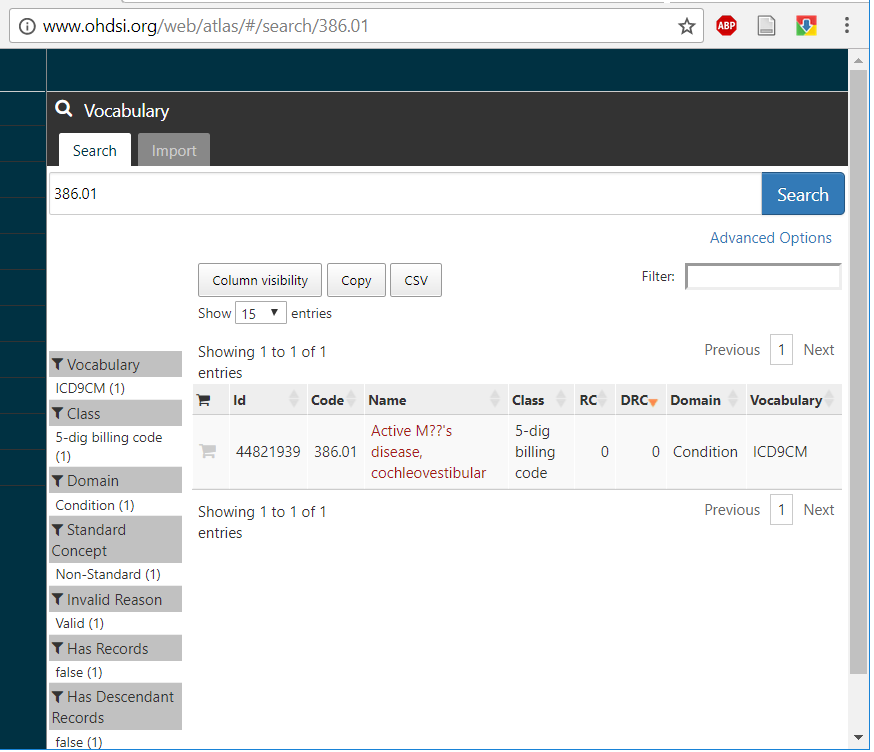
Hi everyone. I’ve done some reading (see this and this) about the decisions for how to handle concept names that use UTF-8 characters. Understanding the lack of support for UTF-8 in some DBMS, it seemed like the concept names were going to be “simplified” to ISO 8859-1. It appears as though characters with diacritics, for example, are just causing errors in the output. The “classic” example of Ménière’s disease can be seen in the public Atlas below:
I was unable to find any clear code that would manage this on the Athena github, though that may be me. I see also there’s a new Athena in development; what might be the best way to approach this?
@Robert_Carroll
Robert - yes, I absolutely agree with a need to transition into UTF encoding. We are planning to add the UTF-8 support in the next release of Athena (2.1), including considering in providing options for a user to choose between UTF-8 (default), UTF-16 and ISO 8859-1.
In this specific example, the encoding was lost when raw data (ICD9CM) was supplied as a text file encoded in ISO 8859-15. We will log this and will make sure to consume ICD9CM data set in UTF format going forward.
@gregk Awesome, thank you for the quick feedback. It’s not an urgent issue, we are working on building some infrastructure and wanted to understand if we were better off using our local labels or what to expect from the vocabulary text. This was helpful, and I’ll keep an eye out for the new Athena release + change in source data.