If you told me there was a disease that occurs in 10% of patients at risk, which is one of the leading causes of infertility and a source of substantial decreases in quality of life, then I’d expect that already know just about everything we need to know about the disease natural history and the effects of available treatments. But it turns out that, despite the significant public health impact of endometriosis to women of child-bearing age, there is still much we need to learn and lots of opportunities to contribute.
Now, I have to confess that before a couple years ago, I’m pretty sure I couldn’t have told you what endometriosis was. One of the most satisfying aspects of being part of the OHDSI community for me is getting the opportunity to meet and collaborate with others who I can learn from. It turns out our own @noemie is not just a world expert in machine learning, but also an active researcher in endometriosis and sits on the Endometriosis Foundation of America’s Scientific Advisory Board. So when she raised my awareness about the disease, I became very excited by all the possibilities about how evidence from observational data could be legitimately useful to researchers, providers and patients by providing a real-world perspective about the disease natural history. If you want to be similarly inspired, read or watch @noemie’s talk from 2016 at Patient Awareness Day. Now @noemie’s message was about “Giving patients the tools to contribute to endometriosis research”. I’d like to augment that by “giving patients the evidence from endometriosis research” and I think the OHDSI community is well-positioned to deliver on that.
The question is: where can we start? It turns out the endometriosis research community has already done us a great service: just last year, they published a consensus statement in Reproductive Services, “Research Priorities for Endometriosis: Recommendations From a Global Consortium of Investigators in Endometriosis”. In the publication, they outline several areas of opportunity that seem right up our community’s alley for anyone who may be interested.
One particular topic that @noemie and I would like to explore this month: among a target population of women of child-bearing age who visit a doctor and have not yet been diagnosed or treated for endometriosis, which patients will go on to be diagnosed with endometriosis in the next year? We plan to use ATLAS to develop a phenotype for endometriosis and characterize the population, and then apply OHDSI’s PatientLevelPrediction R package (thanks @jennareps and @Rijnbeek!) to determine how well we can correctly identify patients who will eventually develop the disease using baseline characteristics on or prior to the index visit. And if we get a predictive model that shows promise with high discrimination, good calibration, and holds up over internal and external validation, we can consider how to make a parsimonious model that could become a risk calculator for use by interested providers and patients. At least that’s our thought going into the project…we’ve got a month to sort out the details and see how it all plays out.
@Patrick_Ryan I would definitely volunteer some time to do some phenotyping using Aphrodite and try to build a model. Do you have already a defined ATLAS cohort that we could use to start?
This is a great example to illustrate the difference between classification
and prediction I think.
As phrased: among a target population of women of child-bearing age who
visit a doctor and have not yet been diagnosed or treated for
endometriosis, which patients will go on to be diagnosed with endometriosis
in the next year? the question appears to be a prediction question. But is
it? (@noemie, @Patrick_Ryan)
Do we really care about our ability to predict that another human (the
doctor) will figure out that the patient already has the condition and
will document it as such. i.e. ‘will diagnose with endometriosis next
year’. If we solve that problem, we set up an index date, and only use data
prior to the index date to make our prediction about the doctor figuring
out the existence of the underlying disease.
I’d argue that the notion of an index date is a distraction in this
setting, and we should use all the data about an individual to figure out
if they have the condition (endometriosis) and we have not yet figured that
out. i.e. solve a classification problem using the entire patient timeline
to find patients that are being missed.
It is indeed a good case to discuss classification vs prediction!
On one hand we are after a classification question. For women who have endometriosis, the diagnosis time is in a certain way artificial considering the fact that there is definite delay in diagnosis throughout the world. On the other hand, the problem we are after is exactly that: how to shorten that delay. There is currently no biomarker for the disease but maybe there are healthcare utilization markers for it. In which case we would want to learn from people who haven’t been diagnosed yet, so as not to learn healthcare patterns of people who are diagnosed. It depends on the question we are asking I think.
Sounds to me the same thing. Usually, by prediction people assume you predict something that hasn’t happened yet (re-admission, next year’s heart attack), but will happen in future. But sometimes you “predict” something you just don’t know yet, but it already is there, at which point you would call it classification. Same method, same result (some likelihood score for each patient). So, Aphrodite or PLP should work here.
There’s another interesting aspect to this that we should consider, especially if we are proposing that there is an under detection problem. I’ve only quickly skimmed the literature in response to this call but I thought this was interesting:
Mowers EL et al. Prevalence of endometriosis during abdominal or laparoscopic hysterectomy for chronic pelvic pain. Obstet Gynecol 2016 Jun; 127:1045
Salient finding: ~50-60% of patients with a preoperative diagnosis of endometriosis were found to have it on surgical pathology. That’s a lower hit rate than I would have expected. Some caveats expressed on how pathology was examined (no mention of endometriosis within the uterine wall, known as adenomyotic endometriosis).
The authors (and subsequent editorialists) comment that more studies are needed to see of patients undergoing hysterectomy for chronic pelvic pain are actually pain free following surgery. Challenging in the network to prove a negative, but one would hope that CPP no longer appears as a condition occurrence after surgery? There seems to be some questions around overall sensitization that could occur such that even in those cases that are positive for endometriosis, the pain may not be eliminated by addressing the endometriosis. It might be that we’re exposing some women to the risks of an abdominal surgery without substantive benefit? (interestingly, these patients in this study often have their ovaries removed at time of surgery - some data to suggest this has it’s own longer term health consequences).
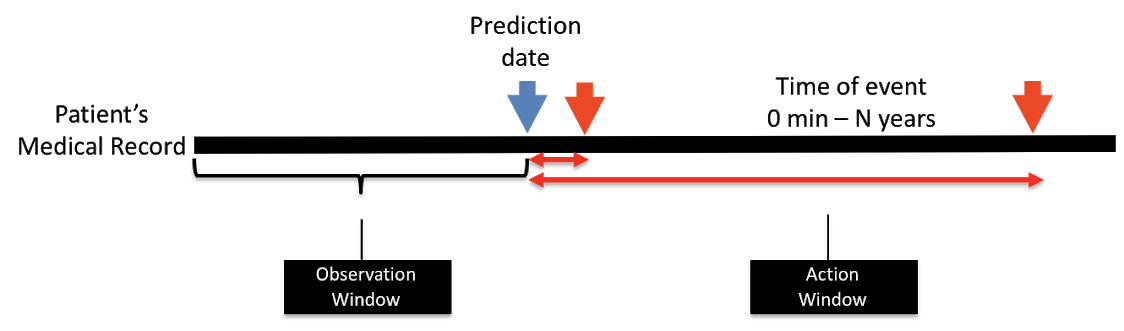
It does have implications on the length of record used for the task. There would be no notion of index date if solving a strict classification problem. See image.
But we are talking about a chronic condition with more or less cyclical exacerbations. There is no index date. Unless you want to assume menarche and menopause.
I am thinking that that it would be most useful to produce a series of outputs. The following assumes that you are primarily interested in symptomatic endometriosis and that asymptomatic endometriosis is interesting insofar as it can lead to symptoms in the future, but you could alter the definitions as you wish.
Has endometriosis been diagnosed and if so, when, to the best of our knowledge. It will likely rely on diagnosis codes, maybe treatments and diagnostic procedures.
If you reorder the record by update time (when was each fact first known), create a time series of probabilities that the person has symptomatic endometriosis. Once it has been diagnosed, the probability becomes high but maybe not 100%
Also create a time series of probabilities that the person will ever experience symptomatic endometriosis in the future. Depending on the how disease works, which we may not know, this could be asymptomatic endometriosis or someone at risk for the future growth or spread of endometrial tissue.
From these, one could estimate the average delay from symptoms to diagnosis, who is mostly likely to be diagnosed (e.g., what symptoms are recognized or not), and what groups are particularly at risk for developing the disease in the future.
I assume we would have a small training set that is manually curated and a larger set that is not. We would have to deal with falling off the edge of the record, where there are no more endometriosis diagnoses codes left but the person is not cured, just out of data.