Hello OHDSI community,
I have a question regarding the implementation of a trained model as an API for patient-level prediction in order to develop a prototype of a Clinical Decision Support System (CDSS).
I have successfully trained a Gradient Boosting Machine model that predicts death as an outcome. Now, I would like to integrate this model into our CDSS prototype. My goal is to create a microservice that can receive input data related to a patient and provide the predicted score as an API response.
I would appreciate any guidance or recommendations on how to proceed with this implementation. Specifically, I am looking for insights on the following:
What technologies or frameworks would be suitable for creating the microservice to host the trained model as an API (R, Python, etc.)?
Are there any existing projects or examples that demonstrate the appropriate format and structure of the input data (feature vector) to be sent to the API for obtaining predictions?
Without knowing a bit more, I would initially suggest FastAPI. I am in the early stages of planning to use this with LLMs, and it seems to be the standard in that space.
If you are returning feature vectors, I would suggest having a vector database like milvus or qdrant.
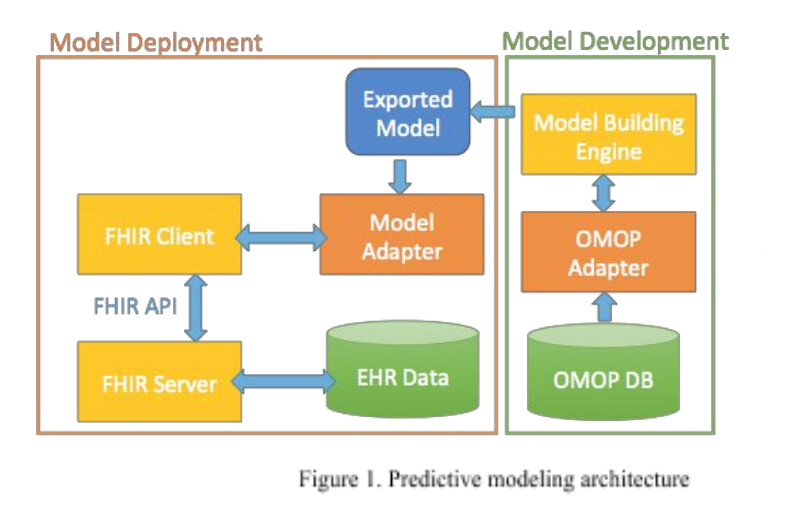
Thanks @hspence for your comments. I apologize if I didn’t explain my previous question clearly. After giving it some thought and exploring potential solutions, I came across the “clinical predictive model development and deployment platform” approach described in this article. It has provided some insights for the architectural solution (Figure 1).
Now, my challenge is to utilize the predictive model trained with the PatientLevelPrediction package to calculate the risk for a single patient based on a vector of features. I have some ideas, but I’m uncertain about how to implement them. I’m aware of the method PatientLevelPrediction::predictPlp(), which predicts the risk of the outcome using the input plpModel for the given plpData (Figure 2). Loading the model can be achieved using PatientLevelPrediction::loadPlpModel(), so that part seems clear. However, I’m facing a challenge when it comes to creating the plpData due to the requirement of cohort creation, which complicates the scenario for a single patient. I have observed the plpData generated in my use case (Figure 3), but I’m having difficulty understanding the specific feature vector that needs to be provided as input for the predictPlp() method.
getPlpData should return an object with covariateRef that describes the covariates. Those covariates can be customized from default using the FeatureExtraction package
Let me know if that helps.
Can you describe more how the cohort creation complicates things?
Hi @hspence, I’m uncertain and struggling to determine the right approach for my solution. Originally, I aimed to train the model, integrate it into an API, and provide personalized precalculated covariates. My intention was to bypass using OHDSI libraries, particularly for real-time risk calculation, due to the inclusion of parameters I perceive as unnecessary (such as the “population” created via createStudyPopulation() for risk prediction or a cohort without the known outcome). A similar strategy was employed in this article, yet I’m finding it challenging to reach a straightforward resolution. It’s plausible that achieving such a simplified solution for real-time risk calculations might be unattainable.
@Alonso from my understanding your aim is the following workflow for the API:
API Workflow
Get a an individual patient’s data in {plpData} as selected for by {apiClient} request. Where {plpData} is an object that holds a cohorts information – you extract/create {indPatientData} for a cohort of 1.
Run your model using the [Predict] function passing {plpModel} on {plpData} and {population}
However, this will not work due to 1) {plpData} is a cohort of 1 and 2) {population} is required
Generate the {riskScore}
Return {riskScore} to the {apiClient}
The [Predict] function requires {population} because it produces a score for each patient and posts it to the database. Instead, you may be more interested in [runPlp] as described here with an example of GBM at the end of the commented text at the top.
For your application, consider two questions that may guide your approach:
Is this workflow more efficient than having risk scores pre-calculated in a database and accessed through the API? That is, does every request to the API of {indPatientData} run the model. Would it be more efficient and valid to store each patient’s risk scores and have requests call that data?
Is it feasible to decouple this from the PatientLevelPrediction package? That is would it be better to write this independently without trying to get the PLP features to meet your use case?
Guidance from @jreps definitely be your best bet if you want to try and keep with R/OHDSI tooling for this. I am nowhere near as familiar with PLP package.
I would encourage a pure Python approach due to:
The flexibility of working between different domains (WebAPIs, ML models, databases, and micro services).
The PLP package implements Python libraries like SKlearn using R(Reticulate), so you would be getting back to the ‘roots’. This may have performance improvement.
You can use the CDM easily by creating Pydantic data models.
R does not have many well supported/documented API libraries compared to Python (FastAPI).
An independent package is a better fit for a ‘microservice’. The PLP package has dependencies in the ‘monolith’ OHDSI Suite. As much as there are efforts to keep things modular, OHDSI packages tend to build upon eachother.
I truly appreciate the clarity and quality with which you presented the information. It has been instrumental in helping me better understand my challenge, and I’m gradually clearing up certain doubts regarding my approach to executing the {plpModel} in real time using an HL7-FHIR data source.
In my case, I wanted the data to come from an HL7 FHIR server. Therefore, I assume I needed to transform to OMOP CDM.
Could you explain in more detail why a cohort of 1 person and the creation of {population} will not work?
Are you mentioning this because {targetId} , {outcomeIds} , and {cohortId} can be NULL?
I sense that this would be best, but only if the API call doesn’t contain updated information, as in that case, the {riskScore} should be recalculated.
I’m not sure, but it would be great to know if the existing PLP package can cater to my use case.
Fantastic! If it solves my issue, I’d definitely want to give it a try.
How would the calculation of covariables work in Python? Is there something similar to {covariateSettings}, created using the [createCovariateSettings] function in the FeatureExtraction package?
Is this related to the extraction or reading of {indPatientData}?
I’ve been delving deeper into the topic and would like to inquire about the following:
Understanding that using the [predictPlp] function without defining a study population is not feasible, I’m wondering if the model.json file generated by the PLP package could be loaded into the Python scikit-learn tool? Hey @jreps mind confirming this for me? Thanks a bunch!
I also realized that the FeatureExtraction tool might not be very useful in my case, given that the data source for an individual patient entering the model comes in HL7 FHIR format. If it’s possible to implement the {plpModel} in Python, I’m curious about how the FeatureExtraction package processes data to obtain {plpData}, which I would like to emulate using a customized script in Python. Reviewing the documentation, for instance, under the Measurement domain within an analysis ID, it takes one covariate containing the value per measurement-unit combination in the short term window. Is this accurate? Hey @anthonysena could you lend a hand with this? Thanks a bunch!
Alternatively, could a solution to my challenge involve temporarily converting the patient’s data from HL7 FHIR to OMOP CDM, then extracting the covariates? However, I’m aware this approach faces the barrier that [predictPlp] doesn’t work in this use case.
I’m sharing these thoughts to see if anyone in the community has considered a solution to this challenge.
The current use case for PLP has been to make prediction for a set of patients, so the predictPlp() does that. However, as you have a different need (and other people may also) I should be able to easily add a function that takes a patient_id, index date, OMOP CMD database connection, schema details and plpModel and outputs the predicted risk for that patient. It should also be possible for me to add a function that takes the patient’s features and plpModel to output the predicted risk (although this is risky as it assumes the features are created the same way as model development, but there will be no guarantee).
For GLM I’ve actually previously bypassed using R/python by adding the model as a table in the database and then use SQL to calculate the risk (for 1 or millions of patients). However, for models such as Gradient Boosting Machine I’m not aware of how to implement that via SQL. If anyone knows of any way to use SQL for non-GLM, happy to hear as doing all the prediction in SQL would be great and we could add that to the package.
Thank you @jreps for your willingness to develop this functionality. I like the solution, but I’m not sure if including the “index date” as a parameter is necessary. If I’m correct, it might be redundant to provide this parameter as input since it could be inferred from the time the covariates are fed into the model. Of course, my view is based on my general understanding of the process, and there may be technical reasons or specific considerations that justify including this as a parameter. I appreciate any clarification you can provide on this matter. And related to your solution, I’m thinking about a potential solution for my challenge. Given the trained {plpModel}, perhaps we could take data from the last 5 days (as per the study specifications I used to train the model) of a new patient from HL7 FHIR, transform it, store it in a temporary OMOP database, and then execute the functionality you mentioned. Does this make sense to you?
I did respond to your issue on the PLP github. It’s a hacky way to use predictPlp for one person, not sure if it helps. I think it would be best long term though to have a function like @jreps mentioned to predict for a single patient.
As to reading a model.json into scikit-learn. That should be possible. For example:
import joblib
import numpy as np
path_to_model = 'path_to_saved_pkl_file'
model = joblib.load(path_to_model)
rng = np.random.default_rng(42)
X = rng.integers(0, 2, 33082).reshape(1, -1) # random binary vector with as many features as development data, N x P
model.predict_proba(X)
Hello @egillax,
I greatly appreciate your assistance with my challenge. I’ve been trying to replicate your solution, and I’ve successfully loaded the model in Python. The question that now arises is that when I compare the values of the covariates generated by the PLP package, they are different from the feature importances loaded from the model.json file using the joblib library in Python (see Table 1).
Now, my question is whether the input vector (which in my case consists of 44 covariates) to the model should have these values in the same order as Table 1? I would also like to know if these data should be normalized on input or if I can input them as they come from the data source. I was thinking of extracting the last value for each covariate at the time of prediction. What is your opinion?
Table 1. Comparison of Covariate Value and Feature Importances
covariateId
columnId
covariateName
covariateValue
feature_importances_
1002
1
age in years
0.0344350403658176
0.029602008271865068
3003
2
age group: 15 - 19
0
0.0
4003
3
age group: 20 - 24
0
0.0
5003
4
age group: 25 - 29
0
0.0
6003
5
age group: 30 - 34
0
0.0
7003
6
age group: 35 - 39
0
0.0
8003
7
age group: 40 - 44
0
0.0
9003
8
age group: 45 - 49
0
0.0
10003
9
age group: 50 - 54
0
0.0
11003
10
age group: 55 - 59
0
0.0
12003
11
age group: 60 - 64
0
0.0
14003
12
age group: 70 - 74
0
0.0
15003
13
age group: 75 - 79
0
0.0
16003
14
age group: 80 - 84
0
0.0
17003
15
age group: 85 - 89
0
0.0
18003
16
age group: 90 - 94
0
0.0
8532001
17
gender = FEMALE
0.00804535672125704
0.008430834747825832
3000905848708
18
measurement value during day -5 through 0 days relative to index: Leukocytes [#/volume] in Blood by Automated count (thousand per microliter)
0.0989311952834427
0.06602015706153698
3000963713708
19
measurement value during day -5 through 0 days relative to index: Hemoglobin [Mass/volume] in Blood (gram per deciliter)
0.0666560709028365
0.03777165368515944
3003396753708
20
measurement value during day -5 through 0 days relative to index: Base excess in Arterial blood by calculation (millimole per liter)
0.0467058493519704
0.10002743147704128
3004249876708
21
measurement value during day -5 through 0 days relative to index: Systolic blood pressure (millimeter mercury column)
0.0234891165004752
0.007467044979059556
3006923645708
22
measurement value during day -5 through 0 days relative to index: Alanine aminotransferase [Enzymatic activity/volume] in Serum or Plasma (unit per liter)
0.0385799502204692
0.046252432509425324
3008152753708
23
measurement value during day -5 through 0 days relative to index: Bicarbonate [Moles/volume] in Arterial blood (millimole per liter)
0
0.0
3010421482708
24
measurement value during day -5 through 0 days relative to index: pH of Blood (pH)
0.0146370737188851
0.02254729567740778
3012888876708
25
measurement value during day -5 through 0 days relative to index: Diastolic blood pressure (millimeter mercury column)
0.0170871478317643
0.01129239002409635
3013502554708
26
measurement value during day -5 through 0 days relative to index: Oxygen saturation in Blood (percent)
0.0247085221163163
0.03517299785673599
3013721645708
27
measurement value during day -5 through 0 days relative to index: Aspartate aminotransferase [Enzymatic activity/volume] in Serum or Plasma (unit per liter)
0.0284823776621151
0.030581789292383046
3016436645708
28
measurement value during day -5 through 0 days relative to index: Lactate dehydrogenase [Enzymatic activity/volume] in Serum or Plasma (unit per liter)
0.0222561727074551
0.037844661748233595
3018405753708
29
measurement value during day -5 through 0 days relative to index: Lactate [Moles/volume] in Arterial blood (millimole per liter)
0.0305228361680239
0.03747643200817109
3020460751708
30
measurement value during day -5 through 0 days relative to index: C reactive protein [Mass/volume] in Serum or Plasma (milligram per liter)
0.0803531625363724
0.10392106844349125
3020891323708
31
measurement value during day -5 through 0 days relative to index: Body temperature (degree Celsius)
0
0.006681986410834574
3024128840708
32
measurement value during day -5 through 0 days relative to index: Bilirubin.total [Mass/volume] in Serum or Plasma (milligram per deciliter)
0.0213003092314431
0.009779568634720268
3024929848708
33
measurement value during day -5 through 0 days relative to index: Platelets [#/volume] in Blood by Automated count (thousand per microliter)
0.0309305215109043
0.03211741429888567
3026910645708
34
measurement value during day -5 through 0 days relative to index: Gamma glutamyl transferase [Enzymatic activity/volume] in Serum or Plasma (unit per liter)
0.0303837699691677
0.03422408772464863
3027018483708
35
measurement value during day -5 through 0 days relative to index: Heart rate (counts per minute)
0.0125647654773936
0.00857431250546908
3027219840708
36
measurement value during day -5 through 0 days relative to index: Urea nitrogen [Mass/volume] in Venous blood (milligram per deciliter)
0.153354362307179
0.1108152107988281
3027597840708
37
measurement value during day -5 through 0 days relative to index: Bilirubin.direct [Mass/volume] in Serum or Plasma (milligram per deciliter)
0.0279071218353056
0.0199001522417011
3027598876708
38
measurement value during day -5 through 0 days relative to index: Mean blood pressure (millimeter mercury column)
0.0100936736946405
0.007161840469029077
3027801876708
39
measurement value during day -5 through 0 days relative to index: Oxygen [Partial pressure] in Arterial blood (millimeter mercury column)
0.023884139107857
0.004563254239598291
3027946876708
40
measurement value during day -5 through 0 days relative to index: Carbon dioxide [Partial pressure] in Arterial blood (millimeter mercury column)
0.0207164423605501
0.022421039584065355
3035839554708
41
measurement value during day -5 through 0 days relative to index: Band form neutrophils/100 leukocytes in Blood by Automated count (percent)
0.00136637977486254
0.006893340220819002
3035995645708
42
measurement value during day -5 through 0 days relative to index: Alkaline phosphatase [Enzymatic activity/volume] in Serum or Plasma (unit per liter)
0.0347237694079268
0.03955293009941143
3051825840708
43
measurement value during day -5 through 0 days relative to index: Creatinine [Mass/volume] in Blood (milligram per deciliter)
0.0576714398914426
0.02900840067000928
21490733840708
44
measurement value during day -5 through 0 days relative to index: Potassium [Mass/volume] in Blood (milligram per deciliter)
If you are doing it this way, loading the json straight. You are bypassing any preprocessing and/or feature engineering that might have been used when developing the model. Then you need to make sure yourself that you apply it to your new patients. This includes mapping the covariateIds to the columnIds, which control the order for the features in your matrix you feed the model.
I assume you have found the mapping between columns and covariateId, since it’s the first two columns in your table 1. (it’s in plpResults$model$covariateImportance). So yes the features you give the model need to be in the same order as the columnId your table 1.
Regarding normalization (and removal of rare/redundant features if you applied that), that info is in plpResults$model$preprocessing$tidyCovariates. For example for normalization there should be a list of normFactors with covariateIds. This is the max absolute value of that feature on the training set, so before applying the model to new patients you need to divide the feature of the new patient with that value to apply the normalization.
Regarding the feature_importance_ from python it should be the same as the covariateValue, are you sure you have the same models? and you didn’t update it by calling fit in python? The line in PLP that get’s the value is here:
So should indeed only be fetching the feature_importance_ from sklearn. I’ll check this myself today.
One way to make sure you are applying the model correctly is for example make sure it’s predicting the same risk for all the patients in your test set as the PLP.
@egillax I wanted to express my sincere appreciation for your valuable help with my prototype. Your insights were incredibly insightful, and I apologize for the delay in expressing my gratitude. Better late than never! Thanks again.