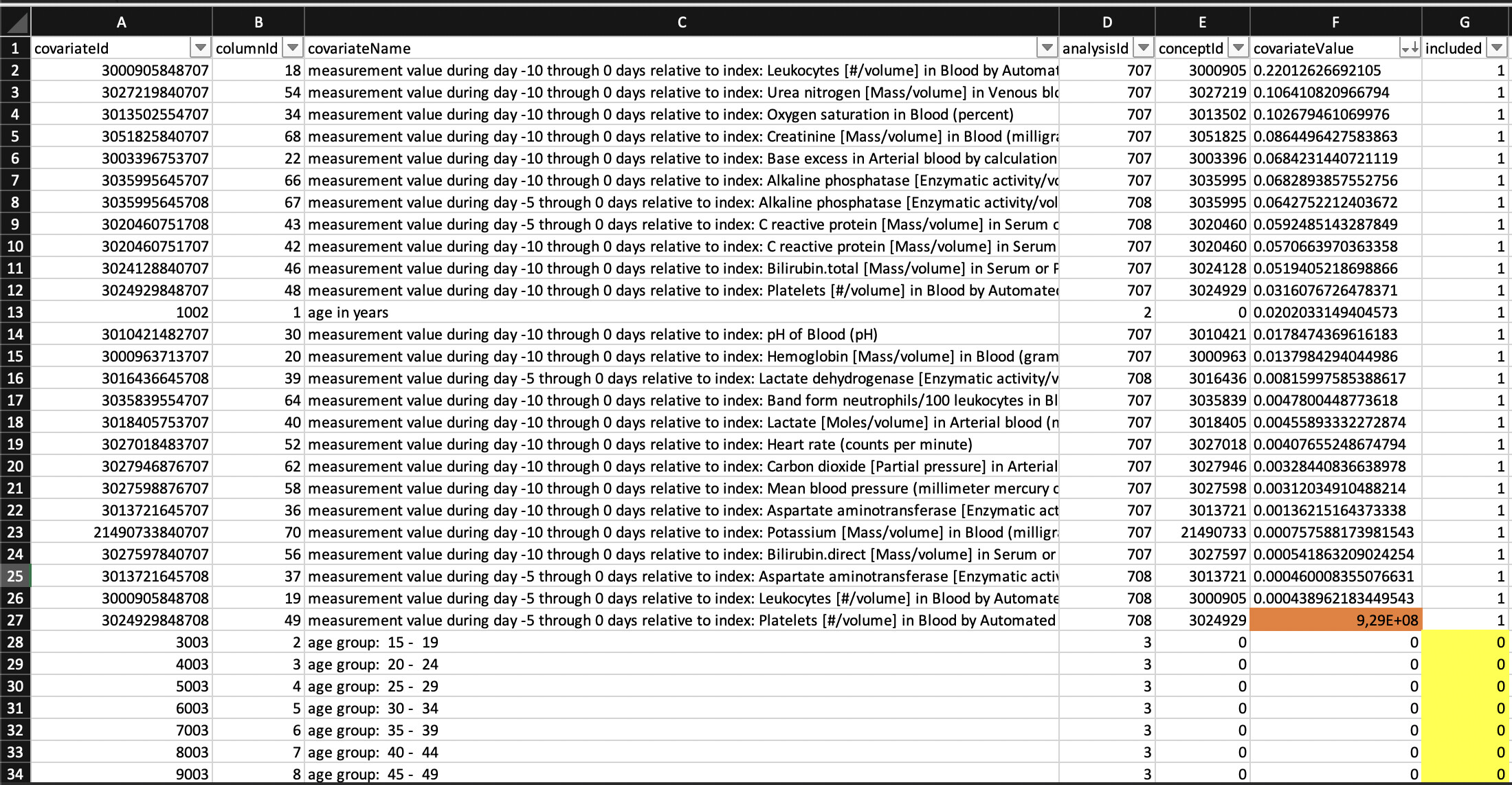
Dear All, I’m now conducting research using [PatientLevelPrediction] package. I would like to know how can I interpret the column included within the covariateImportance.csv file. What included=0 technically means (yellow cells)? And why there is a covariateValue greater than 1 (orange cell) (see image below).
When fitting Lasso the covariateValues are the model coefficients. included = 0 means these covariates were not selected in the final model. If you are fitting another type of model, it will depend on what kind of feature importance method is implemented in the package for that model. For gradient boosted trees using XGBoost it’s the relative influence/importance, i.e. how much is your objective/loss changing when using that feature for splitting in the tree.
This huge covariateValue you are getting does look strange to me though… What model were you using?
Hi @egillax,
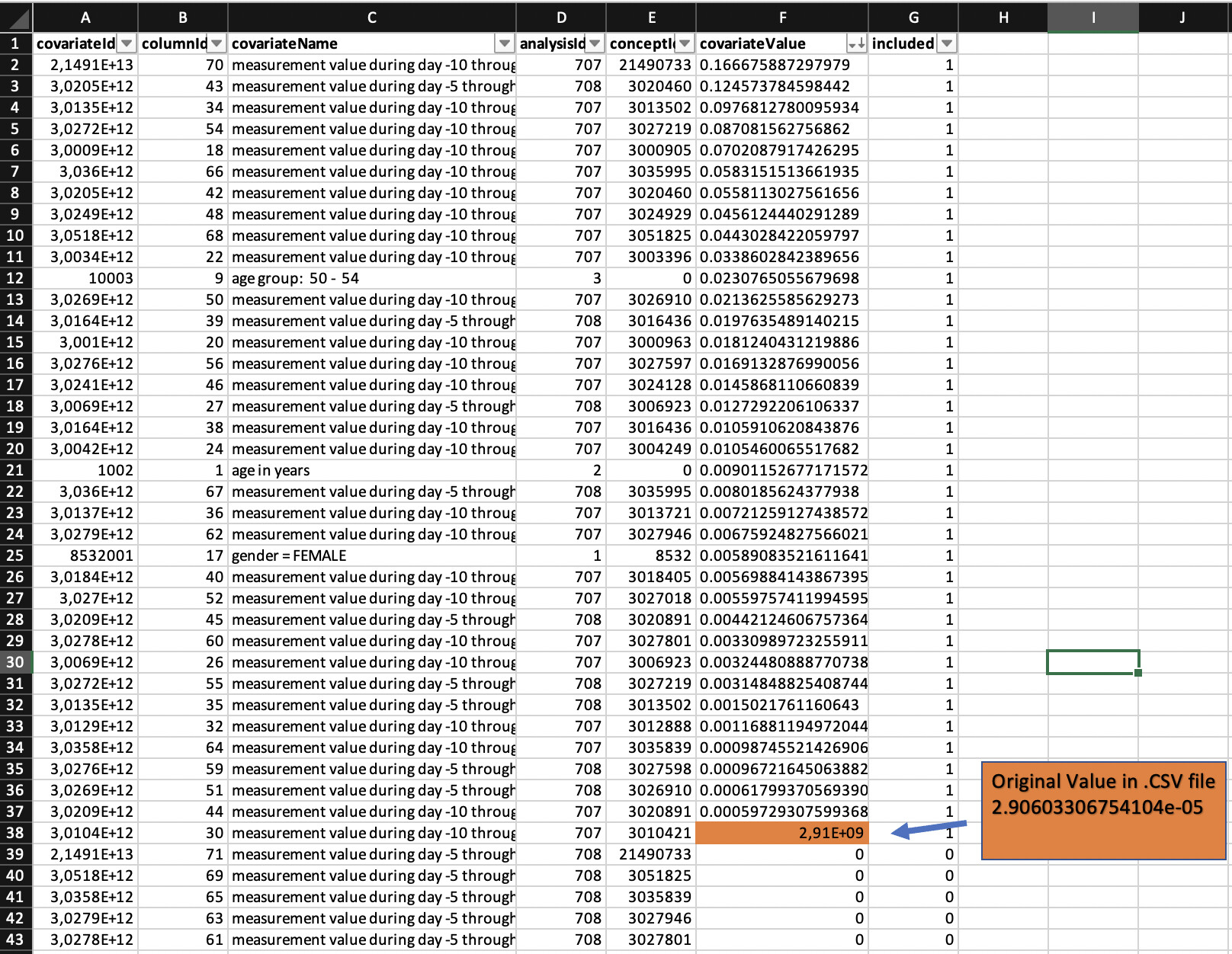
Thanks for your response. Currently I’m using a gradient boosted trees method with default hyper-parameters listed in the table below. But you know what, I just ran study again and it seems the error mentioned above was caused by reading the .csv file in Microsoft Excel. This software interpreted the original value of the covariate in the .csv file (2.90603306754104e-05) as 2906033067,54104.
From the list of covariates generated by the model, 37 of the 71 total covariates were included (see part of the list in the image below).
Regards,
Alonso
Table with study specification
Definition
Value
Algorithm
Gradient Boosting Machine
Hyper-parameters
ntree:5000, max depth:4 or 7 or 10 and learning rate: 0.001 or 0.01 or 0.1 or 0.9
Covariates
Gender, Age, Age Group, Measurement Value (<5, <10)