I’m not even sure this topic belongs in this category, but I’ll give it a go…
Thing is phenotypes that share a common ‘root’ are sometimes used for different contexts. E.g. you can think of “myocardial infarction” as a comorbidity (present on a given index date), as an outcome (present after a given index date but not before), or as an indication (e.g. present in a given time window before the initiation of a specific drug, say a statin or a betablocker).
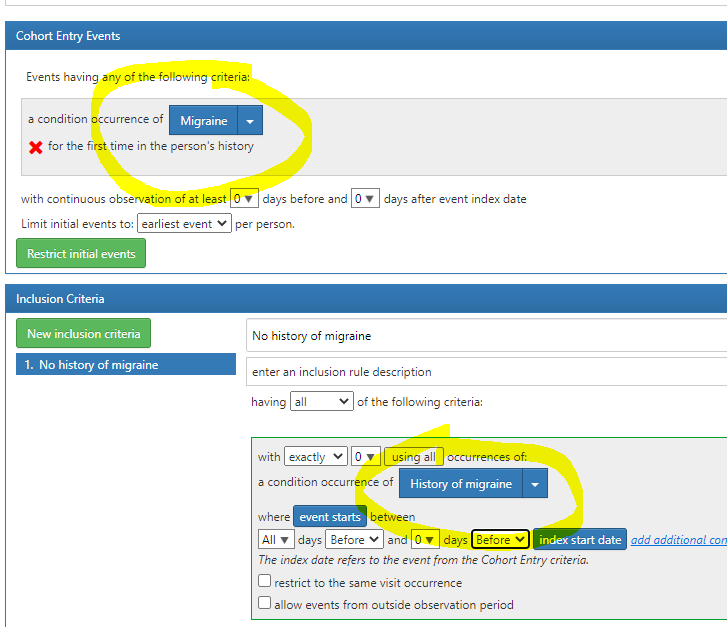
Although one can obviously implement these in a cohort logic simply imposing certain timings, some codes are in principle useful to some of these, but not others. E.g. 4059193 H/O: migraine would be useful to identify a comorbidity/prevalent condition, but not to identify an incident event. This is of course a toy example, but things can get more complicated. E.g. long-term sequelae of a condition would probably also not be useful to identify an incident outcome, and this is not immediately obvious in the concept description, but only implicit in the clinical knowledge underlining the aetiology of the event of interest
Have others in the community looked into this before? Is there an interest to define such ‘phenotype flavours’ (for lack of a better term)?
I think of phenotyping as given a real world target what is the our best effort to model that target. Given myocardial infarction what is our best effort to model myocardial infarction. Model in this case is the cohort definition. Target in this case is clinical description. All models have errors that may cause bias during interpretation of a study.
So our energy, in terms of validation/evaluation, is to see if the persons identified into our cohort (during their respective cohort_start_date) have the target - if not, how are we off i.e. error. We can have different flavors for the cohort algorithms each with different errors. e.g. some may identify almost all the persons in the data source but also add ppl who do not (i.e. high sensitivity, low specificity), others may add more specificity but low sensitivity.
So - this separates the use case from phenotyping. Phenotyping is thus limited to given the target lets model it. Use case is the study.
Continuing your example: if its important (based on your study design) to get the date of onset of migraine accurately i.e. we want to minimize index date misclassification, a cohort definition with the H/O migraine on index date is probably not a good choice. Same idea with long-term sequelae example.
We can formalize this thinking better i think but in this argument - i have separated phenotyping from study use case. Phenotyping starts from clinical description and ends with one or more cohort definitions with known errors. The use case/study starts from there and decides on how the errors may be the source of the bias - and decides which bias leads to most generalizable/valid study results and why.
So by talking about error you are restricting this to sensitivity and specificity (and related concepts like ppv and npv). This usually results in two ‘flavours’: wide, vs narrow
I am interested to know if you (or others) have thought of others, like for example, ‘prevalent’ vs ‘incident’. The former would include codes like “H/O migraine”, but the latter would not. This is independent of the ‘use case’ and cohort logic, and indeed inherent to the concept list you generate, similar to what you have for ‘wide’ and ‘narrow’
No no… we are talking in terms of target, and the error model/algorithm has in identifying cohort . The effort is in describing the target.
We are thinking in terms of Cohorts not codes. The model identifies spans of dates (cohort start date to cohort end date) the person has the target. That’s the Cohort.
The cohort start date is his or her incident date. The cohort dates after cohort start date but before cohort end date is their prevalent dates
For a person with migraine, we are trying to find the dates in their observation period they had migraine.
The Cohort algorithm should give us all the dates. History code cause problems because we don’t know when it started. I.e. index date misclassification.
This will probably give us good index date precision by removing persons with history of migraine prior. But, it is likely to introduce sensitivity errors. If the rule to remove history of migraines leads to 1% loss in person count, we may think that the errors is minimal and shouldn’t cause much bias. But if it is like 25% then we have a problem - that indicates a big sensitivity error problem by applying this rule. We traded index date misclassification problem with sensitivity error problem.
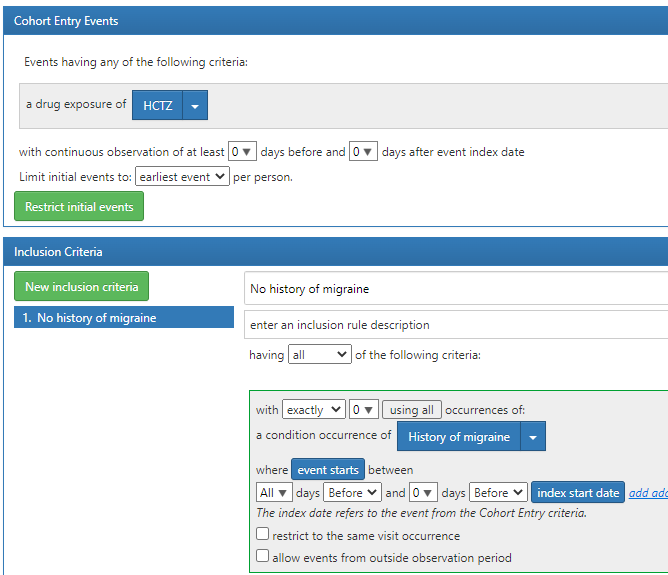
Instead of handling these history of codes in phenotyping - i think we can handle them during studies. e.g. if we are doing a comparative study perspective and the outcome is migraine. Instead of handling the history of migraine (i.e. history of the outcome) in the outcome cohort definitions, we can handle that in the target and outcome cohort definition.
Example: if the study is HCTZ vs Chlorthalidone for outcome of migraine - then the HCTZ cohort may be something like
and that way we dont have to worry about this being an issue in outcome cohort
The point is – we need to think in more in terms of cohorts (i.e. spans of time person has the phenotype) vs codes, and how the algorithm has errors in modeling the clinical description. Some of these errors we can find and report during phenotyping, and studies can handle them (as shown above) to reduce bias,
we could have a cohort definition that has good sensitivity but bad index date misclassification
we could have another cohort definition has good index date precision but bad sensitivity.
the study designed may pick one of the two, and say - i can handle the index date misclassification in my study methods. so the definition with higher sensitivity (and bad index date misclassificaiton) is good for the use case.
That reminds me of a broader discussion of acute vs chronic vs exacerbation. There the argument was that you cannot trust code assignment, or specifically its acuity attributes. Clinicians can put chronic bronchitis or acute bronchitis or exacerbation of chronic bronchitis in the notes/billing and it’s hard to distinguish these three based on code only. So there you’d a)learn the code use patterns and b) construct the logic to get what you want instead of relying on codes.
But in this example I find it hard to imagine you’d ever use the code for h/o migraine for your incident cohort regardless of how advanced your analytics is.
Also, can we actually adjust for index event misspecification? Sounds like a cool research project but we need to phenotype somehow before somebody completes it.
Exactly, and here you may use these insights to model the the three targets different a) acute, b) chronic, c) exacerbation of chronic.
This i have heard many times and i used to use it too. But I am now deliberately trying to avoid these terms to describe cohort definitions. I am now actually arguing that the idea of ‘incident’ cohort and ‘prevalent’ cohort is wrong. We only need cohort definitions that model the target (clinical description) - and outputs the total span of dates the person has the phenotype.
We assume that the cohort_start_date is the date the person first had the phenotype (which may be erroneous assumption i.e index date misclassificaiton), and cohort_end_date is the last date the person stays in phenotype (end date misclassification). All dates in between - the person is assumed to stay in the phenotype.
This concept is core to the OHDSI cohort definition and is used by our tools. Here the cohort_start_date is the date of incidence and maybe used for incidence computation. All other dates after cohort_start_date upto cohort_end_date may be used for prevalence computation.
So we do not need algorithms for incidence and prevalence cohorts - all definitions should model all the spans of date the person may have the phenotype, each cohort definition may have trade offs of sensitivity, specificity and index date misclassification (there is also an end date misclassification).
Going back to ‘history of migraine’ code, it may not matter if
it is rarely used and may not matter. i.e. see the use patterns. then why bother or just exclude.
it is used and so matters. If it matters - then if we create a cohort definition that does not use the history code and check if it is used a lot PRIOR to cohort_start_date (we can use cohort diagnostics for that). If its not used, then why bother. I found this to be the case most of time.
If it is used - then we have two options:
– say so and do nothing - it is a source of error (index date misclassification) and propose that it be dealt during analysis
– say so and do something – remove persons with this code prior to cohort start date, and say we removed people who may have the phenotyhpe - and it is causing sensitivity errors.
Note - in all of these scenarios, ‘history of’ code is NOT part of entry event criteria.
So in a way, i am saying, dont use it in the ‘entry event’ criteria of atlas cohort definition logic.
yup - agree. I am now convinced, we should not be using ‘history of code’ in entry event criteria, because it can never give us the precise cohort start date. If a condition has history of code, we need empirically evaluate its usage and think of impact of sensitivity vs index date misclassification.
If I move to the UK and become a new patient in the NHS system I might report H/O migraine. I may have entered the ‘cohort of migraine’ in 2005 but given that we don’t have linkage across databases our true ability to exclude or baseline covariate adjust may need to rely on these codes. So this is where in the situation and underlying real world nature of the data may dictate different phenotypes. I know a controversial topic.
One question that I have had which relates to individual codes utilized in code lists which again is a controversial road to go down. Say you wanted to follow a target incident cohort of diabetics for nephrotic outcomes would you allow E11.2* codes in your incident diabetes code lists? Otherwise you build in half of confounding as you will have some association with exposure (hypothetical example of exposed to the cohort of diabetes vs. unexposed to the cohort of diabetes) and the outcome kidney disease if the outcome cohort includes the E11.2* codes. Have others thought about how codes could induce associations?
what about if you are doing a study of the prevalence of migraine in say december 2010 and folks have a ‘H/O’ the previous month? Would you dismiss that? Just to give you a clue on my motivation: it turns out that 4059193 H/O: migraine is the second most commonly used code in CPRD GOLD with almost 18,000 subjects, only second to ‘318736 Migraine’ with >380,000
so I am not so sure this is so easy, because if you dismiss this code you will be underestimating the prevalence of this disease… unless folks with this also have another code of course, which I do not know right now
in any case, this is the simplest of examples, but you have many similar situations like all the ‘resolved’ codes (e.g. 4037145 Epilepsy resolved), ‘remission’ codes (e.g. 4310821 Bipolar disorder in remission), relapse codes, the ‘medication review’ (e.g. 4292207 Epilepsy medication review) or the complication codes. Most of these are in the top 5/top 10 codes used for each of these conditions in CPRD GOLD, and all share the same problem: index date misclassification.
However, they do provide important information that in universal longitudinal healthcare systems like the UK NHS or the Spanish SNS are recorded upon registration. Dismissing these as cohort entry criteria will likely underestimate prevalence in many instances in European data
i do not have permissions to give you the exact number, but I can tell you I see >10,000 people. And see you get >4,000 cases. It is likely that the 3 where you see a 0% are US-based or elsewhere-based claims data sources.
The motivation behind my question is that in some healthcare systems people are asked to report all their health problems, etc upon registration. This is common practice in UK, Spanish, and Italian primary care, and it is to be expected that some healthcare professionals will use the “right” or “best” code, which in this case could be the “H/O” or related
Although this might be less relevant for other types of studies, I am not ready to dismiss this information for descriptive epi or drug utilisation studies, where e.g. a patient prescribed a med for migraine prophylaxis on registration (e.g. because they transferred out from somewhere else) would appear not to have an indication for that med if we dismiss the ‘H/O’ code