Hi, @SELVA_MUTHU_KUMARAN,
The person_ids are stored in the {result_schema}.cohort table. There currently isn’t a mechanism to expose person IDs in the application due to sensitivity to exposing patient level data in the UI. However, you can directly select the person_ids as:
select * from {result_schema}.cohort where cohort_definition_id = {cohortId}
Note: the person_id is stored in column subject_id. The reason for this is that there was the idea that you could create cohorts based on other entity identifiers (such as provider ID) so the ‘subject_id’ moniker was chosen to be more abstract.
I have created a cohort in Atlas based on this paper (https://www.ncbi.nlm.nih.gov/pubmed/27923172). Can you let us know whether we have got the inclusion/exclusion criteria right as mentioned in the paper?
You can find the criteria in “Material and Methods” section
Hi, @SELVA_MUTHU_KUMARAN,
I’d definitely solicit feedback from the broader community for suggestions for cohort criteria that can help identify T2DM, renal diseases, etc that are the clinical concepts that are specified in the paper. However, I’ll give you some general, logical things to consider.
The paper sates that it is a prospective cohort study, so they will be collecting data about patients starting from their enrollment in the study and following them for as long as possible. They state that they will drop people that have less than 2 years of follow up. However, you are doing study on already collected data, so you’ll be conducting a ‘retrospective’ study, so, you’ll be approaching the problem of cohort definition from that perspective.
Continuous Observation specification.
You specify that you require 0 days of prior observation, but you have inclusion rules that require 0 occurrences of certain diseases. But if your patient has 0 days of prior observation, how confident can you be that the person in question did not have the disease? Would you need to have the person exist in the data for 6 months? 1 year? 2 years? If you require more prior continuous observation, you will limit your study population, but you will have confidence that your inclusion criteria is based on information that you know. Note: there’s no real reason to require 2 years of prior observation if you are only looking for something in the prior year.
Using the event windows in inclusion criteria
All if your inclusion criteria (that specify a event window) specify ‘events starts between All days before and All days after index’. This means that you’re looking forward in time for the presence of some event. Depending on the study, this could be inappropriate. Since you’re trying to replicate the study, you shouldn’t look for anything in the future: you should model the cohort selection as using anything at the index and prior to make the determination about cohort inclusion. It’s not clear in the study what happens if someone develops an infection, cancer, renal diseases, etc. Do they get censored? Does there data get dropped completely from the analysis? It would be good to hear from the OHDSI community about how those cases are handled. But, you should review your inclusion rules and apply the lookback window that makes sense for the inclusion rules: does a pregnancy 5 years ago exclude them from the study, or just a pregnancy that started within the past 365 days? Does the term ‘active infection’ imply recent diagnosis of an infection (like 60 days) or is it something longer term?
Use of measurements
For me, use of measurement data has always been tricky. if you’re going to use those concepts you should verify that your datasource actually has those concepts in the data, and also check to see what units are associated with the measurement. If you are looking for a value, then i think it makes sense to also specify the unit concept ID in the criteria.
That’s my quick review, hopefully others can contribute some ideas as well. I’m sorry I can’t give you a deep review of the cohort, as these types of activiteis are very time intensive and you need to balance what is required from the prospective context vs. what is actually captured in the data to recreate the study as a retrospective study.
Thanks for the response. I will wait to hear from the community but few quick questions based on your comments and you can let me know whether my understanding is correct or not
Let me clarify better. My aim of this task was only to explore Atlas and see whether we can implement the criteria from real time study in Atlas.
I agree that w.r.t to clinical concepts, i could have added more and it can be improved further. But one thing I would like to get to know/understand from you is whether my understanding of fields are correct
Continuous Observation - From the paper, I am not able to find any info on observation period. So I have kept it as zero. Now that, I have as zero, I believe that all patients with T2DM will be present in the cohort. As we have as zero (which I understand as no restriction/any criteria to be qualified for the cohort. Whoever has got T2DM gets in the cohort. I mean same patient multiple times or unique patients (based on what I choose “Limit Initial events” to be) Am I right? let’s say, we have 100 patients who satisfy this primary event criteria (Cohort entry criteria), So all these 100 unique patients come with their ids and condition start and end date at this stage
Event windows in inclusion criteria - Here now when I apply the inclusion criteria
Pregnant criteria - As we have to exclude patients who are pregnant, we need to look at patients to know whether they are pregnant or not. As we really can’t look back (we didn’t observe them in level 1(primary events)), based on my condition “All days before and All days after Index date”, this is not going to cause any impact anyway. Am I right? I am strictly speaking w.r.t my primary events result. Or do you think it would have been more appropriate to have “0 days before and 0 days after index date” as we don’t really have any records to look back, it is like basically saying, "see whether patients who were diagnosed with T2DM are pregnant. If yes, exclude them for the cohort. This is what I am trying to do. Exclude patients who are pregnant from a group of 100 T2DM patients. I understand your pt about where I shouldn’t look anything into the future but index and prior. In my case there is no prior, my index date becomes the inclusion criteria date (I mean date to check whether patient is pregnant or not).
Another important question is, though I have 0 prior continuous observation in the primary criteria, when I apply “event starts 730 days before and 0 days after index start date” on inclusion criteria, does this help us to look back patient records here by overriding the primary criteria?
For criteria on “Follow up period of 2 years”, can you let me know what is the “event” here? . I mean in pregancy criteria, “being pregnant or not” is the event. Similarly in follow up criteria, what is the event?
I would like to let you know that our observation period dates were derived from min and max of visit occurrence table. When I give “Period duration > 730 days” after selecting “observation period” as criteria as shown below, am I right to understand that it only retains patients (from 100 records) who have observation period duration from observation_period table ((ob.end date - ob.start date) > 730). Let’s say out of 100 patients, 95 patients had their observation period more than 1000 days, 5 who were less than 730 were excluded. So, its the like the subset after filtering our pregnant women will be joined with observation period table to find the observation period duration. IF IT’S > 730 retain else reject it. Is this how it works? But how is the “event starts” condition used here. This is what confuses me.
Atleast 3 measurement of eGFR criteria - I think to address this condition, we should have made sure that our “Limit Initial events” is “All events”, only then we can get multiple records of the same person. With my lookback period as 0 days, can you let me know how to implement this in Atlas?
The paper is doing a prospective study, you are doing a retrospective study. In a prospective study, the people are evaluated if they qualify for the study, and if they qualify, then they are enrolled and followed. In a retrospective study, you look at pre-captured data, and have to look for continuous observation prior to be able to determine if any exclusion events actually happened (you can’t determine if an event did not happen if you do not have prior observation for the patient). From a cohort definition perspective, you are just looking for the population that ‘satisifies study qualification’, which is: they have T2DM, are not pregnant, have no infenxtions/cancer, have no renal disease, etc. you can’t determine that they aren’t pregnant if you don’t have prior observation. So you will need at least 9 months of prior observation so that you can determine that you do not see them pregnant in the past 9 months (worst case scnerio, you have a record of pregnancy the day they got pregnant). You also can’t determine if they are clear of renal disease if you don’t have prior observation. How far back do you need to look to ensure no renal diease? 1 year? then you’ll need a minimum of 365d prior observation.
I’m a little confused about you taking about the ‘same patient multiple times’, but what I’d say related to continuous observation is: if you have a person that enters your data, and on day 3 of their continuous observation they have their T2DM. On day 3 of their continuous observation, you can’t detemrine if they have no renal disease, pregnancy, etc in the past year (you do not have 365d of prior observation on day 3). However, this person may be getting monthly T2DM diagnosis, and after a year of this hapepnign, you will find a T2DM that has 365d or prior observation (maybe on day 425)… It is at this T2DM diagnosis you can confirm that there’s no pregnancy or renal disease, and at that point you can say they qualify for the study. They could have multiple T2DM even after that DX on day 425 but you only really care about the first time the person qualified for the study (on day 425). What will happen by default in the cohort defintion is the 425d DX and all the others that qualify after will be collapsed into a single cohort era taht starts on day 425, and continues until the end of the observation period.
Ok, so you found 100 patients that had the primary event (T2DM), but then you will only include those patients that satisfy all of the inclusion criteria. And, by default, if a person satisfies the inclusion criteria and multiple dates, the final cohort episodes will be from the first qualifiing event up to their observation period end date.
Yes, if you add a inclusion criteria that says the Observation Period must start between all days before and 730 days before the index (the T2DM dx), that is the same thing as requiring 730d of continuous observation, because you are sayign that the observation period must start at least 730 days before the T2DM DX, which means that, if it is true, the person had 730d prior observation. Conversly, you could say that the observation period ENDS 730d after the index date, which means you have 730d of continous observation AFTER. What you put in your inclusion criteria, hwoever, was that the length of the observation period wasy 730d. That is saying somethign different: that is sayign that the duration of continous observation spaned 730d, but it doesn’t say anyting about if that span was before or after the T2DM dx date.
Again, the follow up period is something they specified in their prospective study. When someone enrolled int he study, you don’t know if they are going to be with you 2 years (as you can’t see into the future). Instead, they said that they would drop people if they didn’t make it 2 years in the study (which is a bit odd for me). I suppose that if you wanted to recreate that rule in your retrospective study, you could require that people’s observation period must end between 730d after and all days after the DX date. I just think it’s strange, and more of a characteristic of a prospective study, so I was suggesting you don’t apply that rule. But, if you want to follow it, you can do it.
To answer your question, the ‘event’ to determine ‘follow up’ is the observation period event. You want to require that the observation period ends 730d after the T2Dx date in order to require that the person was continuously observed for at least 730d.
Yes, you understand correctly that when you say period dration > 730d, you are saying datediff(d, observation_start, observation_end) > 730. However, that is not saying that they had 730d of continuous observation following the T2DM diagnosis, it is saying that at the time of the T2DM, there existed a period of at least 730d of continuous observation surrounding the T2DM diagnosis. Since the paper is requiring 730d of foloow up, that means that when you are checking your T2DM diagnosis, you want to see the surrounding observation perioed end between 730d after and all days after the T2DM. that means an observation that ends 730d, 790d, 1024d, 2048d after the T2DM all qualify the T2DM diagnosis, but if the OP ends 60d after the T2dm, then you do not have 730d of follow up.
First part is right: if 5 people didn’t have 730d of post-observation, then they are not included there (note: ALL of their T2DM diagnosis would have to fail this check. If at least 1 T2DM passes, then that T2DM event will be considered. But, then you start talking about pregnant women…but pregnancy is a diffrent inclusion rule. Each inclusion rule is applied independently to the cohort entry events and at the end, we chose the cohort entry events that satisfy all inclsuion rules: entry event in cohort if: (Inclusion 1 = TRUE && Inclsuion 2 = TRUE && Inclusion 3 = TRUE)
Let’s say you ahve a person with multiple T2DM diagosis. Let’s say the first one only had 30d of prior observation, and you require 365d. Let’s say they had another diagnosis on 765d, so they satisfy the inclusion rule related to observation period. But, ut oh! they got pregnant on day 732, so while they had the right prior observation on their 765d diagnosis, they failed the pregnancy check! so, they didn’t meet all the inclusion criteria, so the person is not in the cohort as of day 765. But let’s say they have another diagnosis on day 2750. At this time, there’s no pregnancy within 365d, the have pleanty of prior observation time, they don’t have any renal problems, so, on day 2750, they are in! See how that works? Each inclusion rule makes a different statement about if they qualify, and they ONLY qualify for the cohort on the date, if ALL the inclusion rules pass on that date.
I understand your confusion, but it’s hard for me to put into words: when you say ‘all events per person’ you’re just talking about those cohort entry events (in this case, the T2DM diagnosis events) using ‘all events’ or ‘earliest event’ simply means are you going to allow a person to use multiple T2DM diagnosis events or only their earliest T2DM event for inclusion in the cohort. After you’ve made that decision, the inclusion rules will use all the events that you specify to look for in the inclusion criteria. Meaning: You said use earliest event per person for the T2DM diagnosis. Then you want to look for eGFR measurements. Looking for eGFR measuremetns is not limited to a single event per person. When you create your inclusion rule looking for eGFR, it is going to find all eGFR measurements, and count them up (based on the time window before-after you specify, and other criteria like the concept ID, measurement value, etc). It is going to count up how many it found and that count will be used in the inclusion criteria: do you want at least 1? (that’s an inclusion)…do you want exactly 0? (that is an exlcusion)…do you want at least 3? (that means that the person had 3 measurements taken). What the toold oesn’t do (yet) is let you say 'there was some X increase over the next 3 measurements). You’ll have to do something like ‘had a value in range A-B’ and then a second measurement in range C-D within 90d…which I acknowledge is not the same thing, but it’s a workaround.
Hello @Chris_Knoll - Thanks a ton for your detailed response. Much appreciated
I would like to know whether you have any examples where you have tried/showcased to implement the cohort definitions of a study (article like what I shared) through atlas. That would be helpful to solidify my understanding as well.
@Chris_Knoll - Hello Chris, I was trying to debug the SQL query which was generated for Cohort. Can I know what is the use of “date offset strategy” or temp table called “strategy_ends”?
This is used to specify the cohort_end_date for the cohort entry events that qualified for the cohort. Using the date offset strategy, you can specify that the cohort_end_date is offset by a fixed number of days from either the entry event’s start date or entry event’s end date. For example, you may have a procedure (such as chemotherapy) which you’d like to make a fixed duration for all people, and so you’d set the date offset strategy to add 7 days to the entry event’s start date. Or, maybe you want to specify a 30d surveillance window to cohort entry events based on drug exposures, so you would specify a offset strategy to add 30 days to the entry event’s end date.
strategy_ends temp table
The strategy_ends temp table is used calculate each person’s adjusted exit_date based on the strategy, also taking into account observation period ends. Example, the offset strategy may specify adding 365d to the cohort start date, but a person may only have 128d of post-index continuous observation. The strategy_ends will contain the offset date of event_start + 365d and also the observation_period_end_date that encloses the entry event. Which ever is first for that person will be used. The logic is: if the observation period ends before the date offset, then the person should exit at the observation period end date.
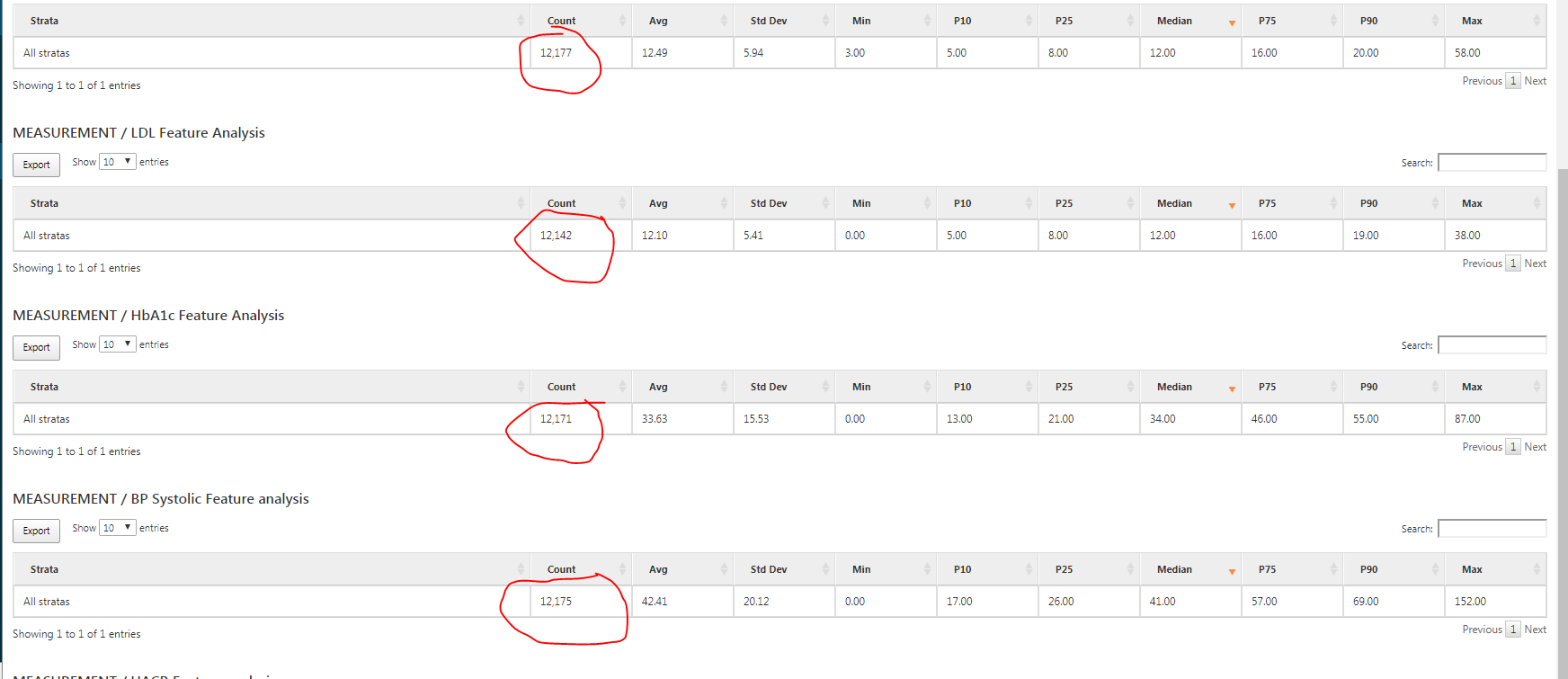
@Chris_Knoll Thank you for the response Chris. In addition, Can you let me know what happens when we generate the custom features for measurement values? I mean Systolic Blood Pressure, eGFR values. When I mean values, I talk about value_as_number field. So when I see the output as below and if they don’t indicate value_as_number field (came to know that from github) , can I know what does this result indicate or how to interpret this? 2 questions
When cohort size is 12177, why do I see different count for different features when we are generating features for the same cohort (which has 12177 records). Ex: LDL has only 12142 records. (Similar post here - Atlas - Issue with Characterization display)
What does Min (0.0) and Max (38.00) indicate in this scenario. We already have count.
I posted in github as well but thought of posting in forum as well for the use of community.
Hi,
Let’s keep the discussion confined to github about the question on characterization. I understand you posted here to get broader view, but this thread is now touching on multiple different issues, and anyone attempting to find information about “Randomized data - Atlas Cohort Generation” is going to get a thread talking about characterizations related to distributed values.
At the very least, a separate thread specific to the characterization of distributions could have been created, just to keep the topics separately. But, if you do start the discussion on github, we should leave the discussion there. I think the forum is a good place to explain the functionality, and github should be a place to report actual issues. In the case of this topic about distributions, I’m not sure there’s an actual issue in code, rather you have a question about what the numbers mean, but you’re raising the question in the context that you think that there is a bug. That’s fine, and it looks like you’ve gotten some information already over on git.
Can you please help me with an issue I’m facing as it seems similar to yours and you probably found the solution.
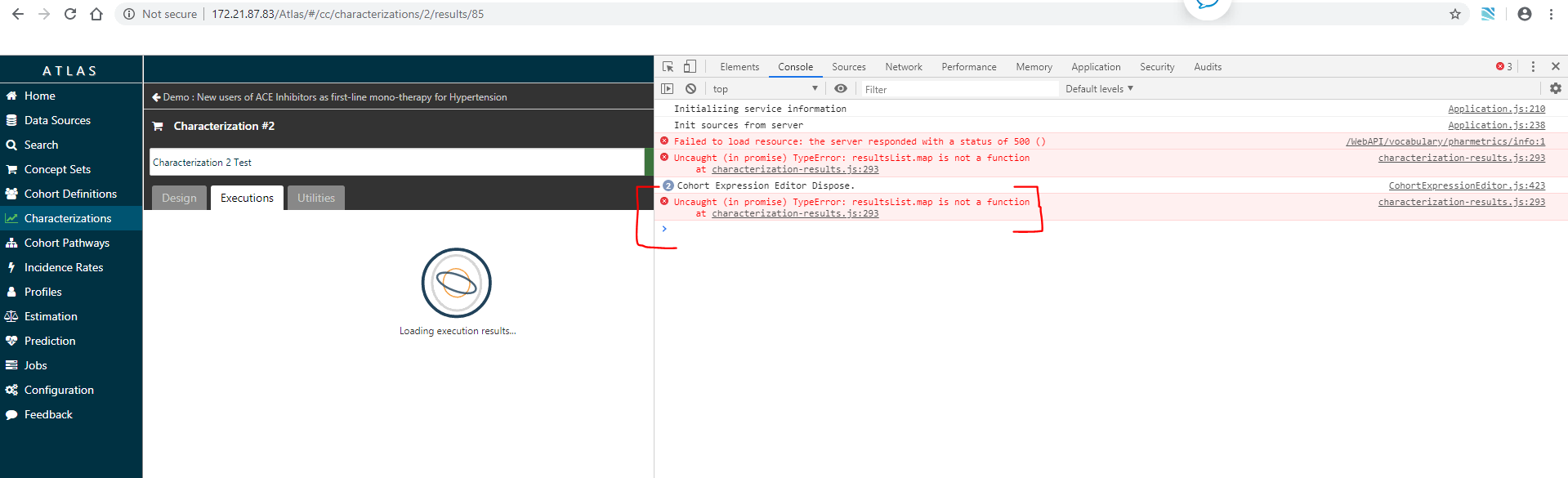
ISSUE : Unable to view report for cohort characterization
I tried generating report for cohort characterization and it successfully generated but when I try to click on view reports then Atlas just keeps loading it forever
I’ve tried the following things :
I’ve looked at the chrome console and I see an error which I’m unable to comprehend(see screenshot below
I’ve tried looking at the network tab within chrome console and I don’t see any error messages there either.
I tried looking at the tomcat localhost_access logs but I dont see any statement with FAILED status over there either.
I’m using Atlas 2.7.4 along with webAPI 2.8.0 since it is backward compatible I dont think there are any issues there.
Lastly there is a table results.cc_results already present in my DB and the records are being inserted there by the cohort characterization job so I dont think that is the problem either.
Any help would be greatly appreciated.
@Chris_Knoll could you please provide your suggestions as well. Thanks in advance !!