
@Frank benevolent dictator - Follow-up discussion after the wonderful tutorial you and others led at the 2017 Symposium.
How are the OHDSI tables created:
- CDM tables created using DDL scripts
- OHDSI schema and Results schema created by Flyaway.
Use case: when an instance has to be deployed over multiple DBMS for various reasons such as when primary platform
- does not fully support the Hibernate ORM
- does not support sequence function to obtain the cohort_definition_id or concept_set_id etc.
- Here one platform maybe considered the primary platform (redshift) and the other a secondary platform. During computation ‘Joins’ may not happen between data from primary platform to data in secondary platform. Patient level data has to be on primary platform.
What needs to be solved: Confusion occurs when deploying over multiple platform (e.g. Amazon Redshit and PostGres). Almost all computation tasks run on the primary platform (Redshift like MPP systems)
What is needed: Documentation for each table as to what table maybe
- only deployed in primary platform
- maybe deployed in either primary or secondary platform.
- finally update this page
Also needed: some brief description of the non-CDM tables created by FlyAway.
I started this process - maybe as a community we could complete them? Once we have created a final version - we can post it in the documentation section of CDM Github page?
Can we update the spreadsheet here - Editable version
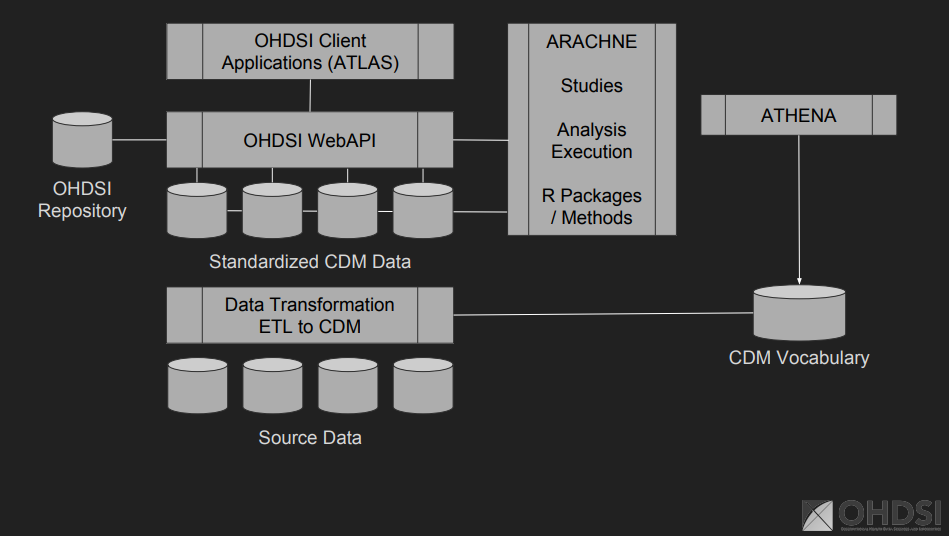
Source schema:
- contains source data
- in native schema of source data
CDM schema:
- All standardized data and tables in CDM schema
- Has to be on the primary platform
- Contains patient level data
- Read only, only changed during ETL.
- All the CDM tables are here and includes the vocabulary-tables.
- One correction: ‘Cohort’ table is currently considered a CDM schema, but this is legacy from CDMv4 retained in CDM v5 to ensure backward compatibility StandardizedDerivedElements. There is a proposal to CDM workgroup to take it out of future version CDM v6. (@Frank and @clairblacketer where? cant find it - maybe it is lost? Is it this one? or this one . Maybe combine them into one issue and repost. no table name should be re-used across schemas)
Results schema
- Output from CDM schema are inserted into Results-schema
- Has to be in the primary platform when output from CDM schema needs to be inserted into Results schema
- Derived, may contain patient level data (e.g. cohort) or summary statistics
- include tables for achilles results, cohort generation, heracles results, estimation results, etc.
- for every CDM schema there is one dedicated results-schema.
- For example, a read-only schema with CDM data may be in schema
dataA. To allow (for example for Achilles) to write to result tables (e.g., achilles_results table), a corresponding schema (with write privileges) would bedataA_results. OHDSI software tools do not try to manage various datasets, they rely on separation of results by simply separate database result schemas for each dataset. So, if you have a CDM in schema ‘dataA’ and it is read-only, you can create a new schema ‘dataA_results’ that is writable, and when you execute Achilles, specify dataA as the cdm_database_schema and dataA_results as the results_database_schema.
OHDSI schema
- administrative schemas
- The OHDSI Platform Metadata that describes the concepts and processes that were used to derive the results schema from the CDM schema are stored in the OHDSI schema.

Source Data: Person level data that is acquired through different parts of the healthcare system. These sources are said to exist in the “native schema”.
Standardized Data: Data that has been converted into the OMOP CDM format. These data are said to exist in the “CDM schema”.
Derived Data: Data that is the result of some form of processing on data that came from the OMOP CDM format. These data are said to exist in the “results schema”. Most of these data are aggregate summary statistics. Exceptions are Cohort table that contains subject_id.
OHDSI Platform Metadata: Metadata that is created or maintained to describe a concept, process or system function within the broader OHDSI architecture. These data are said to exist in the “OHDSI schema”.
Reference
@Frank Can we create a new OHDSI ‘architecture’ repository in GitHub? The wiki pages in ohdsi.org for architecture are confusing to navigate. e.g. i cant get to the pages referenced from here