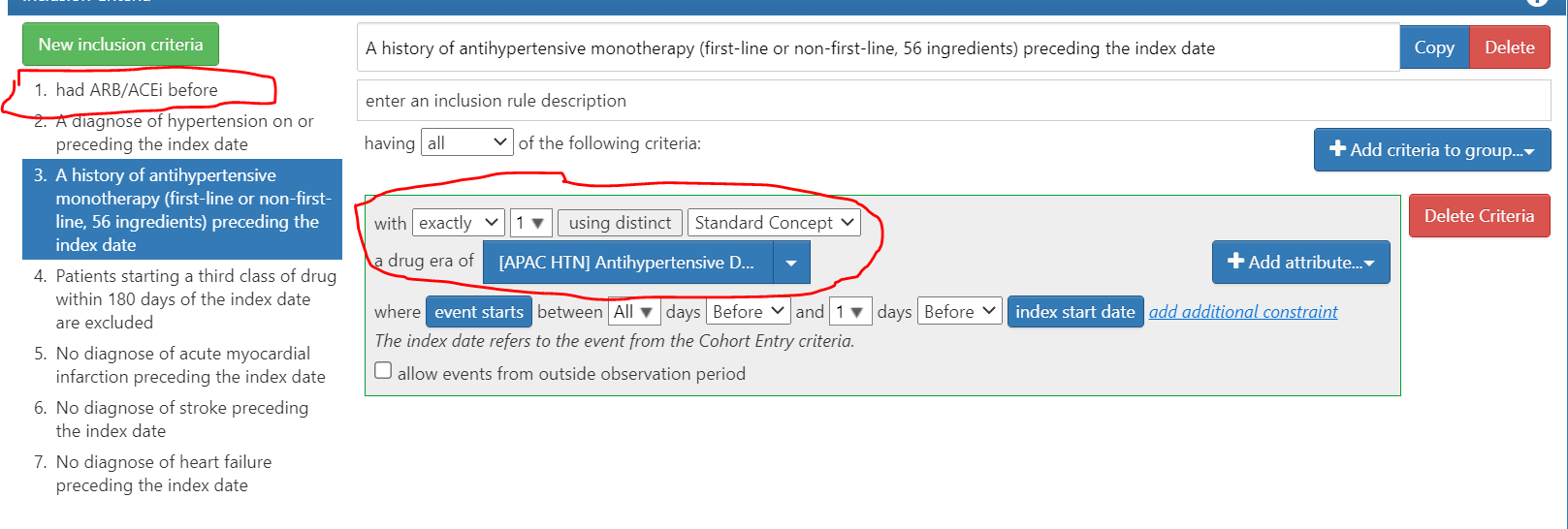
Saying ‘it will look for only one concept_id’ is not exactly accurate phrasing: saying ‘exactly 1 distinct standard concept concept’ means it’s going to look for all records that match the concept set, but the person can only have exactly 1 distinct drug_concept_id in the set of records found. One thing you may not be aware of is that drug_era is rolled-up to ingredient concepts, so different branded drugs map to the same ingredient, making it easier to ask questions like ‘only exposed to exactly 1 ingredient’.
So, if this cohort definition is trying to restrict the cohort inclusion to the point in time the initiated a second ingredient exposure but not a third…) then the inclusion rule works… If the inclusion rule is actually trying to do a 'history of first-line or non-first line) then I think the rule could be updated to look for ‘at least 1 using all records’ instead of ‘exactly 1 using distinct standard concepts’. I don’t know what the cohort definition author was going for, so I can’t tell you what the right answer is.
To your point, if the person was exposed to different ingredients but those would be considered the ‘same line of therapy’ then the above rule wouldn’t work. I think it might be challenging to devise a logical rule where you want to have a concept set determine a particular ‘line of therapy’ and then try to determine the point in time when you are at a first line of therapy vs. a second line of therapy.
1 Like
Thanks for sharing! Looks like the cohort is trying to find people with ARB/ACEi = first line, CCB = second line
The cohort entry is when the person is exposed to CCB for the first time, and the first inclusion criteria,
- Had ACEi/ARB before
makes sure that he was taking ACEi/ARB before the first exposure to CCB
The third inclusion criteria,
- A history of antihypertensive monotherapy (first-line or non-first-line, 56 ingredients) preceding the index date
→ I’m guessing it’s to ensure that no other antihypertensive medication besides ACEi/ARB was being used by having the “exactly one” “standard concept”. However, this would restrict the inclusion to only people who were taking one ingredient under ACEi/ARB, so if a person was taking two ingredients but both were ACEi/ARB (i.e. two separate standard concepts), he would be excluded from this cohort as well.
Agree with @Chris_Knoll - If the intention is to restrict the cohort inclusion to people who were taking exactly one ingredient under the ACEi/ARB class before the CCB exposure, then it is okay. If the intention is to also include those who were taking more than one ACEi/ARB but only that class of medication, then there will be some cases excluded.
1 Like