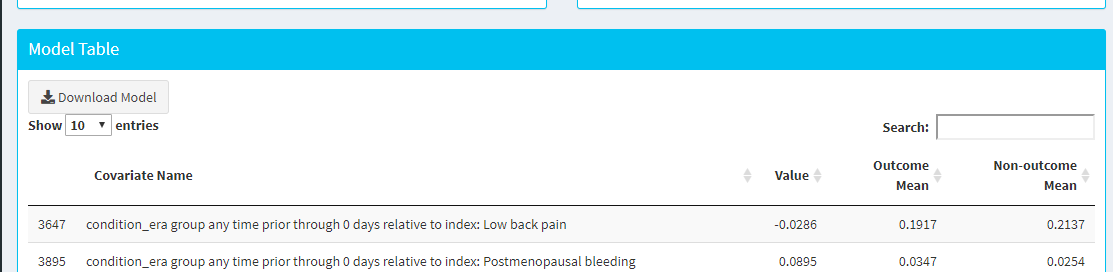
dear all,
I get the results of PLP, but I have a question about the model. Just like the picture show, I can download the model, but what is the mean of the value in the model? how can i get the probability of one particular person to get the outcome using the model?
thank you very much. As you said, there is the answer in the book of OHDSI, that if it is the general linear model, the value is the coefficient. but if I choose the model such as decision tree and I have a particular person who meets the criteria about the target cohort, and I want to know the probability of the person to have the outcome, how can I use this model to calculate the probability?
I think the easy way to solve your question is to create a validation package using execute(createValidationPackage = T) in the codeToRun script.
To my knowledge,
In the “prediction.rds” file of plpResult folder, column “value” is the probability of the patient to have the outcome. (indexes -1 : test set, other indexes : training set)
and
In the “varImp.rds” file of the model folder, column “covariateValue” is variable importance of each covariate when you choose the model such as decision tree or gradient boosting (when regression, coefficient of the model),
also you can find “model.rds” file that have information about parameters.
If you want to test the model for the other dataset without validation plp package (that’s the same meaning with calculating the probability I think),
you should get a covariate data of the cohort from the database using like FeatureExtraction::getDbcovariateData and then you could calculate the probability using covariate data and model developed.
Please point out if there is something wrong and let me know if you find a better way. I’m always learning through forums.
Thank you very much @Chungsoo_Kim, When I use the R to open “prediction.rds” file, I find it doesn’t work. Do you know how to open it? thank you very much