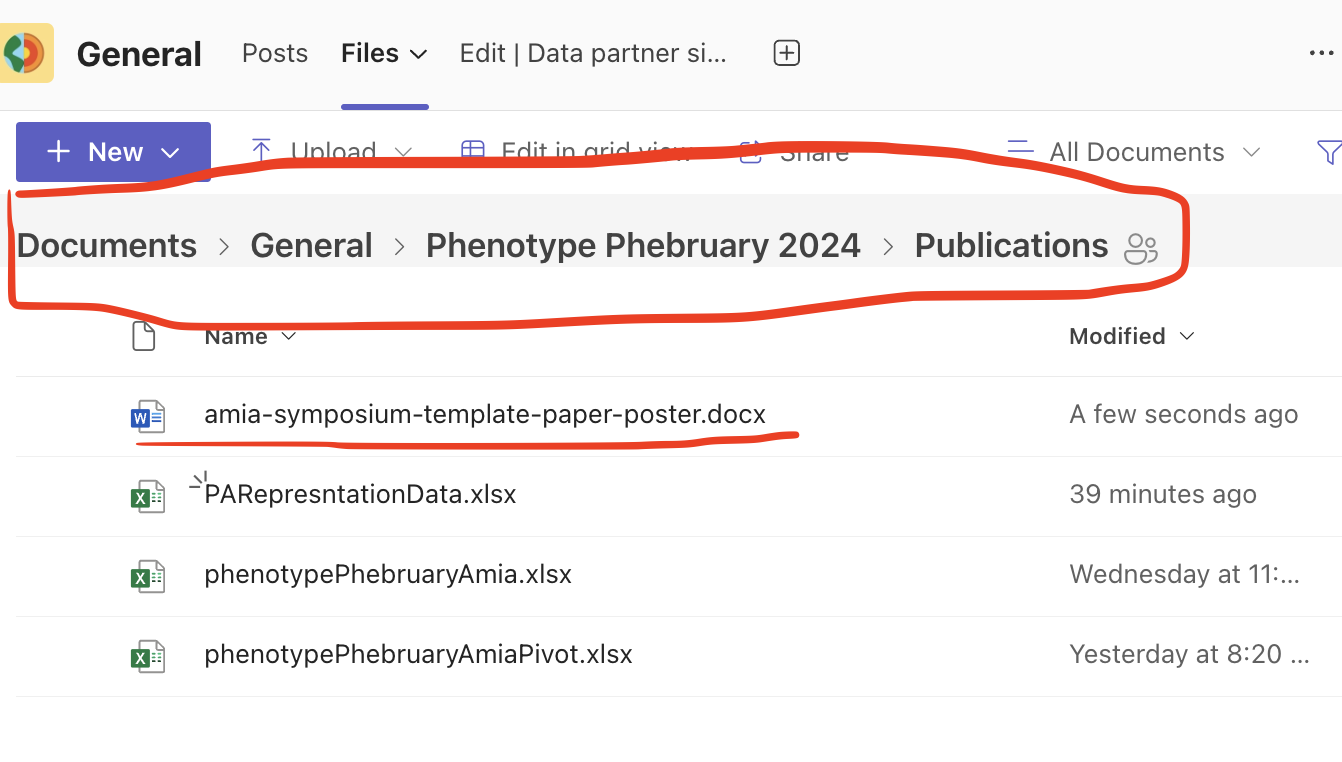
Generated using GPT
Update on Dermatomyositis Project Led by Dr. Christopher Mecoli
Today, we focused on updates regarding Dr. Christopher Mecoli’s Dermatomyositis project. Find the latest protocol version here and see the IRB approval status and local testing updates in this forum discussion.
Executive Summary:
-
Study Leadership: Dr. Christopher Mecoli leads the project, which aims to evaluate and validate various Dermatomyositis (DM) phenotypes across multiple OMOP databases.
-
IRB Approval and Local Testing: Awaiting IRB approval, plans are in place for local testing of the R package at participating sites. This will include a review phase to refine the package based on feedback.
-
Data Sources: The study leverages a multinational cohort from the Johns Hopkins Myositis Center and other databases, involving about 1,500 patients.
-
Methodology: The methodology combines manual chart reviews at Johns Hopkins to measure algorithm performance and uses the PheValuator to estimate performance across databases.
-
Technical Discussions: Will Kelly addressed challenges in data integration and emphasized maintaining robust scripts across different database configurations. Cohort definitions are managed using the Web API to ensure data security.
-
Feedback and Iterative Improvements: The study welcomes ongoing feedback to enhance execution, with technical adjustments planned based on collaborative input.
-
Next Steps:
- Further running of the study script in varied environments to verify adequate sample sizes.
- Future community work group calls are planned to discuss technical issues and progress, including a presentation by the Department of Veterans Affairs.
- Continued collaboration and communication among study partners to maintain high standards of data quality and research integrity.
In-Depth Discussion by Dr. Christopher Mecoli:
Background and Objectives:
-
Disease Focus: The study targets Dermatomyositis, a rare autoimmune condition.
-
Research Challenges: DM’s rarity makes robust studies difficult, particularly at single centers.
-
Leveraging the OHDSI Network: Utilizing the OHDSI tools, the study evaluates DM phenotypes to improve research reliability across real-world data sources.
Methods:
-
Data Utilization: Uses data mapped to the OMOP Common Data Model from various sources.
-
Algorithm Evaluation:
-
Johns Hopkins Cohort: Gold-standard manual chart reviews confirm DM diagnoses.
-
Broader Evaluation: PheValuator assesses phenotype performance across multiple databases without direct patient chart access.
Study Execution:
-
Federated Analysis: Sites run analyses locally, sharing only aggregate results, ensuring data confidentiality and governance compliance.
Additional Points from the Technical Discussion:
Will Kelly discussed the technical execution of the study script and the importance of data privacy and appropriate configurations across databases. He also addressed the integration challenges and the use of tools like R and Web APIs in managing and analyzing data, underlining the necessity of adaptability and feedback incorporation into the study’s methodologies.
**Dr. Christopher Mecoli **
Dr. Christopher Mecoli discussed a study on dermatomyositis (DM) in the meeting, emphasizing its rationale, objectives, and methods. Here’s a summary based on his discussion and additional content from the provided document:
Background and Rationale:
-
Disease Focus: The study focuses on dermatomyositis, a rare chronic autoimmune disease affecting muscles and skin, leading to significant morbidity and mortality.
-
Research Challenges: Due to its rarity, studies on DM often lack sufficient power for causal inference, especially those conducted within single centers.
-
Current Limitations: Traditionally, DM algorithms for identifying patients have been limited to single data sources, affecting the generalizability and reproducibility of results.
-
Leveraging OHDSI Network: By using the Observational Health Data Sciences and Informatics (OHDSI) network and its tools, the study aims to evaluate DM phenotypes across multiple real-world data sources to enhance the reliability and applicability of research findings.
Objectives:
-
Primary Objective: To evaluate and validate various DM phenotypes across different OMOP databases.
-
Secondary Objectives: Raise awareness of OHDSI and the OMOP model within the clinical rheumatology community and demonstrate the potential for conducting large-scale network studies on rare diseases like DM.
Methods:
-
Data Sources and Study Design: The study will utilize multinational cohort data mapped to the OMOP Common Data Model, sourced from electronic health records, insurance claims, and registries.
-
Algorithm Evaluation:
-
Johns Hopkins Cohort: Perform gold-standard manual chart reviews on the Johns Hopkins Myositis Center cohort to assess algorithm performance, including sensitivity, specificity, and predictive values.
-
Broader Evaluation: Use PheValuator, a probabilistic tool, to estimate performance across multiple databases, allowing assessment of phenotypes without access to patient charts directly.
Phenotypes of Interest:
- A variety of DM phenotypes have been developed, utilizing OHDSI’s ATLAS tool. These phenotypes are carefully constructed based on existing literature and refined to ensure accurate representation and diagnosis of DM.
Study Execution and Data Handling:
-
Federated Analysis: Sites will run the study analysis package locally, with only aggregate results shared, ensuring patient data confidentiality and compliance with local governance standards.
Strengths and Limitations:
-
Strengths: Utilizing a network such as OHDSI and the standardized OMOP CDM improves the study’s reach and applicability, making findings more robust and generalizable.
-
Limitations: There are inherent challenges in using EHR data for DM research, including potential inaccuracies in disease onset dates and variability in how data is converted to the OMOP model.
This study is positioned as a significant step forward in using real-world data for researching rare diseases, potentially setting a precedent for future research in rheumatology and other fields.
Dr. Christopher Mecoli described using a variety of data sources for the study on dermatomyositis, specifically focusing on large-scale, real-world data. Here are the specifics mentioned about the data sources:
-
Johns Hopkins Myositis Center Cohort:
-
Registry Data: This cohort includes data from the Johns Hopkins Myositis Center, which has been systematically collected and managed within a registry.
-
Number of Patients: Approximately 1500 patients are included in this cohort.
-
Data Details: The registry data from 2016 onward has been converted to the Observational Medical Outcomes Partnership (OMOP) common data model. Systematic and detailed chart reviews have been conducted to confirm DM diagnoses, with both symptom onset and diagnosis dates recorded.
In the discussion, Dr. Christopher Mecoli and other participants elaborated on the process of conducting manual chart reviews, particularly focusing on distinguishing true positive and false positive diagnoses of dermatomyositis within their study cohort. Here are the key points from that discussion:
-
Gold Standard Chart Review:
-
Purpose: The chart review at Johns Hopkins Myositis Center is used as a gold standard to validate the accuracy of dermatomyositis diagnosis and to evaluate the performance of various DM algorithms developed for the study.
-
Details: The chart review encompasses systematic evaluations of clinical records to confirm DM diagnoses based on validated classification criteria (e.g., ACR/EULAR 2017).
-
True Positives:
-
Definition: Patients who are confirmed to have dermatomyositis based on the chart review and meet the diagnostic criteria accurately.
-
Data Utility: These cases help ascertain the sensitivity and positive predictive value of the diagnostic algorithms being tested.
-
False Positives:
-
Definition: Individuals who were initially suspected to have dermatomyositis or incorrectly diagnosed but were determined not to have the condition upon further review.
-
Concerns Discussed: The presence of false positives is critical for understanding the specificity and negative predictive value of the algorithms. It’s important for refining the algorithms to reduce misclassification errors.
-
Registry Data: Dr. Mecoli mentioned that they keep track of individuals who were suspected of having dermatomyositis but were confirmed not to have it through further diagnostic processes. This data is essential for assessing the rate of false positives.
-
Challenges in Reviewing Non-Cases:
-
Difficulty in Manual Adjudication: One of the challenges highlighted was the lack of systematic chart reviews on non-cases, which are essential for a comprehensive evaluation of the specificity and to refute false negatives.
-
Resource Intensity: Conducting manual chart reviews on a large scale, especially involving non-cases, is resource-intensive and often not feasible in many studies.
-
Implications for Future Research:
-
Enhancing Algorithm Accuracy: By identifying true and false positives, the research team can refine the diagnostic algorithms to improve their accuracy, making them more reliable for broader application across various healthcare datasets.
-
Understanding Diagnostic Challenges: Discussions around true and false positives help illuminate the complexities and nuances in diagnosing dermatomyositis, which can guide future clinical and research strategies.
The discussion underscores the importance of meticulous chart reviews in validating disease algorithms and highlights the challenges and considerations in accurately identifying and documenting disease presence or absence in research studies.
During the meeting, Will Kelly contributed several technical insights and clarifications regarding the study’s implementation and data management. Here are the key points discussed by Will Kelly:
-
Technical Execution:
-
Script Execution: Kelly discussed the execution of the study script, emphasizing the importance of ensuring that the setup is configured correctly by the sites before running the analysis.
-
Data Handling: He explained how the data should be handled, particularly emphasizing the need for sites to run the analysis locally while ensuring data privacy and governance compliance.
-
Database Configuration and Issues:
-
Database Diversity: Kelly noted the variety of database configurations across different sites and how they might impact the study’s execution, stressing the need for flexibility in handling diverse data structures.
-
SQL Server Configurations: He mentioned the specific configurations used at Johns Hopkins and how they might differ from other sites, potentially requiring adjustments.
-
Challenges in Data Integration:
-
Integration of Data: Kelly discussed challenges related to integrating data from different sources, particularly when mapping them to the OMOP common data model. He highlighted the importance of consistency in data handling to ensure the reliability of study results.
-
Software and Tools:
-
Use of R and Web API: Kelly discussed the use of R programming and web APIs for data analysis and mentioned some of the tools used for managing and executing the study protocol.
-
OHDSI Tools: He elaborated on the use of OHDSI tools, like ATLAS, for creating and managing phenotypes, which are crucial for the study.
-
Future Considerations and Improvements:
-
Feedback on Script Improvements: Kelly was open to feedback regarding the scripts and methods used in the study, indicating a willingness to make necessary adjustments based on the collaborators’ input to enhance the study’s effectiveness.
-
Addressing Technical Queries:
-
Clarifications Provided: Throughout the discussion, Kelly responded to technical queries from other participants, providing clarifications on how certain aspects of the study’s technical setup were handled.
During the meeting, there was a detailed and technical discussion among Will Kelly, James Weaver, Joel Swerdel, and Gowtham Rao concerning various aspects of the study’s execution, the tools used, and data management practices. Here’s a breakdown of their conversation:
-
Discussion on Cohort Definitions and Web API:
-
Weaver raised concerns about cohort definitions and their management using Web API, emphasizing the need to ensure consistency across sites to avoid discrepancies in study results.
-
Kelly responded by discussing the technical handling of cohort definitions, including how they were managed and accessed via the Web API. He acknowledged the need for clarity and control in managing these definitions to prevent accidental modifications that could affect study results.
-
Use of RDA Files and JSON Objects:
-
Weaver and Joel Swerdel inquired about the use of RDA files and the possibility of using JSON objects instead for more transparent and manageable data handling.
-
Kelly discussed the pros and cons of using serialized R objects versus JSON, explaining the technical reasons for their choices and how they could consider transitioning to more transparent data formats if it proved necessary for the study’s integrity.
-
Technical Challenges and Solutions:
-
Kelly detailed some of the technical challenges they faced, particularly relating to the script’s execution across different data environments, and how they intended to address these challenges through script modifications and rigorous testing.
-
Gowtham Rao emphasized the need to ensure the study script was robust and reliable across various data settings, urging Kelly to incorporate any necessary changes to improve script performance and reliability.
-
Security and Data Sharing Concerns:
-
Joel Swerdel discussed concerns related to data security, particularly the mechanisms through which data were shared and the precautions needed to ensure data privacy and compliance with regulations.
-
Kelly reassured the group about the steps taken to ensure data security, such as using secure methods for data transmission and ensuring that all data sharing complied with relevant guidelines and regulations.
-
Feedback and Future Improvements:
-
Gowtham Rao suggested that the team remain open to feedback on the study’s technical processes and consider any modifications proposed by study collaborators to enhance the study’s effectiveness and efficiency.
-
Kelly was receptive to feedback and expressed a commitment to iterative improvements of the study’s technical infrastructure based on collaborative input and the evolving needs of the study.
Overall, the discussion highlighted the collaborative effort to address technical and operational challenges in the study, ensuring that the data handling and analysis procedures were not only efficient but also secure and compliant with best practices and regulations.
The discussion around next steps in the meeting focused on several action items to ensure the study’s progress and address the technical challenges highlighted during the session. Here are the key next steps that were outlined:
-
Running the Study Script in Different Environments:
-
Evan Minty mentioned the intention to run the study script at Stanford and other participating sites once more data was gathered on the number of available cases, to ensure sufficient data for meaningful analysis.
-
Gowtham Rao suggested that both Johnson & Johnson (J&J) and Stanford should asynchronously run the script using the public Atlas to verify cohort counts. This would help confirm if there is an adequate sample size to proceed with the planned analyses.
-
Feedback on Script and Package Adjustments:
-
Will Kelly was tasked with incorporating feedback and making necessary adjustments to the study package to address the technical issues discussed, such as managing cohort definitions securely and ensuring the script’s robustness across different data environments.
-
Weaver, James [JANUS] proposed running the script in J&J’s environment to identify any potential issues, with the goal of sharing findings and recommendations for refining the script.
-
Review and Update of Technical Processes:
-
Kelly and other technical team members were to review and possibly revise the data handling and analysis processes, especially the integration and management of cohort definitions using Web API and other tools.
-
Addressing IRB and Ethical Considerations:
-
Christopher Mecoli mentioned that IRB approvals were pending and necessary for proceeding with certain aspects of the study. Updates on the IRB approval process were to be shared in subsequent meetings.
-
Future Meetings and Discussions:
-
Gowtham Rao suggested scheduling future community work group calls to continue discussions on technical issues and study progress. He mentioned setting aside time in the next meeting for a presentation by the Department of Veterans Affairs as well as continuing to focus on the ongoing study.
-
Collaboration and Communication:
-
Kelly and Gowtham Rao emphasized the importance of ongoing collaboration and open communication among all study partners to address any emerging challenges and to ensure the study adheres to high standards of data quality and research integrity.
These steps reflect a comprehensive plan to move forward with the study while addressing the complexities of working with real-world data across multiple sites and ensuring the technical infrastructure supports the study’s objectives effectively.