Thanks @Gowtham_Rao for the opportunity to be the inaugural ‘phenotype evaluation’ post for Phenotype Phebruary 2023. I have learned a lot from the process, and from your work on this so far.
By way of background for others, I’m a general internist, I work clinically at a large academic teaching hospital in Calgary, Canada. After my IM fellowship, I did an MSc out of Stanford in Biomedical Informatics. I’m onboarded as a research affiliate at Stanford, where I continue OHDSI work with Nigam Shah’s lab, and have been focusing some time this (sabbatical!) year in helping to advance the phenotype library with Gowtham, Azza, and others.
As we know from our debate topic this week, what constitutes a ‘phenotype peer review’ is a not a settled issue. Prior reviews in this forum have taken the forms of thread conversations that build on the submissions. While transparent (and while the threads themselves can be very insightful), it can get lengthy to parse.
So I’ll also use this post to propose some summary tables that try to condense that material into a different format. The idea there, is that we need to make it easier to parse ‘what’s been done’ in the development and evaluation process, with the supposition that we can invest more trust in phenotypes that have been more broadly characterized across a network of data sources, in different ways, by different investigators.
I won’t completely abandon the notion that we offer comments on the original post, as those discussions can bring a lot of value. And nobody needs to follow my lead on the tables either: how we do this, is the subject of our week 1 debate!
For Acute Pancreatitis, I was involved in the OHDSI symposium where we discussed this phenotype at length. In particular
Clinicians in the room expressed angst with this finding, as they expressed that it is extremely unlikely that persons with true/suspected acute pancreatitis would be managed exclusively in an outpatient setting
I had some of the angst ![]()
I was subsequently involved in the joint profile review where we noted the ‘outpatient + ED proc occurrence’ finding that informed the current version.
It did solidify, in my mind, the value of profile review. One of the broader points to this post is to suggest that the combination of some level profile review (while time consuming) and database level characterization (CohortDiagnostics) can be very synergistic activity. It may be that profile review takes a different form in the near future (those interested should check out @aostropolets work with KEEPER) . And admittedly, different sites have varying abilities to execute on it, depending on data access policies.
To offer some comments regarding the submission post:
AP is categorized as mild (no organ failure or complications), moderately severe (transient organ failure/complication that resolves within 48 hours), or severe (persistent organ failure of ≥1 organ).
This addresses @nigehughes 's question regarding differentiation of mild and severe.
It’s noteworthy that the grading in acute pancreatitis reflects the degree to whichyour other organ systems are failing, not just the exocrine functions of the pancreas. In contrast, many other ‘severe’ organ system afflictions (pneumonia, kidney injury, etc) can often manifest as single system disease.
Anything greater than the mild pancreatitis is more like systemic sepsis. This is at the heart of some discomfort in accepting purely outpatient trajectories, with minimal evidence of additional monitoring or investigative effort. You do want to determine causes and address them if at all possible - it’s a serious disease.
Disqualifiers: Persons with CP should be considered to be ineligible to develop AP, even though they may have flares that mimic AP
An interesting point here in that there may indeed be a difference between disqualifiers (as a clinical notion) and disqualifiers (as a design choice), I’d agree that in this case, it reflects a design choice, more than something that is mutually exclusive clinically.
This really demonstrated the value of case / timeline review. We’ve discussed the ETL implications with @Dymshyts but I also wonder aloud to @clairblacketer f there’s a DQD test inherent to that observation- i.e. outpatient (as visit_concept_id) + ED visit (as procedure_concept_id) should = ED visit?
It may impact other acute phenotypes (e.g’s on data.ohdsi.org include appendicitis, or even review of the 'inpatient hospitalization). And this is not a dig at ETL or the CDM: the visit table in source data is usually a hot mess.
The impact on the original (pre symposium) pheValuator run is also noteworthy. And to frame it, let me state up front that I’m a huge pheValuator fan, and at the next OHDSI symposium, I’m going to ask @jswerdel to sign my printed copy of Phevaluator 2.0 , and possibly my chest.
And I’ll leave more for on this topic for our week 4 debates. Suffice to say that the important (and appropriate) role that PheValuator results can (and should) play in rule based phenotype design choices can be heavily conditioned on the distribution learned through xSpec. So some kind of upfront review / human-in-the-loop may have some value add, to ensure it’s on track based on the real world data we have. The goal there wouldn’t be to catch occasional mislabeled cases (inherent to any noisy labelling experiment), but to catch ‘category level’ errors. A review of disjoint predictions between the rule based phenotype, and pheValuator might also add confidence to its determinations (these are not must haves, but trust building activities :))
25% lipase seems low, but I see it also varies by database, which likely reflect the degree to which inpatient activity is captured (low in CCAE, higher in optum EHR).
The visit issue is interesting. If I look at visit context in cohortDiagnostics, I see
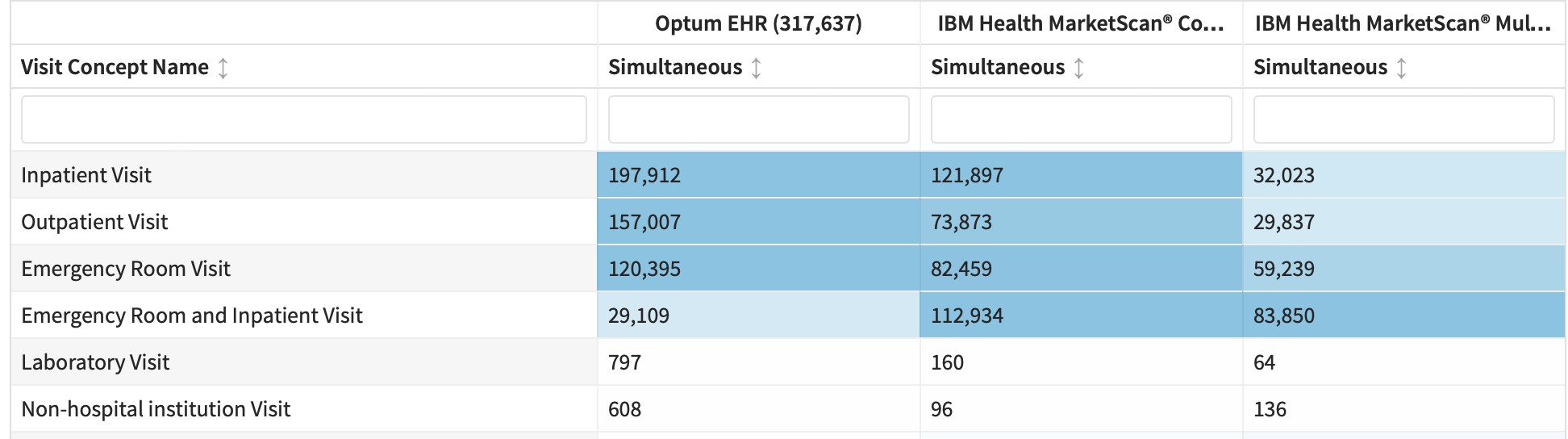
It’s easy to look at that and not decipher the degree to which this is an inpatient disease.
In the cohort characterization tab, thanks to the development of ‘inpatient hospitalization’ as a cohort, I can see this more clearly:
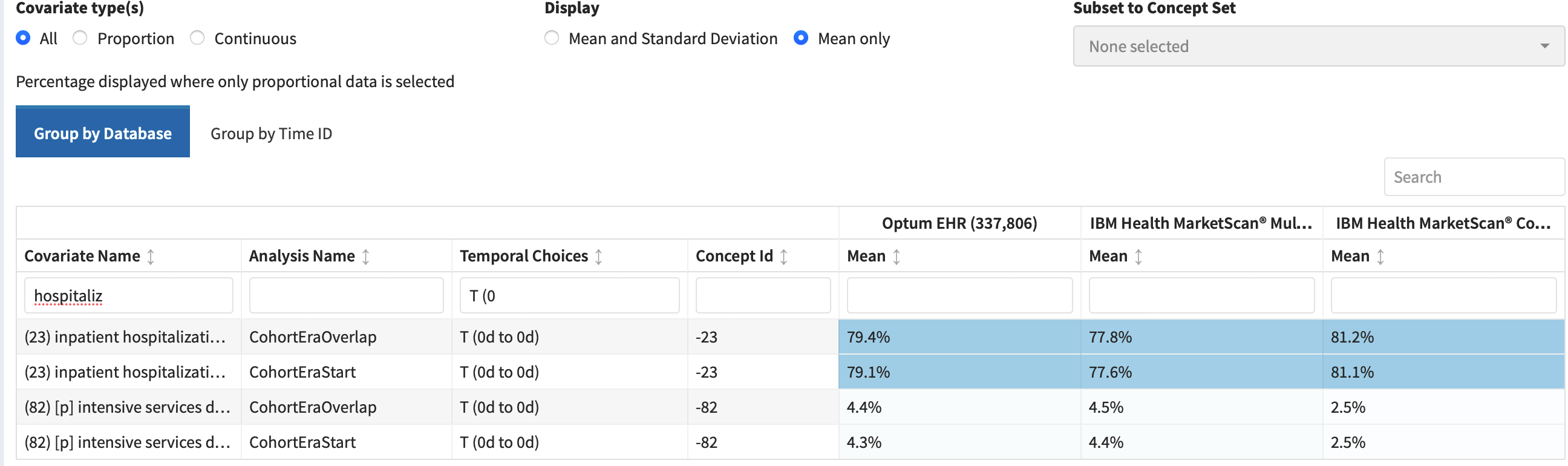
Cohorts as Features for. the. win. We need more of these.
That kind of admission rate aligns to what I’d expect based on gestalt - in the symposium, I unscientifically texted and ED MD friend, who felt 4/5 admission rate was their number too. It aligns to some prior work by McNabb-Balter et al, in the National ED Sample database, that suggested ~75% get admitted (although I can’t comment on how clean that DB is, and they used a single ICD-9 code to identify pancreatitis)
I agree here.
I think the biggest source of specificity error remains the ED encounter to ‘rule out’ pancreatitis. It’s reassuring that our hospitalization rate appears to reflect how we think the disease behaves.
I reviewed 15 cases in CCAE via CohortExplorer. I’ve revised those uncertain reviews twice. I found 12/15 were positives (PPV 0.8).
I struggled when cases also included cholecystitis, as they also went on to get their gallbladder removed, and a certain amount of gallstone pancreatitis can be caused by stone passeage. Cholecystitis ranges 5-15% across databases.
Of the 3 negatives, 2 looked like rule out situations, with no adjunct investigations (US, CT), or follow up care. I did observe 2 cases where patients that were not admitted did receive follow up care and investigations appropriate to pancreatitis.
This suggests to me that there’s a role to consider this entity of ‘ed only’ pancreatitis further, and perhaps iterating to require further evidence in those cases, given the lower prior we’d attach to them.
As part of our week 1 debate, we’re considering the role of ‘peer review’. I’m of the growing mindset that we should seek to be transparent as to what’s been done, what’s been learned, what might be left to do.
The issue I’ve raised above may matter depending on the use case (or not? see week 3 debates!). But I don’t see it as prohibitive of it’s entry into a phenotype Library.
We can consider what activities have been completed at a high level:
| Original Submission | Review 1 | |
| Gowtham Rao | Evan Minty | |
| Clinical Description | Completed (GR) | Reviewed |
| Literature Review | Not systematic | Not systematic |
| Design Diagnostics (PHOEBE) | ||
| Cohort Diagnostics | Reviewed in 11 DB | Reviewed in 4 DB |
| PheValuator | pending (in current version) | |
| APHRODITE development | ||
| Profile Review (within sample)) | 15 pts in CCAE Additional pending |
|
| Profile Review (xSpec) | pending (in current version) | |
| Discordant Case Review | pending (in current version) |
So there are a few other trust building activities we could take on, including a pheValuator run of the current version of the phenotype. I’d be happy to review the xSpec in that planned run, and review some discordant case predictions.
We can also develop a more detailed view of these activities that seeks to align our insights from data, to the clinical description of interest. For that, we can look to the week 1 debates ![]()