Are there established best practices for “temporarily” adding standard concepts to a local instance of the OMOP Vocabulary (using the >2Bil identifiers) while waiting for them to be incorporated as standard concepts in an official vocabulary release?
We’re looking into methods for temporarily augmenting the list of standard concepts in a local or shared OMOP vocabulary instance so that it can be immediately used amongst a network of CDM sites while proposed changes are processed by the vocabulary maintenance group. To be clear, we are imagining taking a set of source concepts (that should eventually be standard concepts, that an expert has decided has no exact match in the current vocabulary), identifying its context in the vocab (parent concepts, other relationships), assigning a “temporary” standard code (>2bil) and inserting into the concept and concept_relationship table before rebuilding the concept_ancestor table.
As we see it, the benefit of treating the source concepts as standard codes is that they will be included in the concept_ancestor table, whereas non-standard concepts would not be included, and therefore would not be visible to OHDSI tooling (Atlas, etc).
Have others solved this issue using similar or different methods?
We’d like to have a community conversation about this at an upcoming Vocabulary WG meeting, if interest warrants.
I like the idea of a community meeting to discuss this, as I think there may be value in coordinating more centrally within the ohdsi community.
For what it’s worth, I’ll share our experience with our first attempt at using this ‘custom’ 2Bil+ range.
I’ll be interested to hear from others whether we might be overcomplicating it…
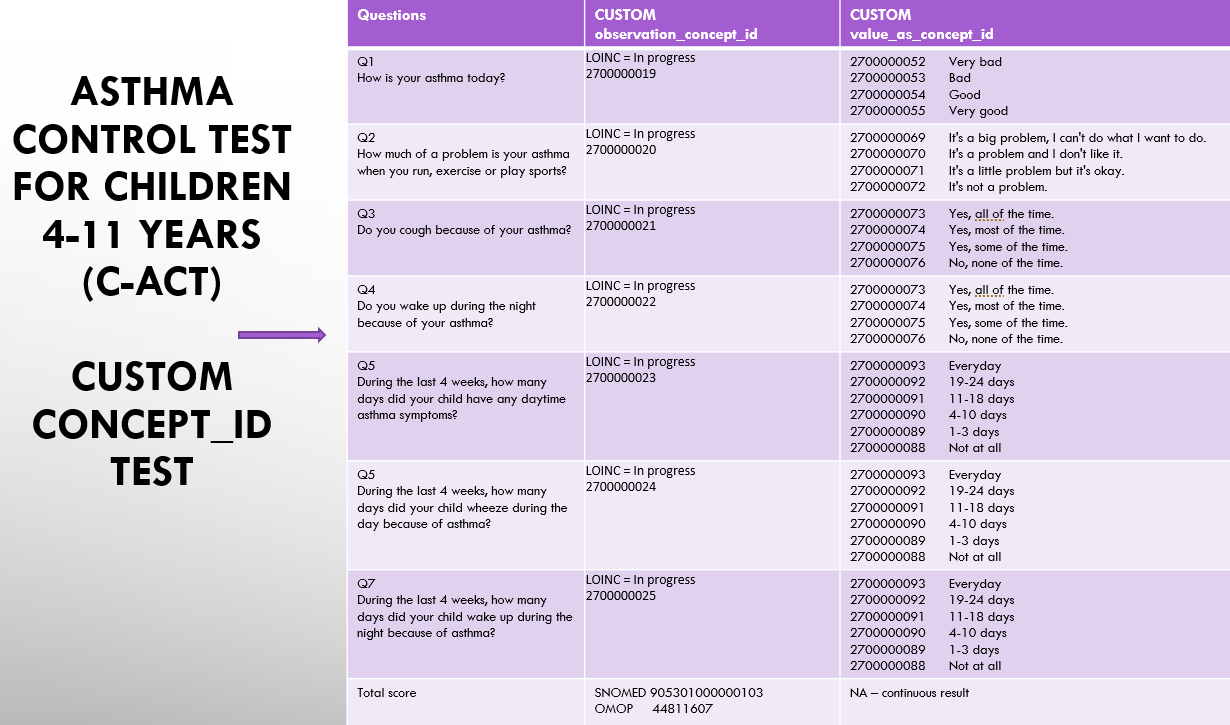
We participate in a state-wide consortium and recently had a Use Case that required extracting data from 5 different asthma assessment scales. OMOP has concepts for the ‘total score’ for 4 of 5 of the scales, but concepts for individual questions for only 2 of 5 (because only 2 of 5 exist in LOINC).
Our solution was to model the asessment scales for submission to LOINC, then to create dummy LOINC codes for each assessment element for which LOINC will create a discrete code: The assessment, the individual questions, the discrete answer lists, the values in each answer list, and the scores.
We assigned a concept id in the ‘custom’ range to each of the dummy LOINC codes for the discrete elements of the assessment. (Note: we didn’t assign a concept id to the answer list identifier b/c that’s never encoded in clinical data, just used to link questions and answers internally in the data).
It was a time consuming process, and I would hate to see multiple organizations duplicating work if the community had a way of collaborating around ‘temporary’ concepts for content that we know many or most sites have and use.
Assessment scales are a big one of course – as there are lots of gaps between what we use in research and clinical care and what exists in LOINC and SNOMED. For published, validated assessment scales used routinely in clinical practice, it might be worth exploring whether ohdsi might reserve a concept id range for the community to share such concepts that ‘under construction’ by SDOs such as LOINC. And of course make these available to the entire ohdsi community rather than each collaborative storing them separately in our local OMOP instances… ?
Great topic indeed! For starters, I’ll share the poster by @MPhilofsky talking about inserting 2bil concepts into concept/concept relationship. This approach helps with visibility of concepts in OHDSI tools.
Rebuilding concept_ancestor is more tricky. Are you thinking about classification terms? And which hierarchy specifically (eg drugs, measurements, procedures)?
I don’t think we should ever mark the custom 2bil concepts standard. That potentially creates a lot of confusion. However, there is no restriction in local networks to share common custom concepts.
From this thread, I see two main topics:
Hierarchy. Can we use of a local modification of the concept_ancestor table for custom concepts? Personally I do not see the issues with mixing standard and custom concepts in this table.
‘Network’ concepts. This might be improved with the new vocabulary community contribution guidelines.. Ideally this makes it easier to add source terminologies to the OMOP vocabulary.
Without knowing your use case, especially the use case for inserting these in the hierarchy, I’m going to advise against it since it is unnecessarily complex.
As @aostropolets stated, creating concepts and concept relationship records for your local codes will allow them to be visible in Atlas and the OHDSI tools. Ensure all sites in your group follow the same process for mapping and adding these codes to the Vocabulary tables. Next, I would create concept sets and cohorts with the custom, non-standard concepts you created and distribute those to site members. And then create the study in Atlas, distribute it and ask folks to return the aggregated results!
You will also need to ensure the SQL logic specifies to map to a standard, when it is available (as your ETL already should). So, creating these as non-standards will allow the ETL to map to the OHDSI standard concepts when they become available in the vocab tables. Thus, it is a temporary solution. Sure, this solution isn’t usable by the broader, OHDSI community. But it doesn’t sound like you are creating a community wide study.
One, I know a lot less about how to use custom cocepts that I thought I did (i.e., I’m pretty sure I’m doing it all wrong right now )
Two, I’m getting the sense from this discussion that use of the custom concept range as a temporary work-around for missing content in standards may have some significant down-sides that we need to weigh seriously against what we hope to gain?
I personally really like the idea @kzollove proposed about a community conversation at an upcoming Vocabulary WG meeting.
We have a whole bunch of standardized assessment instruments with components (questions, answers, scores) that have no industry standard code in any terminology. We are submitting requests to LOINC to have them included. However, we would like to make the data available while we wait for LOINC to build the content.
It looks like non-standard concept ids are allowed in observation_source_concept_id but not in observation_concept_id. I’m unclear whether non-standard concept ids are allowed in value_as_concept_id, but am assuming there are not.
What are the consequences of using a non-standard concept id in a field when no standard concept id exists for the clinical idea of interest?
This is an excellent question. I don’t know all possible consequences of using a non-standard concept_id in a field where a standard concept_id is required. I welcome others input. Consequences I do know: DQD will give you an error, when using the 2 billionaires you won’t be able to collaborate with sites outside your small group using your custom vocabulary, and there is a possibility 2 billionaire concept_id collisions with others you do collaborate with because they are unregulated.
The convention for CDM v5.4 value_as_concept_id field in the Observation table actually doesn’t state whether the concept_id here needs to be standard. This is an omission in the documentation. This field should contain a standard concept_id. I submitted an issue on the CDM GitHub page to add this information.
That the tooling was able to identify and resolve custom concept_id clashes using the custom vocabulary_id name
That the tooling was able to resolve clashes that may result from multiple sties using the same vocabulary_id for custom concepts (using some namespace assignment/recognition mechanism)
This makes a lot of sense. Custom concepts were not designed to be used the way we use standard concepts ids, They were designed for ETL Use Cases (per your poster). Period.
At this point, it sounds that the only feasible solution might be (I’m guessing this is what @kzollove was getting at when he suggested a community meeting) is to
Work with the vocabulary team to add concepts to the OMOP vocabulary
From my perspective
Getting standardized assessment instruments and their components into the OMOP vocabulary seems to be of high priority, as many of these instruments can’t be represented using industry standard concepts
For mental health in particular, these assessment instruments are arguably the only source of truly objective measures we have of mental and behavioral phenomena
What might our next step be in requesting these concepts be added to omop? Would such requests be acceptable and appropriate?
You should discuss this with @aostropolets and the Vocabulary WG. They have a process for adding in source codes to the OMOP vocabularies. And they will be able to best advise you on this unique situation since these source codes will be added by LOINC in the future.
Another thing you might want to consider would be to discuss these standardized assessment instruments with the EHR team at your institution. Once LOINC adds codes for the instruments, the codes will be available for the institutions to use. Incorporating them into the source data would be very useful to all. We definitely need more standardization in EHR data.
Yes, agree. The data needs to be encoded in the EHR at build time.
For existing build, we have a lot to catch up on.
Ideal (future) state is that the codes are requested from LOINC and/or SNOMED when we add new build and discover there’s no industry standard concept available. By the time we have data documented against the new build (or shortly thereafter), the codes would likely be available.
I’m questioning (again) whether it may be a lot of unnecessary work to try to get content added ‘temporarily’ (assuming ‘temporarily’ means 3- 6 months)
We were informed by LOINC (in response to our most request request to add the PHQ-A) that the current (estimated) turn around time on assessments is 130 days.
Depending on when in the LOINC release cycle the codes are built, it will be longer before they are publicly available. Would it be feasible to do the following to reduce the time from submission to LOINC to availability of concepts in OMOP:
OMOP vocabulary team work with LOINC to get the new LOINC codes pushed to them as soon they are finalized (i.e., not have to wait for the public release)
OMOP vocabulary team could then get a jump start on creating omop concept ids?
Or am I again making a lot of erroneous assumptions based on my ignorance of the terminology process in place for omop?
(Apologies if I am)
I’m not sure this is how LOINC operates. At lease, it is not clear to me whether they will be willing to distribute something before the official release where the QA presumably takes place.
Even if they do, processing the files outside of the standard pipelines potentially introduces errors and inconsistencies down the road and leads to more time spent during the release. Same goes for “temporal insertion” on the Vocabularies side - resolving inconsistencies once the LOINC terms are officially published is not a trivial task.
On the other hand, since we have bi-annual releases, it is quite likely that once LOINC introduces the changes in their formal release, we will be able to grab them and insert into the next release. Quite a few moving parts though.
Altogether, it seems that a more viable solution is to add the terms you lack to your instance as 2 billion codes. September 5th Vocab WG call would be a good place to discuss it further