Hi all,
We have stumbled upon an intriguing but challenging problem that we are struggling with. Currently, running a PLE that tends to overfit and doesn’t nicely balance out the Ps between the target and comparator cohorts.
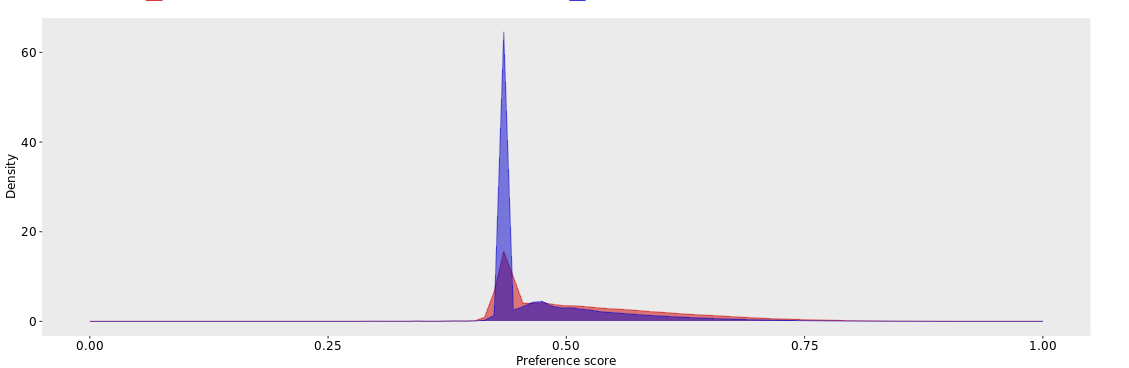
Our set-up is looking at index event of a condition and target cohort is an exposure drug, whereas comparator cohort is a no exposure to the drug (there is no comparator drug in this case).
We have been able to run the whole analysis successfully once before. But after what seemed a minor change in the Ps for exclusion (deleting some concepts from the concept set that had minor patients counts and no direct effect on the model/outcome/etc.), the model is massively overfitting. The propensity model is also very small, only including a few hundred covariates vs thousands prior. Nothing has changed in the analysis settings otherwise.
Initially we thought that the problem might be due to a different sampling of the cohorts, but after we set the sampling to 0 (no down-sampling) the problem is even more prominent. The whole package also runs in a record time of 3h when it overfits vs. several days when it runs “normally”.
Has anyone ever had this before, and if so, could you help point us in the right direction?
UPDATE – we have since figured out that this is a sampling issue.
Thanks so much for your help,
Milou