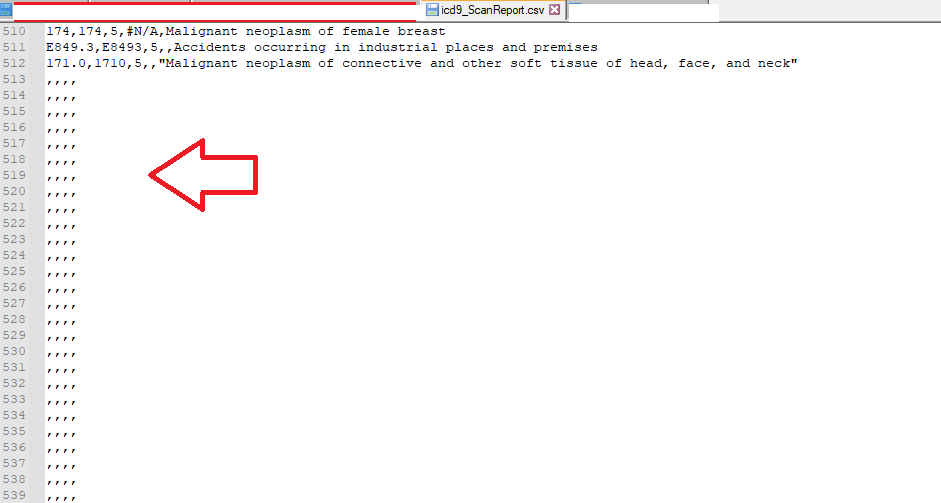
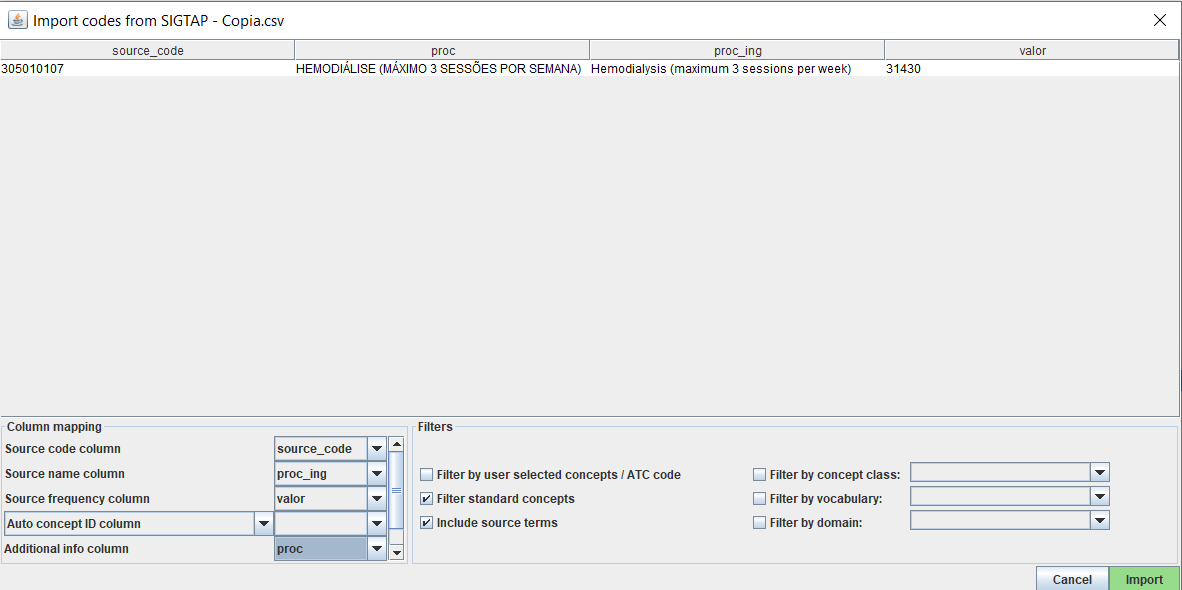
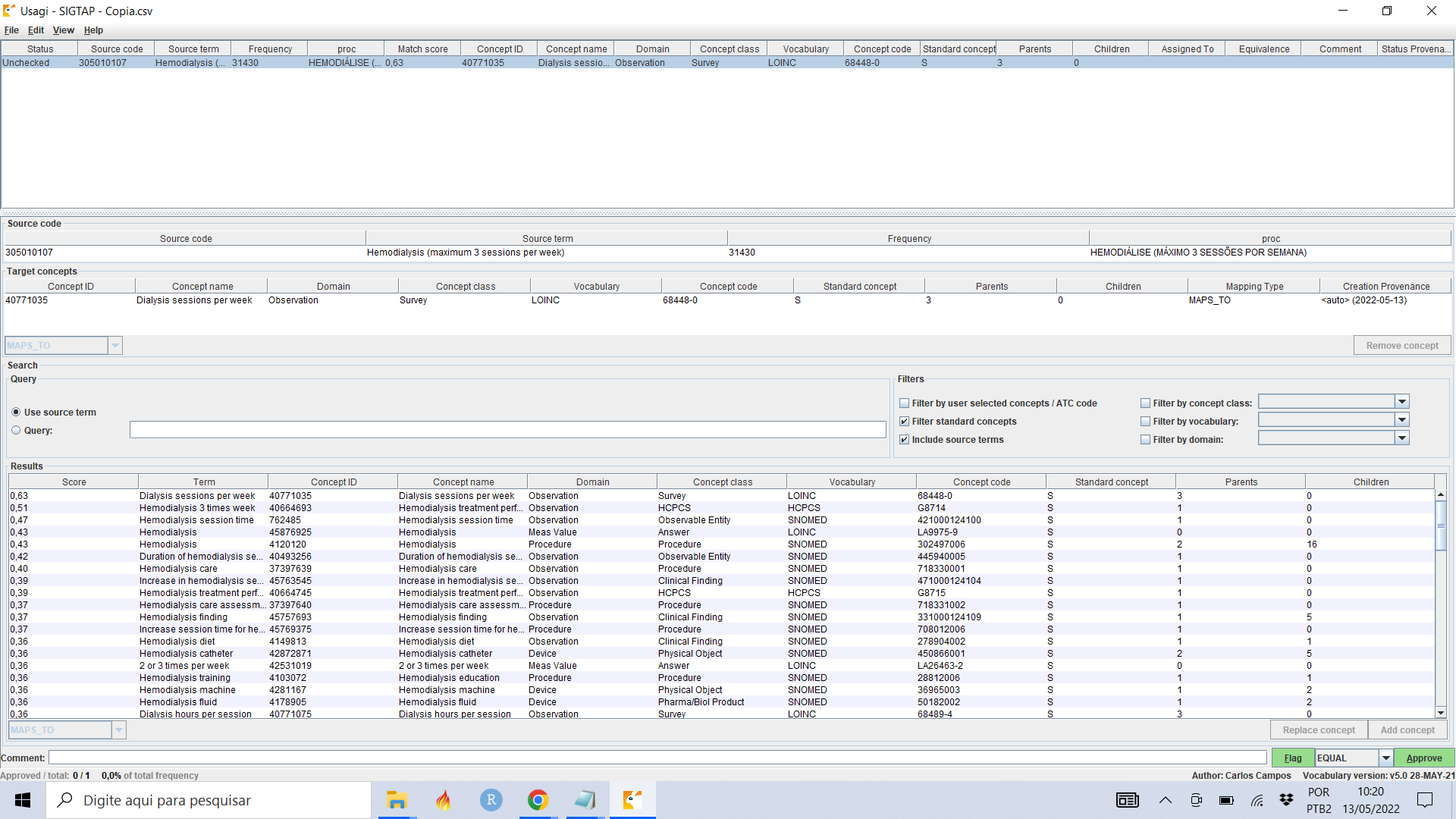
I am attempting to create a mapping with Usagi and getting the following error that is applied to my counts column:
java.lang.NumberFormatException: For Input string: “”
I know it relates to the counts column because I can perform the import if I do not specify a counts column. I have checked and do not believe that there are any blank string values for this column (e.g. I am able to import the file into a dataframe and assign type Int to the column with all rows having a value).
Has anyone run into a similar problem or does anyone have any suggestions?
Solved by deleting last line of the file, unclear why this caused an error, but will leave this thread up in case others run into this problem in the future.
Hi,
We are encountering the same problem.
Have checked deleted rows with symbols that may not be acceptable such as asterixis
Have deleted empty rows
Have deleted rows that are no consistent with what is expected
Can anyone help ?
Robyn
Two things to hint for current and later devs, that is something likely hard to be perfectly fixed
(1) commas of course break your .csv
Check your text columns. Very often there are cases that includes a comma (,) in the text. That is going to break your .csv and render it unreaderable in usagi.
Make sure you replace all the comma (,) with something else
(2) There are cases where whiteRabbit could generate a bunch of lines without text. That would also lead to similar error in Usagi.
Save the file in .csv and open it in something like notepad++, that helps you fix those stupid lines.
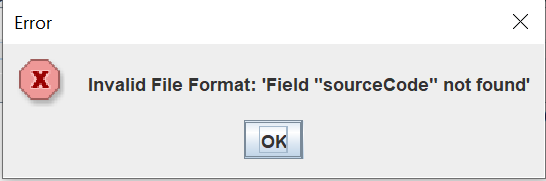
What about an error like the following when trying to apply previous mappings to usagi concepts:
when clearly in the csv file there is the sourceCode field?
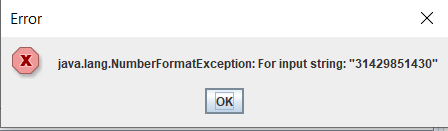
I was having the same problem
Then I decided to divide the frequency column per million and the problem was solved
Aparently the problem was related to length of frequency number
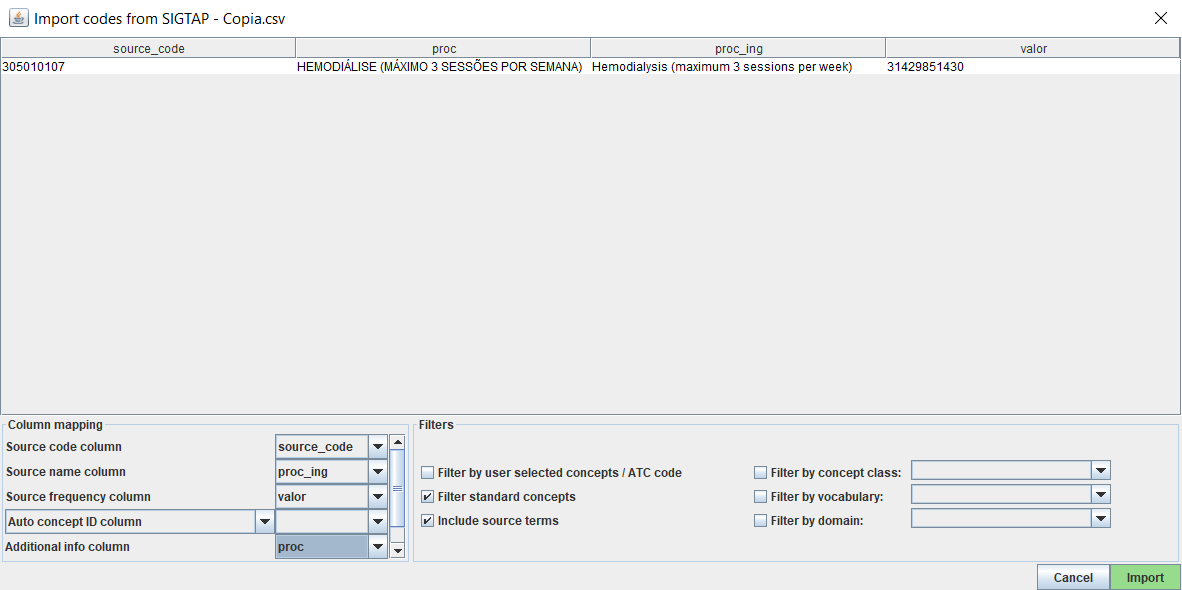
Are you trying to import new source codes?
When I started using Usagi, I had the same problem because I was using the “File → Open” instead “File → Import codes”
The maximum value of a Java integer is 2^31-1 = 2,147,483,647. So indeed the frequency you try to import is too big for this data type. We need to handle this properly. Thanks @carlosalcampos for your detailed report.