The Banda paper on FAERS used USAGI for mapping to concepts and I was inspired to try it on a different dataset.
1. My questions is how long it typically takes for USAGI to produce mappings for 10k rows of data? (my code file had 157k entries) and I had to kill the tool after few hours of waiting.
2. Does it make a difference it Usagi is given 1GB of memory vs. 10GB?
Here is what I did (on windows).
download usagi.jar
get vocabulary files (if you don’t have them) (Athena plain download is fine)
make a folder for Usagi (it will generate index subfolders there)
only now run usagi for the first time
give it more memory via .bat file like this: java -Xmx5000m -jar Usagi_v0.3.3.jar
I’m doing an usagi batch now and it takes about 10 minutes but for only 1k row of data. I selected the top 1k source codes that appear most frequently. 157k rows? It’s going to take a long time
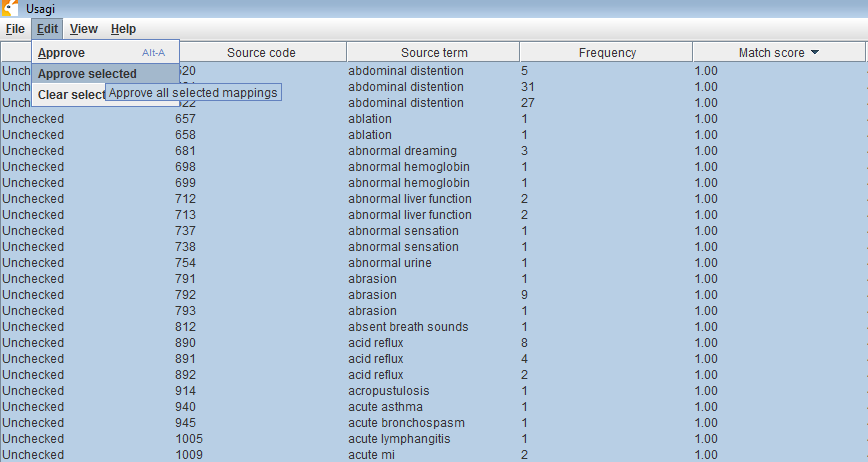
Do you realize that after usagi attempts to map those 157k rows, you’ll need to manually review the 157k rows to ‘agree’ with the mappings that Usagi came up with? So, I’d start with the top 1k codes, work throught hat list and then move on to the next batch until you either run out of money or account for the vast majority of codes you find in your data source.
157k rows is quite a lot, but eventually it will finish (you can let your computer run overnight?). Usagi is performing quite a feat, doing fuzzy string matching between your entry terms and millions of terms in the vocab. Giving it more memory will help a bit, but I’m not expecting much improvement above 5GB.
It helps a lot if you can narrow it down for Usagi. Make sure you filter by domain if possible and perhaps by concept_class_id.
Thank you for reply and some hints.
I did reduce it to 33K in my next try and left the computer overnight. It did finish.
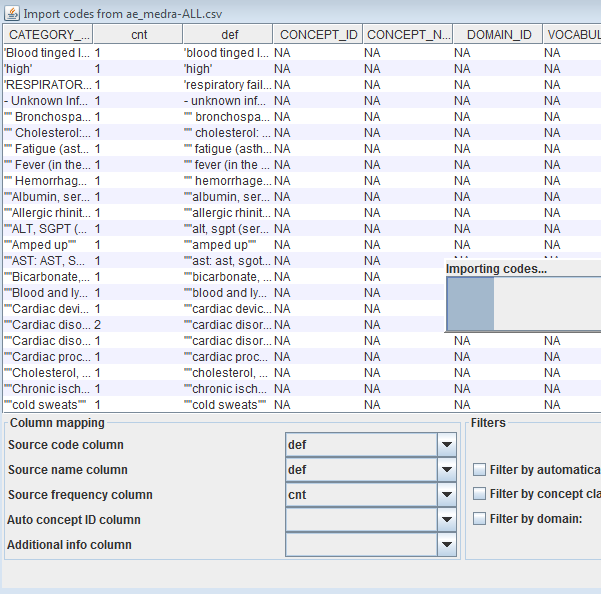
For the sake of others, the batch approve of score=1.0 is what I hope to use in my mapping phase 1.
(ignore the duplicates in the screenshot, that is fixed now).
Interestingly my input data does not have source_code. I had to generate those. I am not sure if Usagi requires them.
@schuemie: Is there a backend script we can run to map free text medication names using USAGI? We have close to a million medication names that we would like to map (we will perform a manual review of a subset afterwards on the file). Is it possible to run a backend script without using the USAGI interface (it is currently too slow and only works for 10k at a time). Any help would be awesome!
Do those medications have separate columns for ingredients/forms/dosages on any kind of standardized name? If yes, I’d suggest use those attributes and run the scripts that are used for OHDSI drug vocabs. Would be more reliable with dosages and ingredients that have similar names, for which we did a lot of manual reviews when we tested USAGI on drugs.
The main issue is running a large set of medications at once - the java program only appears to run for about 10k concepts at a time and it takes about 2 hours to run. If there’s a script that could be run in say R, we may be able to run it on a large server. But the UI for the USAGI doesn’t appear to be amenable to large-scale concept mapping
Yes, Usagi certainly has its limits, and I can’t think of an easy way to scale it. It does use multi-threading, so having more cores available should speed things up.
To Anna’s point: when mapping drugs, the preferred approach is to not import all individual drug codes (e.g. ‘acetaminophen 100mg oral tablet (Aleve)’). Instead, break it up into its separate components. For example, create a list of unique generic names (e.g. ‘acetaminophen’), and map those. I would be surprised if you have > 5,000 of those in your data. Once you’ve mapped all components separately, you can use some logic to put them together to create a much higher quality mapping that what could be achieved if you map each drug code individually.
So basically what you are saying is that before one should use USAGi, the following steps are required a priori:
parsing of drug dosage levels and removal of root drug stem name
mapping of drug stem names to their corresponding generic drug names for all possible ingredients in the drug
use the generic drug names for input into USAGI
Therefore, USAGI doesn’t map raw drug names to the OHDSI terminologies - other systems such as UMLS, etc. would be required first. Is that a correct assessment?
I’m not sure what you mean by ‘drug stem name’, why you would need to do step 2, and where UMLS would come into play, so I’m not sure it is a correct assessment
Do you maybe have 1 or 2 example entries that you’re trying to map? That might make it easier to explain.
@schuemie by ‘drug stem name’ i am referring to the generic names
For example, say I have a drug name:
“seasonique 0.15-0.3”
‘seasonique’ is a brand name and is composed of 2 generic drugs:
levonorgestrel and ethinyl estradiol
By ‘drug stem name’ I was referring to the 2 generic names ‘levonorgestrel’ and ‘ethninyl estradiol’. A terminology is needed to map ‘seasonique’ to the root names, which requires a terminology mapping system such as UMLS.
In an ideal world, ‘seasonique 0.15-0.3’ would be mapped to ‘levonorgestrel 0.15’ and ‘ethninyl estradiol 0.3’ but that is probably too much to ask from most mapping systems. However, I originally thought that USAGI could be used to map drug names such as ‘seasonique’ to the generic names, but it sounds like from the above conversation then that is not possible and that generic names should be used in the mapping.
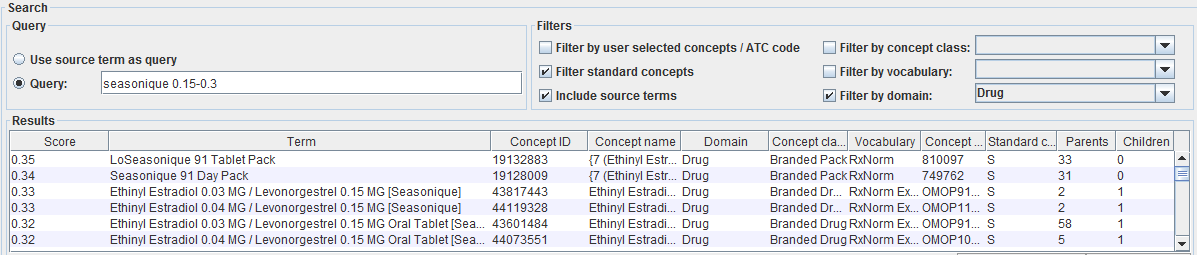
Usagi should have the ability to map the drug name “seasonique 0.15-0.3” to the standard concept name “Ethinyl Estradiol 0.03 MG / Levonorgestrel 0.15 MG Oral Tablet [Seasonique]” but it might help if the units were added to the drug names to be a better match to the numbers 0.15-0.3 to 0.15 MG and 0.3 MG.
If you ran that name through Usagi and limited to the Drug Domain, what matches did you get? I’m not sure if you can limit to specific concept classes (like ‘branded drug’) but if you could, that would also help narrow it down.
Hang on guys. This is not going to work that way. There is no such thing as a “drug name”. There are ingredients and brand names. The brand name is “Seasonique”, the ingredients are “Estradiol” and “Levonorgestrel”, but in some markets it’s just Estradiol. Usagi cannot figure that out.
We do want to automate that and create a smart parser, that can pick up things fairly automatically, including the abbreviated strength. In this case, it is a very steep expectation that the parser will guess that it is the combo product, and the first strength 0.15 belongs to the estradiol and the second 0.3 to levonorgestrel (and not the other way around), and that the unit is mg. Which is funny because that product is not sold in the United States. Where did you get that ugly code from?
We don’t have that yet. In the mean time, you will have to do the parsing and guesswork by hand.
@Mary_Regina_Boland: is the string ‘seasonique 0.15-0.3’ really all you have? Most people have much more structured information available on the drug codes they’re trying to map, like the generic names, drug forms, ATC codes, etc. in separate fields.
Except I am not sure which is the right answer. The third row looks like a good one, except it’s not a US drug, and @Mary_Regina_Boland is unlikely to get one of those. Now what?
Part of the reason I was initially reluctant to provide an example is because I was worried about folks digging too deeply into the particulars of a specific instance…
i have 700k of these ‘ugly codes’ to quote @Christian_Reich and USAGI does not work with more then 10k codes - it crashes, which I believe is a limitation of using Java apps (personally I would prefer an R script that I could let run and then analyze the results afterwards) @schuemie we only have drug names as strings and no additional information, e.g., generic and so forth. Therefore this brings me back to the initial statement I made regarding the practicality of using USAGI:
Drug dosage levels should be parsed first and removed from drug name
mapping of drug names to their corresponding generic drug names for all possible ingredients in the drug (this is especially important for brands where the generic/ingredient names are not provided in the string itself)
use the generic drug names for input into USAGI
If generic drug names are used it is possible we would have around 10k or so and then USAGI would be useable from a practical standpoint.
If there was a user guide with steps required before using USAGI on a large corpus that would be awesome
p.s. @Christian_Reich - not sure why there are non-US drugs in our data, I will be investigating this…