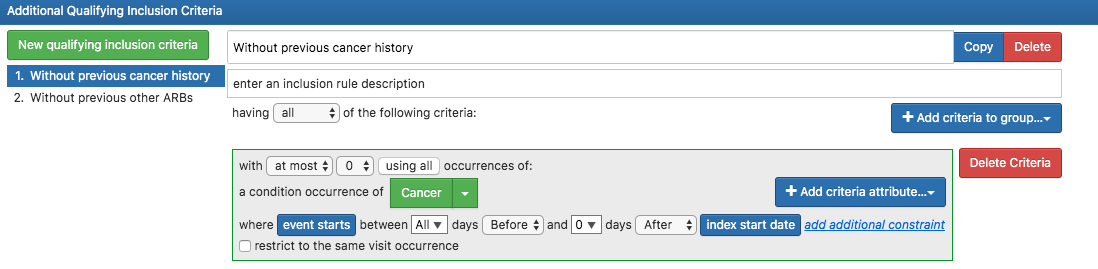
How is the value entered in ‘person’ calculated?
My cohort(‘thyoid cancer_target’) was 2,536. Why is it different?
I think the number of cohorts I made is entered in ‘Person’, but I wonder why the difference is 11 people.
Person is calculated by the number of people in the cohort - anyone who had the outcome prior to cohort entry. The difference is the number of people who had prior outcome.
I have question regarding the persons in incidence rate.
What I’ve understand from your answer above, the number of people in cohort and person in incidence rate should be the same if I add the conditions ‘without any previous outcome history’ in target or comparator cohort.
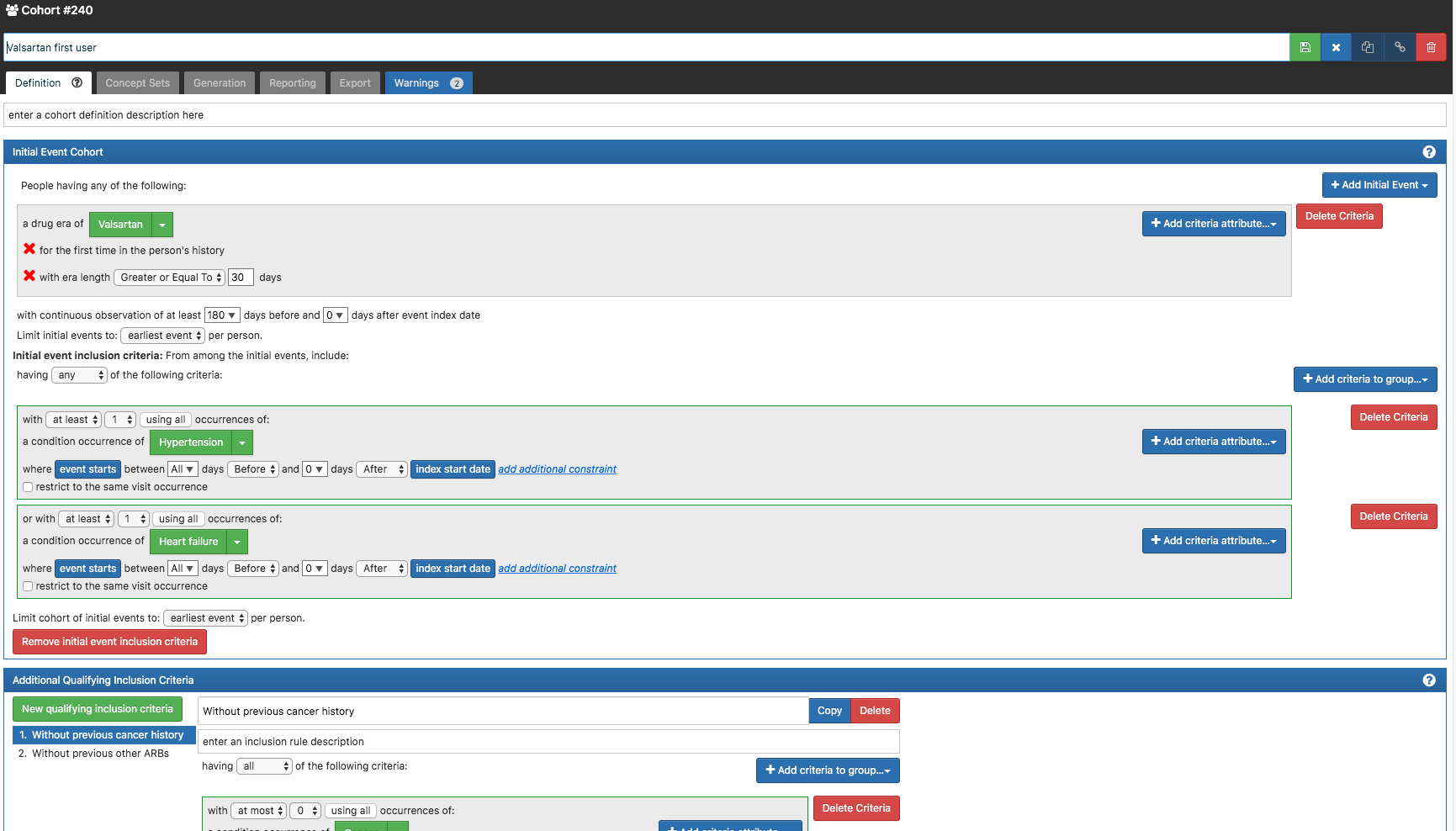
I have add exclusion criteria - exclude person who had cancer(outcome) before the index start date
Even though, I add that exclusion criteria I am getting different number with people in cohort and person in incidence rate.
I have 1282 people in target cohort and 1280 persons in incidence rate.
Can you kindly explain why I am getting difference in numbers even if I add exclusion criteria?
I’ve set the time at risk ‘ends with start date plus 1095 days.’
What kind of conditions affecting the difference with people in cohort and person in incidence rate?
One possiblity is that the person entered the cohort on the last day of their observation period. If their cohort_start = observation_period_end, then they have 0 days in the cohort, and we don’t allow that. In order to be in the incidence rate calculation, you must have at least 1 day of follow up (otherwise you get cases / 0 time, which is NaN).
You could check your cohort to see if anyone has a cohort_start_date = the observation_period_end_date, which will appear in the cohort table as the cohort_start_date = cohort_end_date (because we censor cohort episodes at the observation period end date).
I am working with Hyeyeon at EvidNet and I checked if there are any subjects in the cohort that have cohort_start_date = cohort_end_date. However, the query returned 0 rows.
The @cohortInserts is populated by the program to do a UNION of select N as cohort_id, 0/1 as isOutcome so that we can do a cross-product of all cohorts to all outcomes. You don’t need to do anything with this unless you want to execute the query directly.
But, I’ll call your attention to the WHERE clause:
where (o.cohort_start_date is null or o.cohort_start_date > t.adjusted_start_date)
and t.adjusted_start_date < t.adjusted_end_date
and t.adjusted_start_date between op.observation_period_start_date and op.observation_period_end_date
@cohortDataFilter
The @cohortDataFilter is set to remove cohort records that are outside the study window start/end date (but you didn’t specify a study window, so ignore that). The other parts of the WHERE clause are removing cohort records that already had the outcome, or if the adjusted start date was pushed past the adjusted end date (which, in your case, shouldn’t happen either because you are going from cohort_start + 0 to cohort_start + 1095. So, I’m not exactly sure what is causing your specific loss of the 2 people, but, if you spit the referenced query apart, you might find the cause.
Replace @cohortInserts with the following template:
select 1 as cohort_id, 0 as is_outcome -- this is a Target Cohort
UNION ALL
select 2 as cohort_id, 1 as is_outcome -- this is an Outcome Cohort
-- add more UNION ALLs as necessary
Insert your own cohort IDs in the above query to indicate your T and O cohorts.
Sorry to keep bothering you, I have few more questions.
SELECT cohort_definition_id, subject_id, cohort_start_date, cohort_end_date, @adjustedStart as adjusted_start_date, @adjustedEnd as adjusted_end_date
FROM @temp_database_schema.@cohort_table
If you look at the query above, there is ‘@adjusted start’ and ‘@adjustedEnd’ and I am not sure where you receive the data for those two values.
I assume that those value will change if I do something in ATLAS website, adjust the dates in cohort.
@cohortDataFilter , @EndDateUnions
The query works perfectly fine with them annotated but just wondering what they mean in the query?
Yes, this is set based on user input to specify the Time At Risk start and end date. You have your TAR starting at start_date + 0d and ending at start_date + 1095d
Therefore, you would set the following replacements:
This is Microsoft Sql Server syntax. And, I recognize that adding 0 to a date leaves it the same date for the @adjustedStart expression, but this is what the code is doing, so I’m giving it to you in a ‘literal’ sense.
@cohortDataFilter is only applied when you specify a study start/ study end date window. Since you didn’t, you can just delete @cohortDataFilter from the query.
Finally, @EndDateUnions is used to inject the Study End Date into the set of Time At Risk Ends so that people are right-censored to a study-end date. Since you don’t specify a study window, you can also ignore @EndDateUnions.
With all that, you should have a complete query to generate the IR analysis results, and now you should be able to determine why you are missing 2 people from your cohort. Please let you know what you find, this is quite a mystery!
It is no bother. I’ve failed the community by providing adequate documentation on these tools, so the only option is to ask the question and get the answers here. We hope to fix that in the very near future, but until then, ask all you like.
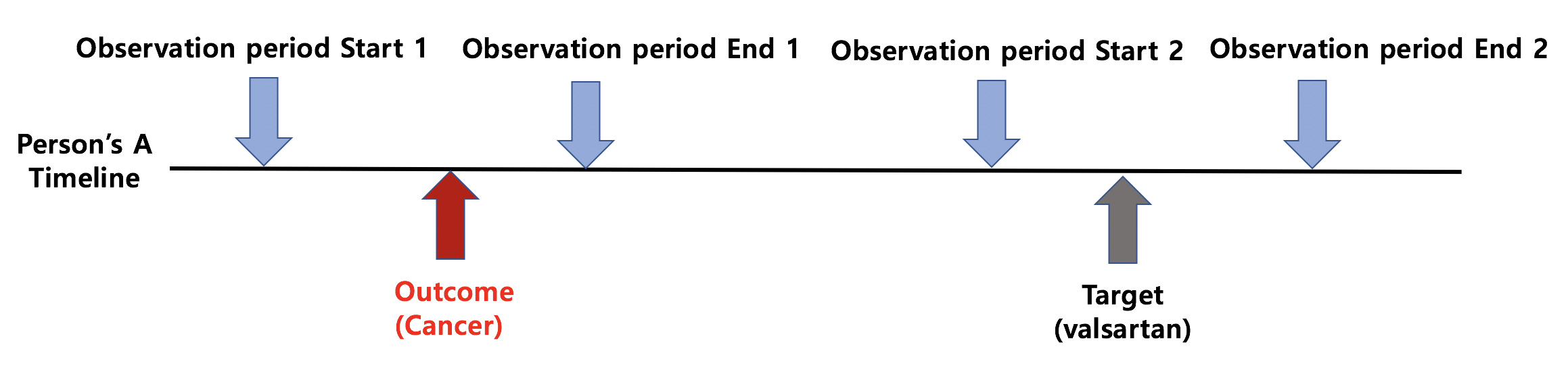
Our team figured it out why we lost 2 people in incidence rate.
For those two people we lost had 2 separate observation period in our database.
So the occurrence of valsartan (Target) and the cancer (outcome) happened in two different observation periods.
Even though we had outcome exclusion criteria in target cohort,
that’s why 2 people were included in cohort and excluded in incidence rate.
Perhaps below image will help you understand better.
I just wanted to add to Hyeyeon’s feedback that the all days before and 0 days after criteria in cohort definitions only seems to cover the observation period in which the cohort belongs in.
For example, in the diagram Heyeon illustrated above, the all days before and 0 days after criteria fails to detect the cancer outcome in person A’s first observation period, hence causing person A to enter the cohort in the second observation period but to be lost in the incidence rate analysis due to prior outcome (as you explained above).
Although this may not be an issue for subjects with only one observation period but for subjects with multiple observation periods, a question remains on whether the “all days before” criteria is really “all days before”.
Nevertheless, thank you very much for your help in figuring this out. We learned a lot!