OHDSI Phenotype Phebruary - (in aPHril) 2026
Phenotype Phebruary (this year in aPHril) represents our community’s collective effort to advance the field of phenotyping in observational studies, backed by our desire for continuous learning and the integration of cutting-edge AI technologies. This year, we are bridging the gap between traditional rule-based methods and agentic AI workflows.
The Phenotype Workgroup’s 2026 OKRs focus on advancing the science of AI-assisted systematic phenotyping (in collaboration with the AI Workgroup) while simultaneously standardizing metadata to ensure that phenotype definitions are findable, accessible, and reproducible across the global OHDSI network.
Phenotype Phebruary 2022 Homepage
Phenotype Phebruary 2023 Homepage
Phenotype Phebruary 2024 Homepage
Phenotype Phebruary 2025 Homepage
Why Do We Conduct Phenotype Phebruary (in aPHril)?
Community Engagement and Collaboration
- Dedicated time for collaborative focus on the “Gold Standard” of phenotyping.
- Fosters engagement between clinical investigators, data partners, and the Generative AI workgroup.
- Inclusive environment for both traditional epidemiologists and AI developers.
Advancement in Phenotyping Science
- Benchmarking iterative, empirically grounded, AI-assisted workflows across diverse RWD network sources.
- Evaluating the performance of Large Language Model (LLM) adjudication against traditional chart review.
- Populating the OHDSI Phenotype Library with high-fidelity clinical definitions.
Education and Practice
- Training on the use of modern OHDSI tools like KEEPER LLM (https://github.com/OHDSI/Keeper) and the Study Agent (https://github.com/OHDSI/StudyAgent).
- Standardizing metadata ontologies to ensure cross-network reproducibility.
What We Aim to Achieve in Phenotype Phebruary (in aPHril) 2026
The Clinical Use Case: Acute Myocardial Infarction (AMI)
We will focus on the full continuum of algorithms for Acute myocardial infarction. We will move from simple 1-code definitions to highly specific multi-criteria phenotypes, differentiating between new episodes and chronic history.
The “One-Iteration” Challenge
To keep participation high-value and low-stress, we are asking for one iteration from the community (you may submit as many cohort definition variants as you want - but we will only iterate once). We will provide reference definitions and “seed” cohorts built live; your challenge is to use our new tools to improve upon them.
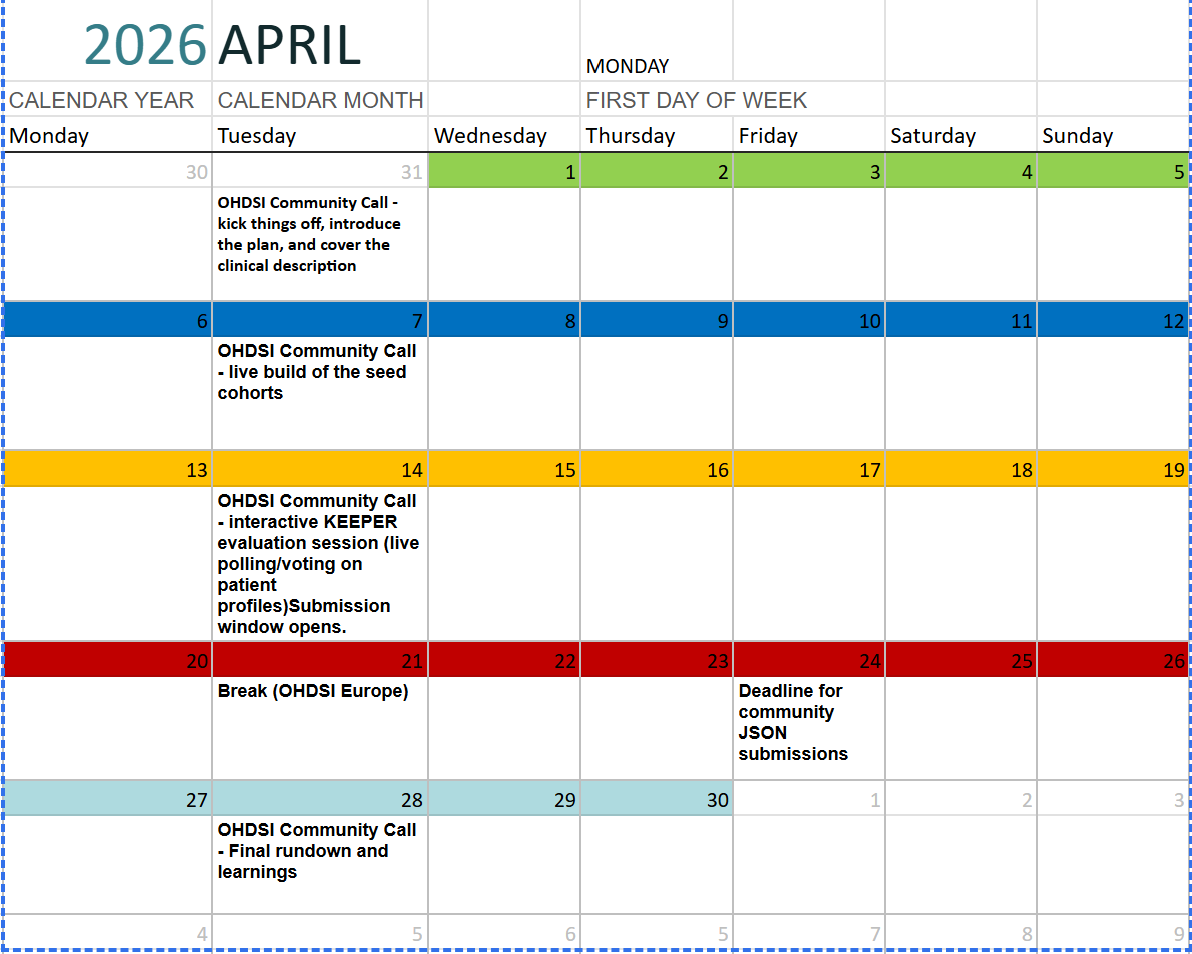
Scheduled Activities and Milestones
All activities will be synchronized with our Tuesday Community Calls and Phenotype Workgroup meetings:
- March 31: The Kick-off. Introduction of the plan, clinical description of Acute Myocardial Infarction, and overview of the 2026 OKRs. [lead: Patrick Ryan]
- April 7: The Seed Build. Live build session of the seed cohorts using ATLAS. [lead: Gowtham Rao]
- April 14: KEEPER Evaluation & Submission Open. Interactive session using LLM-enabled KEEPER outputs for live polling and profile adjudication. Submission window officially opens. [lead: Martijn Schuemie]
- April 21: Break. (OHDSI Europe Symposium).
- April 24: Submission Deadline. All JSON cohort definitions due.
- April 28: Final Rundown. Summary of learnings, performance benchmarks (PPV/Sensitivity), and showcase of the top-performing AI-assisted phenotypes. [lead: Azza Shoaibi and Gowtham Rao]
Ways to Contribute
There are many ways to get involved, regardless of your technical background or data access:
| Contributor Group | Opportunity | Timing |
|---|---|---|
| Data Partners | Run CohortDiagnostics (CD) on predefined phenotypes and publish results to the shared Shiny app | April 14 |
| Data Partners | Run KEEPER, generate patient profiles, and perform manual adjudication | April 14 |
| Data Partners | Run LLM-enabled KEEPER and generate outputs for AI-based adjudication | April 14 |
| Data Partners | Run other shared evaluation tools (e.g., KEEPER variants, PheValuator) | April 14 |
| Phenotype Developers | Submit Acute Myocardial Infarction (AMI) definitions for evaluation | April 14–24 |
| Phenotype Evaluators | Use available tools to evaluate submitted cohort definitions | April 24 |
| Clinical Collaborators | Help adjudicate a sample of KEEPER patient profiles | April 14 |
| Everyone | Adjudicate 5–10 cases during open community calls | Scheduled Calls |
| Everyone | Attend Phenotype April community calls and learn the workflows | Throughout April |
| Everyone | Attend and reflect on learnings during the final wrap-up call | April 28 |
How to Participate and Submit
We want to make participation as frictionless as possible.
- Build: You can use atlas-demo.ohdsi.org to create your cohort, or use your own local ATLAS instance.
- Submit: Once you have refined your cohort for Acute Myocardial Infarction, export the JSON file and email it directly to rao@ohdsi.org.
- Collaborate: Join the Phenotype Development and Evaluation Workgroup calls for ad-hoc working sessions between community updates.
Details of the 2026 Collaborative Study
Phenotype Representation & Agentic Support
We will explore the use of “Librarian Agents” that operate on top of the Phenotype Library using the Model Context Protocol (MCP). We aim to identify how AI can help researchers interpret clinical descriptions and translate them into robust R code (Caper) or ATLAS JSON.
Validation via KEEPER LLM
A primary objective is to assess the reliability of AI-extraction tools. Participants will see how LLM agents can summarize complex patient profiles and provide adjudication evidence, significantly reducing the burden of traditional manual chart review while maintaining high specificity.
Join the Journey!
Whether you are a clinical expert, a data scientist, or an AI enthusiast, Phenotype aPHril is your chance to help shape the future of evidence generation in OHDSI.
Supersedes: Phenotype Phebruary 2026 (see aPHril thread)