We are currently using WebAPI and Atlas version 2.12.0. We started to see peak usage of WebAPI every Friday lasting till the weekend which is causing problem with loading Atlas concept sets and cohort definitions. All other tools that depend on WebAPI starts to crash on Friday and will be back to normal on Monday.
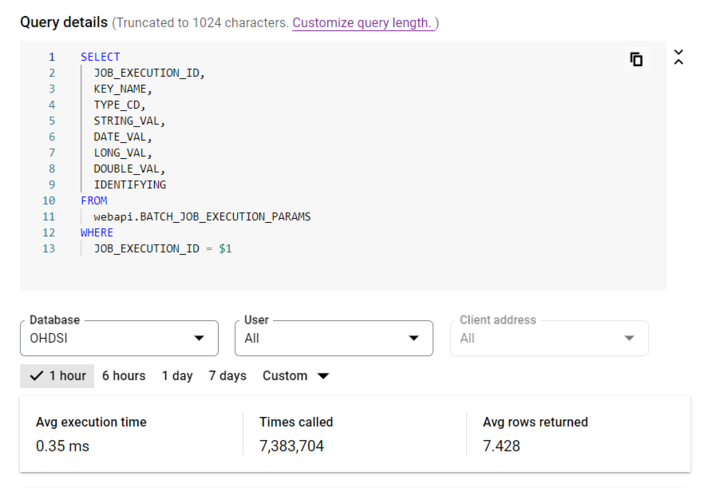
We found out that this is because of a looped query being run on PostgreSQL database. Will someone confirm is this looped query part of the WebAPI cache run?
Ok that query is fetching job params for a given execution. This could be done when the UI looks at the Jobs view in the UI. I’m not sure why this would just kick off suddenly on a friday.
Is there any way you could capture what the paramater of $1 was for those calls, if they are focused around one specific job execution ID or maybe a set of them. I think 7.4M calls in 1 hour seems crazy, we need to have some of the tech folks look at where this query is invoked and why it would be invoked so often…thre is a notion of an ‘N+1’ query where when you query an entity, you fetch the ‘root’ object once, and then for each associated N entities to it it does N addional queries (root (1) + associated (N) is N+1). Will need to investigate this further, I’m not hearing a lot of reports on this happening, but clearly it’s happenign for you so we’ll have to hypothsize about what would lead to that behavior.
Btw: if you were to look at your Jobs panel in AtlasUI, coudl you tell me how many job executions are in your environment?
I have started to look into Atlas jobs and it appears there are quite a lot of failed cache jobs
for different CDM databases we are using. They coincide with the WebAPI peak usage. Here is the image of failed cache job
This goes on for one day untill they are completed. Is there a way we can why this cache run failed?
Will you please let us know if you have faced something similar or suggest any idea to fix this problem as rest of the applications would not work when WebAPI has peak usage.
2.14 has a better implementation of the cacheing (it’s more performant) so you might want to upgrade there.
The error may be caused by a missing table or misconfiguration. You should be able to see an error message in your WebAPI log.
I’m not sure if 2.12 has the option, but there is an option in the source table called ‘is_cache_enabled’. If you set this to false, it will not attempt to run the cache jobs when the application starts.
However, this change does not work because of cache in atlasdb-postgres-data.
To circumvent this, I have changed within the running PostgreSQL server by doing this
psql -U postgres -c ‘UPDATE webapi.source SET is_cache_enabled = false WHERE source_id < 7’
This replaces the cache value of every CDM source with source_id below 7 to false and resolved it. When I restart the PostgreSQL server I can see that cache is FALSE for source_id < 7.
I am little bit confused as to why the INSERT from the source did not update the is_cache_enabled column with the latest settings
We have recently shifted to WebAPI 2.14.0 and started the experience Atlas hanging up and taking long time to load Cohort Definitions, Concept Sets, Characterization, Pathways and other pages. We had initially 7 heavy BigQuery data sources and have disabled cache for 5 of them. Rest of two data sources are quite big with each one around 300G.
We are also trying to understand which parameters are responsible for this i.e is it because of number of users or size of the data source or is it cache.
Also, given that there is better cache config with respect to WebAPI 2.14.0, we did see improvement in our resource usage but at the same time Atlas got very slow. Withing the pom.xml file we see that cache.cron is disabled. Does this mean warming cache is only run once at the beginning and will not run again as long as WebAPI is not restarted?
We are wondering if you have heard anyone face such problem.
Hi @Sam. sorry to hear about the issues you’re having.
I’m not sure which parts of the app you’re referencing when you say ‘slow’. Loading up the cohort definition list, for example, doesn’t touch any CDMs (same with loading the lists for concept sets, characterization, pathways, etc). It’s only when you open a specific elements that it will reach out to the CDM’s result schema to load results. Is it loading results that’s slow and not the other aspects of the app?
As to your question about the cache:
I had to look this up: that param is only used here. Meaning, it seems to be a WebAPI setting that will determine if the cron interval will warm caches.
But, the warm cache that happens during startup is controlled by the Source definition. Ie: how it’s set in the WebAPI database for the given source.
That field is referenced in the warmCaches() call. warmCache() is invoked when WebAPI first starts up on each source that has a vocabulary and results schema, AND the source has cache enabled.
Disclaimer: there’s a bit of a misnomer on what ‘disableCache’ means. The record counts that are being warmed just means that the entire set of record counts (millions of records) are being loaded into the WebAPI at startup (ie: when isCacheEnamed == true) vs. when concepts are being requested ‘on-the-fly’ which will selectively load the record counts from the CDM results schema.
But I think the cache warming function has no real impact on loading cohort definitions, or the other items you are talking about, so it’d be curious to understand what exactly is going on there. I am aware of BigQuery sometimes shutting down after inactivity, so one thing that could slow the startup of WebAPI is that it does an initial health check on each of your CDMs to see if they are available and what version of vocabulary are on them. I am not sure if this startup activity is what is leading to your performance problem, but we have BigQuery in our own environment, and when the app starts up, the entire app will take a long time to load because the first thing Atlas does is gets the list of datasources, and if one of them is taking a long time to respond, then the app waits for it until it does.
Hi @Chris_Knoll, thank you for your message. It does clarify the cache issue.
But I think the cache warming function has no real impact on loading cohort definitions, or the other items you are talking about, so it’d be curious to understand what exactly is going on there
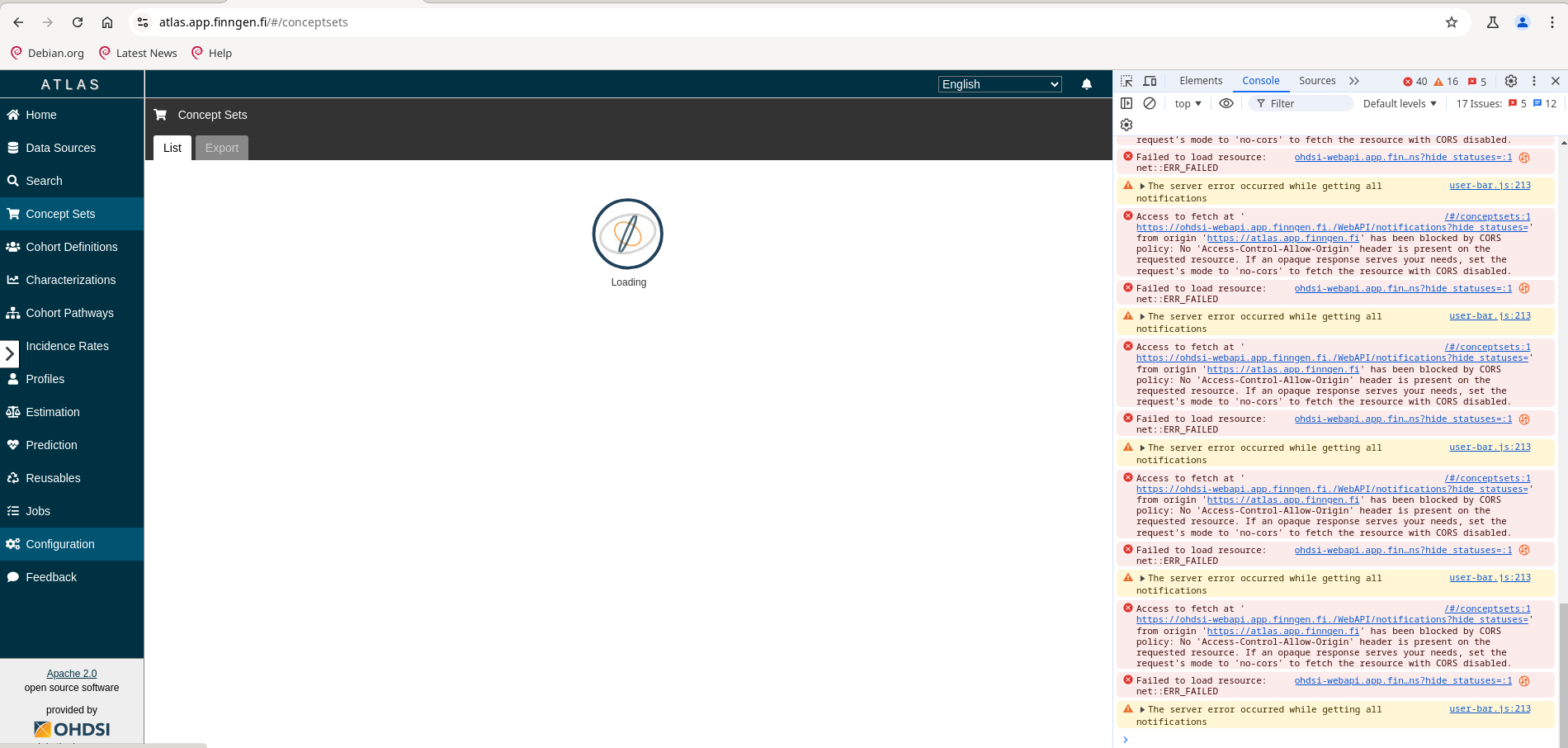
This is interesting from our side as well. Somehow, we were having trouble loading “Concept Sets”, “Cohort Definition” and “Characterization” pages within Atlas.
Initially, it started with CORS error where Atlas was sending out a request to WebAPI but could not go through. Then Atlas started to send too many connections which increased the burden on the server we hosted.
We understood it as cache problem and we disabled the cache for all of data sources. NOTHING CHANGED even after cache disabled. After that we have increased the CPU and RAM sizes and which fixed the loading of those 3 pages on Atlas. But we still do get recurring CORS error in Atlas without hindering Atlas functionality.
Given that security is paramount for the data we have, our admin team did not want to disable CORS feature within pom.xml or change the security origin. With this, we are wondering if there are tables within postgreSQL database that we need to aware of so that they do not take too much size that can crash the database or create CORS problem?
We really appreciate your answers. Thank you very much.
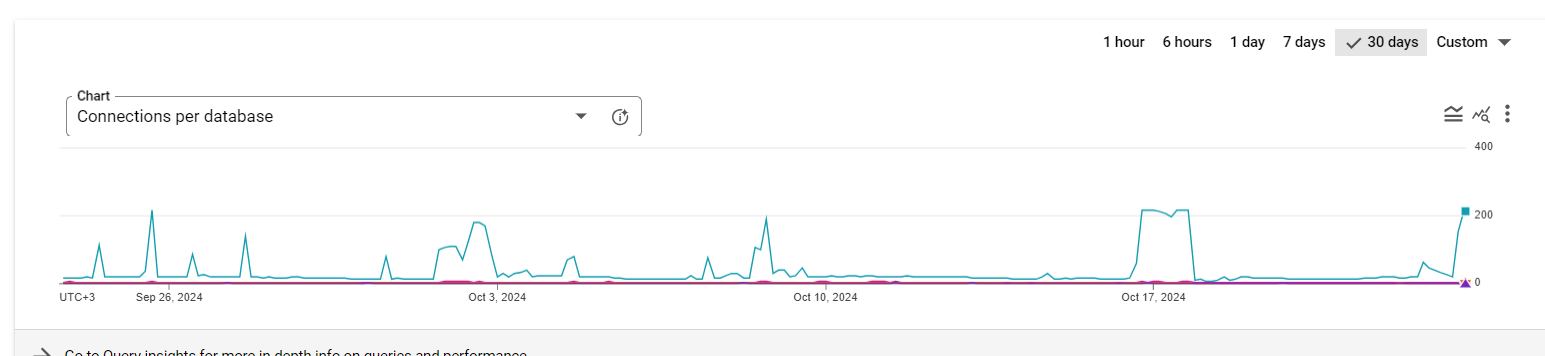
This is the problem we are currently facing. There is an uptick of connections to the database and suddenly it take quite a long time to load “Concept sets”, “Cohort Definition” and “Characterization” pages.
After going through WebAPI logs, we found out that GC concurrent-string-deduplication kepts getting queued and when looked what it details, we found out it is about Garbage Collector (GC) of Java that optimizes memory usage by deduplicating identical strings. Which is why we are wondering the following question.
Does this make sense to have WebAPI Java server to have options -XX:MaxRAMPercentage=75.0 -XX:+UseG1GC -XX:+UseStringDeduplication -XX:+PrintStringDeduplicationStatistics with 8 GB of memory?