What are the unique benefits of OMOP CDM? Why should an organization adopt this model over others? What are its strengths and limitations? What are the strongest alternatives?
Tagging the author @Mark_Danese for further discussion but we have adopted the Generalized Data Model over OMOP because our organization is more interested in a simpler ETL. We are not interested in network studies, as OMOP is designed for.
hmmm. simpler ETL - but you just go from native model to a simpler-native-model.
It still remains native model and at-one-site model (unless you do that for more sources).
You can just leave the data in the first model.
It is like “EPIC raw” to “EPIC Caboodle”. (if my vague knowledge of EPIC sites is right).
You are still in non standard territory.
@Vojtech_Huser we have converted multiple SEER Medicare datasets, Medicare LDS datsets, and CPRD datasets into the Generalized Data Model (GDM). It’s great if you want to use native codes for your studies (which is a priority for us). @AndrewPayne, depending on the data use agreement (I’m not an expert), I believe we could share our ETL’s with you so you don’t have to reinvent the wheel
Hi @AndrewPayne - you should consider adopting OMOP CDM if one or more of these is true:
if you would like to standardardize on data model (OMOP CDM) and reference data (OMOP Standardized Vocabs) developed and supported by the international community of expertsl. As well as be able to get help and advise from the community on an ongoing basis
If you have multiple data sets and you do not want to write the same query in multiple times in different formats
if you want to be able to re-use free OHDSI tools and methods
if you would like to participate in OHDSI network studies
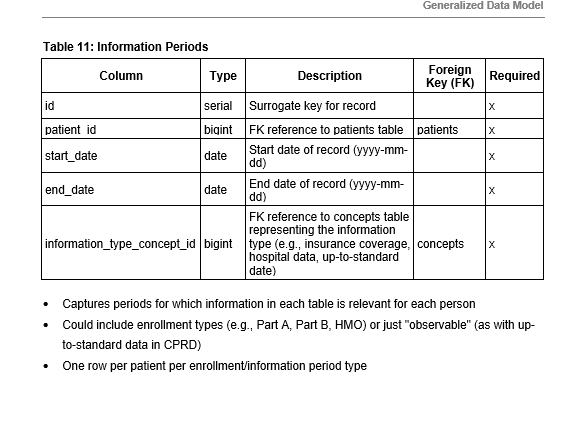
Hi @AndrewPayne - the first two points of @gregk’s list you can do with GDM. Since you have the paper, you can see that the GDM is a standardized model and you can use the standardized vocabs through the Mapping table. Also, you can use the GDM on multiple datasets so you are writing one query for multiple sets (I responded above that we have ETL’d SEER Medicare, Medicare LDS, and CPRD datasets into GDM). You cannot use the last two points with GDM - “re-use free OHDSI tools and methods” and “participate in OHDSI network studies”. However, if you rely on the native vocabularies or need a simple ETL, I would highly suggest GDM. Our tools work on GDM and it’s fantastic!
Just to make a couple of clarifying points so this doesn’t devolve into “X is better than Y”.
GDM was originally designed as a waypoint in the ETL process from raw data to the OMOP CDM. That is how we started – we wanted to try and make the OMOP ETL process easier. We wanted to be able to write an ETL specification document and then automatically operationalize the ETL specification “document”. In other words, we would run a program over the ETL spec and this would generate all of the code we need for the ETL. (This is a simpler explanation, but close enough for this discussion.) This is why we almost always use the OMOP concept ids in GDM. The logic is that with those, it should be a relatively straightforward process to move things to the OMOP structure once the concept ids are in place.
Another issue for us when we created GDM was that we were working with FDA Sentinel CDM projects at the time. So going from GDM both to OMOP and to Sentinel was much easier for us than doing full ETLs from raw for each one separately.
Once we got everything together, we realized that there were some reasons that, for us, it made more sense to use GDM as our data model. As @jenniferduryea mentioned, we prefer to use code lists specified in the source vocabulary and GDM is more focused on this approach. We also had some oncology data that didn’t really work well with OMOP at the time, and hence we shifted our approach to GDM for our internal software (Jigsaw).
Every data model has strengths and limitations, including GDM and OMOP. But these were designed with much of the same thinking. The fundamental difference is in our focus on the source vocabularies versus the standard vocabularies. This is likely related to the fact that we mainly use claims data and EHR and registry data with well-documented vocabularies (e.g., CPRD and SEER).
Also, keep in mind that the OMOP community is a great source of help and documentation. GDM was built by a small company that may, or may not, be able to provide detailed guidance in every situation.
@AndrewPayne, you picked a fun topic! You’re on the OHDSI Forums so you know what our bias is.
You need to know your use cases. What are you trying to do with your data?
IMHO, here’s the best examples of why adopt OMOP:
In the last month, we engaged 17 databases from across the globe (Netherlands, Spain, US, UK, China, South Korea) to execute a package that aims to describe the baseline demographic, clinical characteristics, treatments and outcomes of interest among individuals tested for SARS-CoV-2 and/or diagnosed with COVID-19 compared to Influenza patients from 2017-2018. How did it work? We’re all on the OMOP CDM which includes using the OMOP Standard Vocabularies. We shared code via the OHDSI GitHub and captured results via a SFTP server we sent tokens out to data partners to upload to.
The NIH is running the National COVID Cohort Collaborative to improve the efficiency and accessibility of analyses with COVID-19 clinical data, expand our ability to analyze and understand COVID, and demonstrate a novel approach for collaborative pandemic data sharing. The program harmonizes data submissions from all major CDMs (OMOP, PCORNet, i2b2/ACT, TriNetX) into a central OMOP CDM V5.3.1 in a secure enclave for researchers.
Not just for data, but you can also use our tools and methods library. There’s a lot of utility here beyond the physical harmonization and standardization of source data.
If you’re looking to be part of a global research initiative with increasing adoption, look no further.
You can support multiple models in a local environment (many people do this today) but it’s ultimately your use cases that drive what’s of highest value for your investment.
@jenniferduryea: Hi Jennifer,
I saw your post on the OHDSI forum recommending the Generalized Data Model and found it fitting to our use case as well. My research integrating real world data and cdisc data for PRCTs. If you can share the ETL (EHR,Claims,SEER) into the GDM, reinventing the wheel would not be done. Thank you!