Currently our source data has some discrepancies with the visit_ids. For instance, the data looks like below (same visit_ids for subsequent related visits). Please note that accompanying clinical data also has visit_ids as shown below
Person_id
Visit_start_date
Visit_end_date
Visit_id
1
21/11/2008
23/11/2008
A1
1
28/3/2009
28/3/2009
A1
1
27/5/2010
29/5/2010
A1
But the actual data should have been like as below (where visit_ids is supposed to indicate the chronological order (so we can know it is related))
Person_id
Visit_start_date
Visit_end_date
Visit_id
1
21/11/2008
23/11/2008
A1-01
1
28/3/2009
28/3/2009
A1-02
1
27/5/2010
29/5/2010
A1-03
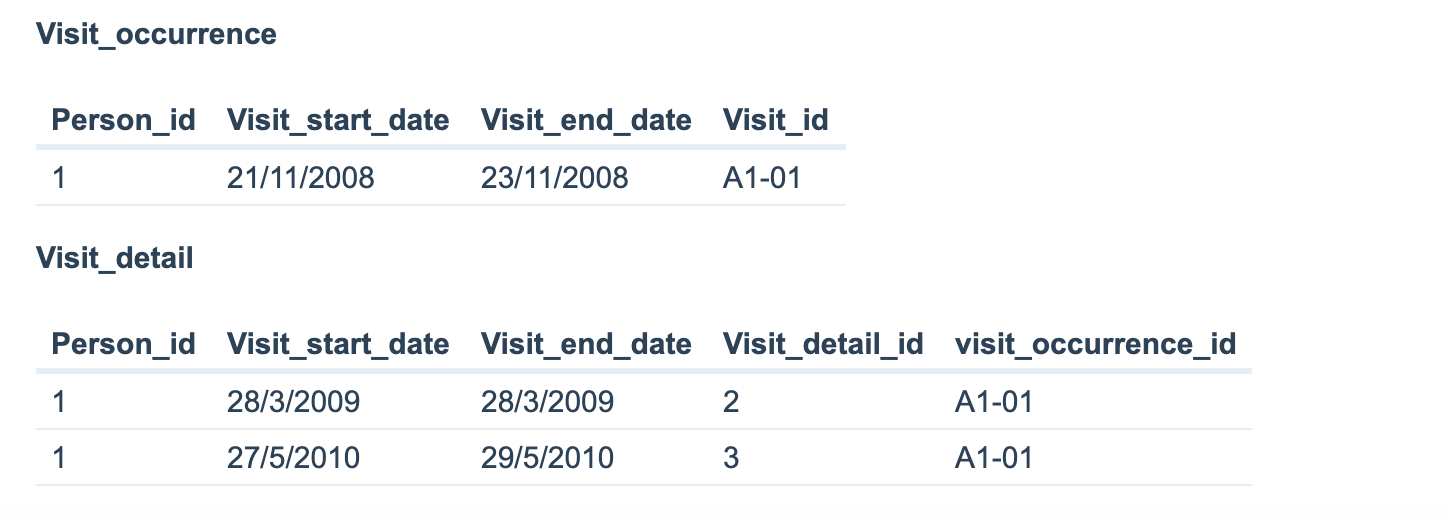
Since our data looks like as shown in Table 1 above (with visit_id issue), We decided to store the data as shown below (in visit tables as shown below - let’s not worry about field format for now as I would like to explain with simple example. Hence I have chosen A1-01 etc)
Visit_occurrence
Person_id
Visit_start_date
Visit_end_date
Visit_id
1
21/11/2008
23/11/2008
A1-01
Visit_detail
Person_id
Visit_start_date
Visit_end_date
Visit_detail_id
visit_occurrence_id
1
28/3/2009
28/3/2009
2
A1-01
1
27/5/2010
29/5/2010
3
A1-01
I know visit_detail allows to store only transfers within a single visit. We didn’t use episode tables yet because we are in CDM V5.3.1 and I think Atlas and all other ohdsi packages support V5.3.1 very well when compared to V6.0.
a) So, would this result in any problem during Atlas cohort generations?
For ex: I know in Atlas, when we generate cohorts, the Atlas would run some SQL in the background to get concept_hieraracy etc. If I am about select only visit_occurrence, would Atlas be able to pick the child visits from visit_detail table as well (because we have linking visit_occurrence_id in Visit_detail table) or I have to select visit_detail table seperately.
b) Would this result in any problem during usage of other R packages (HADES)? let’s say for ex: in real data, we may have 100 records (with quality issues as described above). But we store first visits (in visit_occurrence) which would be 40 records and child visits in visit_detail which would be 60 records. So, for all analysis, we want these 100 records (from both the tables to be considered and not just visit_occurrence)
c) We don’t wish to tamper the original information where each visit and corresponding clinical information each visit can be identified easily using visit_ids (A1). If we were create our own visit_ids from scratch,we have settle for some heuristic where we assign visit_ids by some date time intervals (which may not be good/accurate)
@MPhilofsky@Chris_Knoll - Can I seek your inputs on this type of EHR data transformation and impact of such transformation on Atlas usage or HADES usage? Thanks for your help in advance
Correct. So, the below is not the correct use of the Visit Detail table. Visit detail id 2 and 3 are not part of 1. From the information you gave, these appear to be 3 separate visits and should be represented in the Visit Occurrence table as such.
If you need to keep the ‘A1’ value, I suggest you put it in the visit_occurrence.visit_source_value field or create an extension column for this information.
Both of these methods will allow you to keep the original source value while at the same time it won’t “break” the CDM or result in any errors by having a non-unique visit_occurrence.visit_id. Neither visit_occurrence.visit_source_value nor an extension column will not be used by Atlas, but visit_details records are not used by Atlas currently.
If you just need to retain the information all three visits are linked together, then use the Fact Relationship table to link the visits.
The Fact Relationship table is not used by Atlas
I understand you want to link your clinical events to the visit. And the CDM only allows one FK from a clinical event table to the Visit Occurrence table. One way to do this would be to link a clinical event to a visit occurrence when the date of the clinical event is the same as the date of the visit.
What is your use case? I might be able to give more suggestions if I know what you are trying to accomplish
@MPhilofsky - We haven’t not gotten that far (use-case level) yet. Our visit data is basically not in a form supported by visit_occurrence guidelines
While our visits are not within a single visit but they all are definitely related (so cannot store as seperate visits). Meaning a patient visited hospital for a condition T2DM on 23/11/2008 (A1-01), he may have a follow-up visit for the same condition like few months later. Like doctor advised him to visit after 3 months or due to development of some complications he came to hospital again (and hospital staff tied his current visit to his previous visit (A1-01) because they are related (due to disease/consultation reason).
Since, we want to use all this visit information in Atlas and also retain the relationship present in our original data (meaning parent visit (A1-01) and subsequent related visits (A1-02, A1-03)), then only option is to use Episode tables? (though Atlas don’t support them yet). Does Episode tables fit our purpose do you think?
The why (the use case) determines the how. What is the question you are trying to answer? This will help to determine to the best way store your data in the CDM AND if the question you are asking can be answered by Atlas. Atlas is an amazing tool for doing network research, however, by your question, it sounds like you have an internal use case for these data.
As you state, the 3 visits in your example are separate, therefore, they all need separate records in the CDM. Don’t force the data into the CDM by altering the meaning of the CDM tables or fields. It confuses the end users and might cause wrong interpretation of the data.
The Fact Relationship, Visit Detail and Episode tables are not used by Atlas. You can put your original source value into the visit_source_value field or create an extension column to store these data. However, neither are used by Atlas.
ETLing source data to the CDM is very complex. There are many competing factors. However, it is of utmost importance to find the use case, talk to the researchers who use the linkage between the visits to do research, find the question, then we can help you find the best solution or let you know if it’s just not possible.