Hi, @Adam_Black ,
First let me say: I hear you about the pain points of creating individual O cohorts that are O after T, especially when the T definition is very complicated and makes defining these specialized Os painful.
From an Atlas/WebAPI IR perspective, I don’t think we’re going to be making any changes to it: the next planned change to IR in atlas will be to adopt the functionality in CohortIncidence so that we don’t have these different implementations floating around in our ‘standardized analytics toolbox’.
That being said about Atlas, you are probably OK with doing the work inside the CohortIncidence package. Even tho a new release is pending, you can do what you want today with the current 1.0 release. It will involve a little custom SQL to construct the outcome cohorts that are the first O after T, but it’s not complicated sql to create cohort records based on in a T-O relationship, and you just need to find a way to create a new cohort_id. Here are the steps:
- Copy your cohort records from your atlas results table into a new cohort table which will be used to combine your base target/ cohorts and your derived O cohorts that will only have an O if it appears after a T.
- Execute the sql that generates the cohort records for a given O with a prior T, and assign it a new cohort_id and put it into the cohort table you set up in step 1.
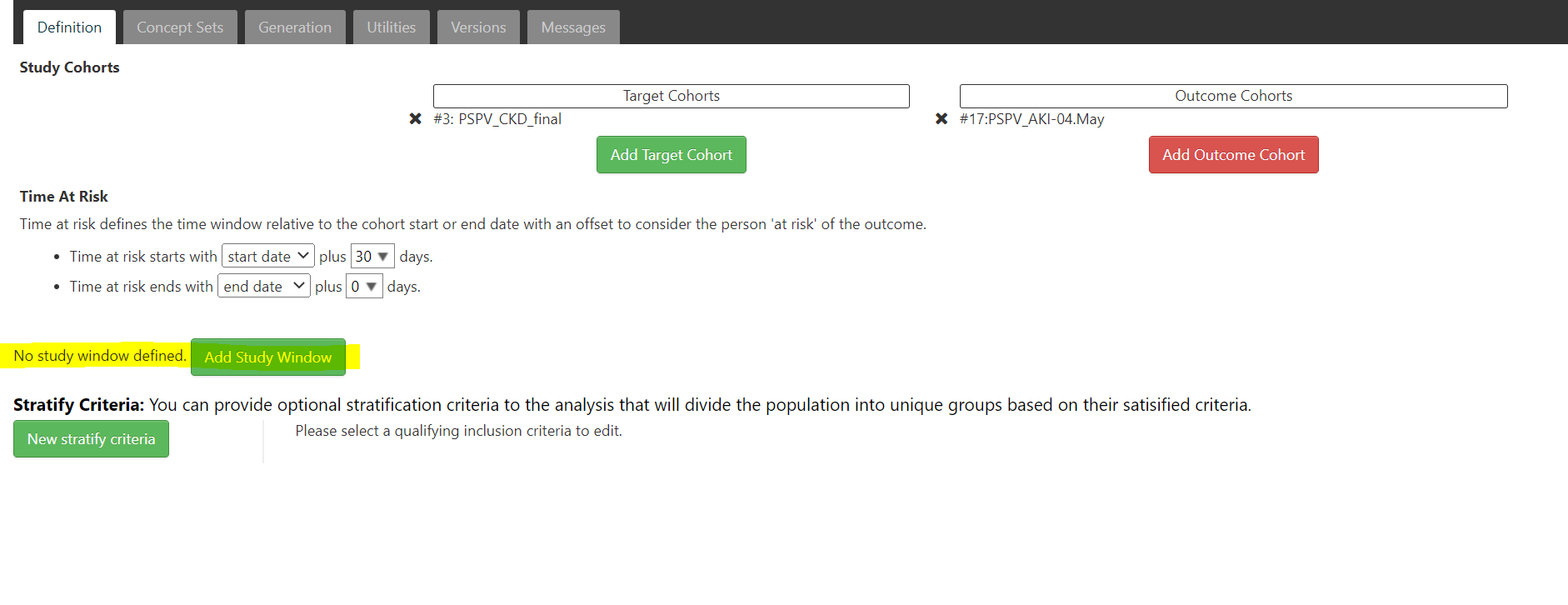
- Put the derived outcome cohort IDs as new outcome definitions in your CohortIncidence design.
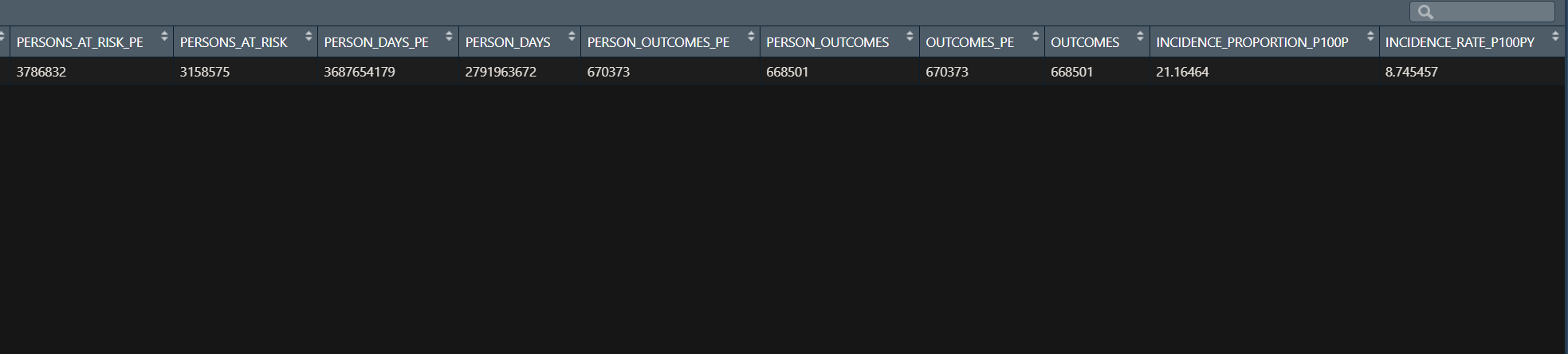
- Run the CohortIncidence package and review the results.
I recommend using the issue-8 branch on CohortIncidence which makes it much easier to execute the package, and the vignette is up to date.
As for the question on the methods, (ie: the why isn’t it reasonable to just follow to the first O and ignore prior T time at risk and ignore post O time at risk?). I think a new topic should be created in the Researchers section of the forums, but I’ll make one point here to think about it:
CohortIncidence was specifically designed to handle the complicated cases such as the below timeline:
|S1| |S2| |S3|
|---------TAR----------| |---------TAR----------|
-------------------------------------------------------------------------
|----IP1----| |---IP2---|
So: TAR begins at surgery, and we can see this patient had 3 surgeries, producing 2 distinct TARs. Note that there was an Outcome IP1 that preceeded the S1, but the IP1 outcome overlapps the start of the first TAR. It’s impossible to see an IP outcmoe inside the IP cohort time so this is called ‘immortal time’, and it shoudl be removed from the TAR because the person is not techinically at risk of an outcome during this period. So: the point is you can’t just ignore prior outcomes.
Secondly, We see that IP2 actually precedes S3 surgery. Should it be ignored because it is a ‘prior to target’? If so, S1 will not show an outcome during it’s time at risk, which is incorrect.
There’s a third surgery that begins some time at risk…and we see here that there’s no outcome after that. Shouldn’t that be considered in the IR calculation? CohortIncidence is striving to incorporate all relevant information into the IR calculation.
These concerns are probably best discussed in the Research section, but I wanted to call them out here so you can think about the implications of measurement error and immortal time bias if we allow options like ‘only follow to first outcome’ and ‘ignore prior outcomes’.