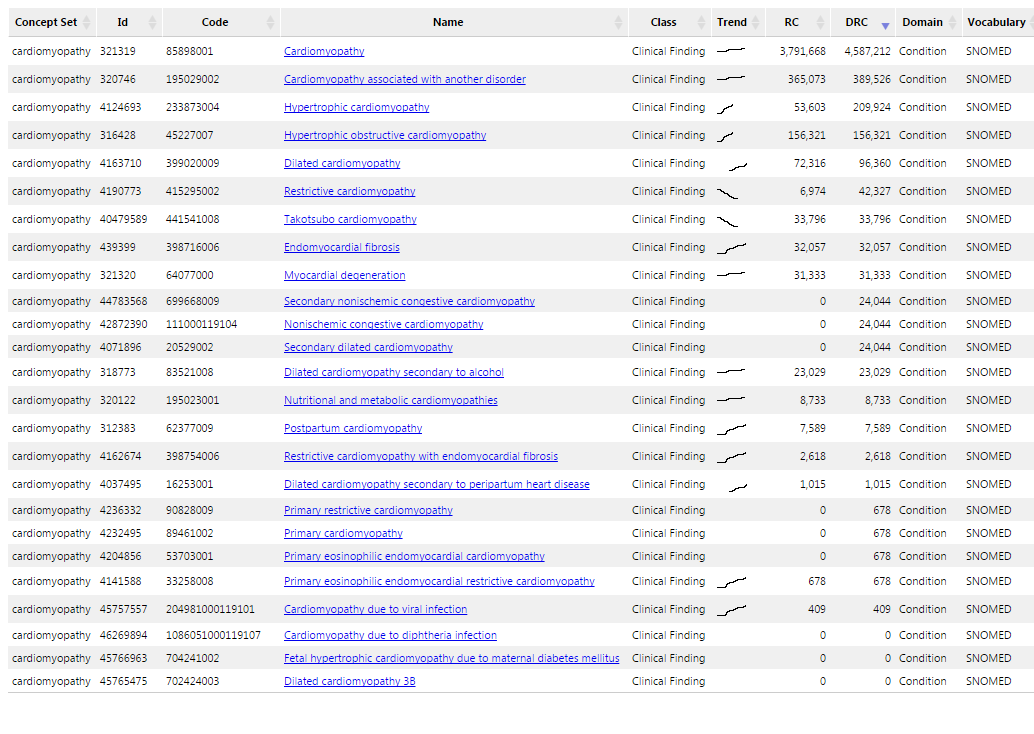
An idea has been raised to include a special ‘concept set diagnostic report’ for a cohort definition which shows the set of included concepts across all concept sets in the definition, with a sparkline indicating the prevalence over time in the data. Below is a screenshot of what that might look like:
The domain of the plot would be normalized across all other plots (ie: 3 plots of data from 2004-2007, 2010-20014 and 2005-2011 would define the overall min domain of 2004 and max domain of 2014. This gives us the plots in the example that seem to start or end in the middle of the plot
The Y axis would be prevalence of records in the given month (RC / # rows for given month or it could be relative to the other values in the result taking the min/max of all RCs and then converting it to a percentage overall).
Some questions:
Where would a report like this fit into the existing UI?
How do we handle the case where there’s a row with RC = 3.8M and another with RC = 409, where the 3.8M will completely obscure the trend of the RC = 409? Should the Y axis for each sparkline be independent, while the X axis is normalized across?
Where should these trends be sourced from? Should a results schema be loaded into the vocabulary datasource, or should it fetch the trend lines using a specific source (RCs are fetched this way currently, but it leads to timeouts under certain circumstances)
I think this could be very helpful! Some comments:
I think the y-axis should be concept density (concept count divided by number of people being observed), not absolute concept count.
Yes, the y scale should be independent between sparklines, since we’re interested in trends. We don’t want to compare the height of two sparklines. You can look at the RC for that.
For those that have multiple databases, it is essential that you can flip through different databases. Just because a concept looks good in one database doesn’t mean it will look good in another. That is exactly what we need the sparklines for in the first place, to detect changes in coding practice in a specific context (e.g. country).
Could we have the sparklines be a bit bigger? Also, zooming in on a sparkline at mouse-over might help.
I think this type of trend analysis would be excellent. I agree with @schuemie’s comments.
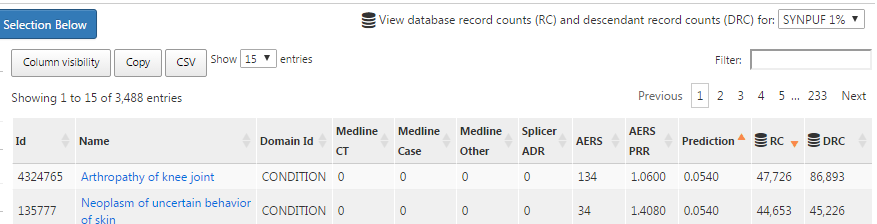
To add a few thoughts: it would be desirable to provide the ability to select the data source in the context of reviewing the record count (RC) and descendant record count (DRC). I did something along these lines for the “Explore Evidence” (aka Negative Controls) functionality:
The drop down above the results allows you to select an available data source and it will dynamically update the RC/DRC columns. @Frank and I had some brief discussion about adding this functionality in the vocabulary search results (or anywhere when you are viewing concepts I suppose). I’d also like to see us keep track of the last data source that was selected so that users don’t have to change it once set.
In terms of the UI, I could see this being part of the concept set interface under “included concepts”
Thanks for the comments. I’ll take @schuemie’s advice and leave the Y axis independent but normalize the X axis so that you can see how concepts come and go with respect to each other (ideally you’d want to have a concept set expression with the same longitudinal coverage). The sparkles were small to just fit in line with the surrounding text, I think it would be possible to have a click event on it that if you click it you’ll get a full sized view of the data. But the important note about the lines isn’t to get actual values out of it just understand the presence in the data over time.
Per @anthonysena’s comments, I like the idea of a data source chooser , and maybe it can be bundled into all of the concept views. A longer running task of mine is to have all of these data-tables support server-side paging (because the UI crawls when we have a broad drug concept set expression and it pulls down 50,000+ concepts of NDCs. So, whatever we do here I’m hoping that it’s compatable with server-side paging support.
Server side paging is something that I am looking at also in the context of the Achilles WebAPI integration–so I should make sure that whatever I implement will be compatible with your implementation.
Also, concerning the overall proposal, I like it It makes me think of if it would me useful to the analagous for certain concepts across all concepts sets in a CDM source!
Question: The first line (cardiomyopathy) includes the next 6, because they are children. Do you worry about that fact? Why would I look at a trend at, say, 7000 restrictive cardiomyopathy if they are inside the 3M cardiomyopathies?
Because you might want to see how the children trend over time compared to the parent. These trend lines are completely made up but you might see something where a parent concept trend line drops off as the child concepts begin to be used more and pick up some of the prevalence.
Also, I should note that the example was from a concept set where everything is Cardiomyopathy, but this is something that could be used to show ingredients in a class, or even just the results of a simple text search in the vocabulary.
I should also clarify that the prevalence trends is for the specific codes (which is why you’d only see trend lines where RC > 0). In the cases of parents and children, there’s no roll-up of counts by month for all concepts beneath a parent. each of those trend lines is how the data is mapped to those concepts over time.
 It makes me think of if it would me useful to the analagous for certain concepts across all concepts sets in a CDM source!
It makes me think of if it would me useful to the analagous for certain concepts across all concepts sets in a CDM source!