Apologies if this has been done in another topic (if so I couldn’t find it) but we’re interested in how to model some of our NLP-derived facts in NOTE_NLP - specifically, NLP-derived numeric values.
For some of our NLP work, the mapping is relatively straightforward. For example, we have an existing pipeline to extract ICD-9 and ICD-10 codes from pathology reports - here, we can just map the CONCEPT_ID for the ICD-9/10 code to note_nlp_source_concept_id and then use CONCEPT_RELATIONSHIP to determine the standard code, and insert that as note_nlp_concept_id.
However, some of our NLP pipelines extract numeric values from freetext - for example, we have one in place that extracts numeric PHQ-9 values, and one that extracts LVEF from echocardiogram reports. There don’t really seem to be any concepts, standard or otherwise, for these continuous variables, e.g. “PHQ-9 value of 15.”
Our initial plan was to use a CONCEPT_ID corresponding to the measurement as the note_nlp_concept_id, then simply insert the extracted value as lexical_variant. However, I’m curious to hear how others have approached this issue - I’m sure we’re not the first to encounter it.
I’m also interested in this, since we are also in need of representing concepts + numeric values extracted through NLP. In our case, we have developed some extensions of the tables in order to do this, but I’d love to see how others have approached the problem. Also, I have the feeling that the note_nlp table is a bit limited and needs some work on it.
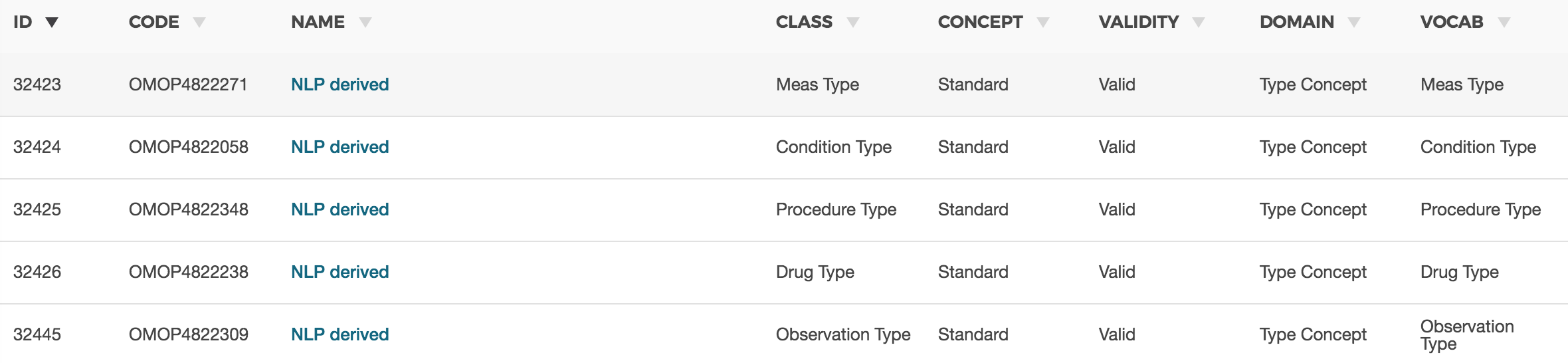
This does not address note_nlp metadata, but in terms of storing extracted concepts this is what we did for ClarityNLP. We made an exporter that would write out to OMOP to the desired table and would automatically assign one of these concept_type codes depending on the domain.
This is not something you would want to do unless you were certain that your NLP output is ready for prime time (ie real tables, not note_nlp).
I have talked about making a proposal to modify the NOTE_NLP table to address this issue. In line with @jon_duke’s idea of storing the NLP-derived facts in their proper domain tables and using type_concepts to distinguish provenance and confine the NOTE_NLP to metadata. See prior discussion here:
I just have not made time to write up the proposal. But I still think it is the right direction.
@mgurley, we will be more than happy to write a proposal. Can you provide us some guidance on the process we should follow ? Maybe point us to documentation to the procedure we should follow ?
One update to my prior fourm post, I would propose using the column names NOTE_NLP.nlp_event_id and NOTE_NLP.nlp_event_field_concept_id for the polymorphic column paring. Instead of NOTE_NLP.note_nlp_event_id and NOTE_NLP.note_nlp_domain_id. This is in line with the new convention for these kinds of polymorphic colums. See here:
Here is the CDM Github repo where you can make a proposal. See prior proposals to crib a format:
One issue that I had not quite thought through was if you want to represent a negated fact (which is often done in NLP pipelines), you probably don’t want to put that in a clincial event table. Currently negated facts and other modifiers can be clumsily represented in the NOTE_NLP.term_exists, NOTE_NLP.term_temporal and NOTE.term_modifiers. Perhaps an alternative proposal would be to still add the
NOTE_NLP.nlp_event_id and NOTE_NLP.nlp_event_field_concept_id columns
but as NULLABLE and not remove the
NOTE_NLP.note_nlp_concept_id and NOTE_NLP.note_nlp_source_concept_id columns. This way if you want to still represent a negated fact in NOTE_NLP you can but if you want to represent a high-certainty clinical event you would make an entry in the appropriate clinical event table and link it to the NOTE_NLP table using the new NOTE_NLP.nlp_event_id and NOTE_NLP.nlp_event_field_concept_id columns.
Thanks for making the proposal!
@mgurley with regards to the negated facts and other modifiers, I think it would also be possible to store the negated fact in the clinical event table by modifying the original note_nlp_concept_id and turning it into the negated version of this concept. Since we have snomed attributes in the concept_relationship table, it is not hard to do this transformation.
Currently, our convention is no negative facts. Even if they exist as Concepts. The exception of course is the Measurement and the Observation domain. If you want to change that we would need use cases.