A list of possible values for a given variable or database column is called a “vocabulary” in the OMOP CDM.
If you want to populate the OMOP *_source_concept_id columns with your source’s category values, you need to do the following:
Create a row in the concept table for your vocabulary, with domain_id = 'Metadata' and vocabulary_id = 'Vocabulary' and concept_class_id = 'Vocabulary'. Note that your source records in the concept table must have concept_id values above 2 billion, by OHDSI convention.
Create a row in the vocabulary table for your vocabulary, with its vocabulary_concept_id referencing the row you created in step #1.
(Optional) Create one or more rows in the concept table for your vocabulary’s concept classes, if you want to be able to stratify the concepts within your vocabulary. These concept class records would have domain_id = 'Metadata' and vocabulary_id = 'Concept Class' and concept_class_id = 'Concept Class'. Again, ensure the records you add to the concept table have concept_id values above 2 billion.
(Optional) If you created your own concept classes in step #3, then you also need to create records in the concept_class table with their concept_class_concept_id columns referencing the concept_id values of the rows in step #3.
Now you’re ready to create rows in the concept table for your vocabulary’s list of values. You would create one record for each value in your vocabulary. Create rows with domain_id matching the OMOP table in which you will use the vocabulary, vocabulary_id matching your vocabulary name created in step #2, and concept_class_id matching one of the values you created in step #4. If you didn’t create your own concept classes, then you can use one of the existing ones. Once again, ensure the records you add to the concept table have concept_id values above 2 billion.
Now that you have your list of values loaded to the concept table, you can reference their concept_id values in the OMOP *_source_concept_id columns.
Thanks, that’s more common and realistic than someone with eyes that are two different colors (what came to mind).
The clinicians, or providers, are associated through foreign keys in many of the data tables to and so would be limited to a single one, so that might involve some creativity.
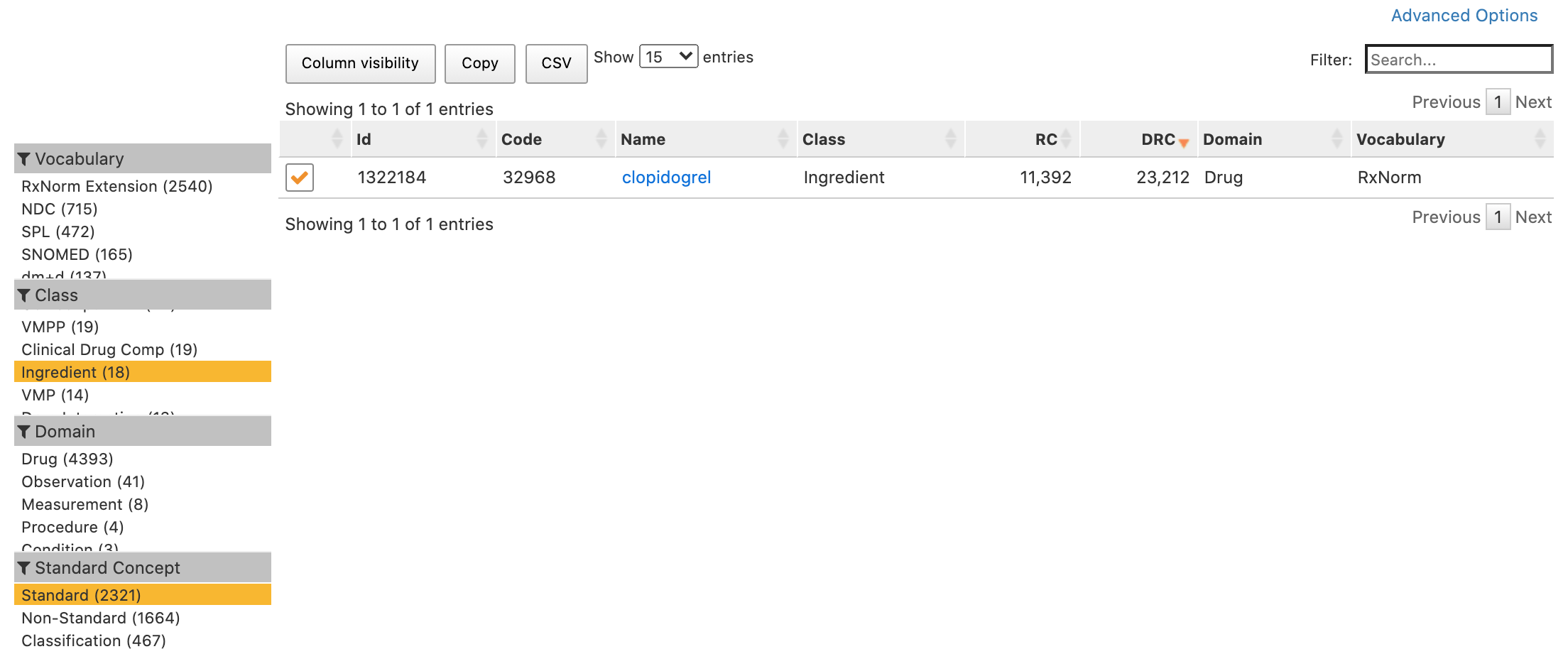
Medications that are made of ingredients involve “precoordinated” vocabulary terms. If you poke around the drug vocabularies, like RxNorm, you’ll find they consist, not of ingredients, but formulations. So this query comes back with 263 rows:
select concept_name from cdm.concept where concept_name ilike ‘%metoprolol%’ and vocabulary_id = ‘RxNorm’;
The variation comes from different amounts as well as different combinations. The value in this case is a single concept that represents the combination you’re after.
Patient has several addresses
address; or the person has moved and you want to track prior addresses. There is only one location id in the person table, so the CDM limits a person to a single address. However, the fact_relationship table is a generic many to many table which you can use to link a person to additional addresses. In CDM v6 there is a location history table which as the name indicates is intended to store past addresses.
Patient has several clinicians listed.
Similar situation to the snowbird address. Only one provider id in the patient table but the fact_relationship table can be used to link person to additional providers.
Medication consists of multiple components
It might be possible to find a “precoordinated” drug concept, but if not the ETL should create multiple drug exposure rows, one for each medication component. Creating multiple rows for one medication event may not be intuitive, but for most drug analyses, the question is, ‘was the person exposed to the medication’.
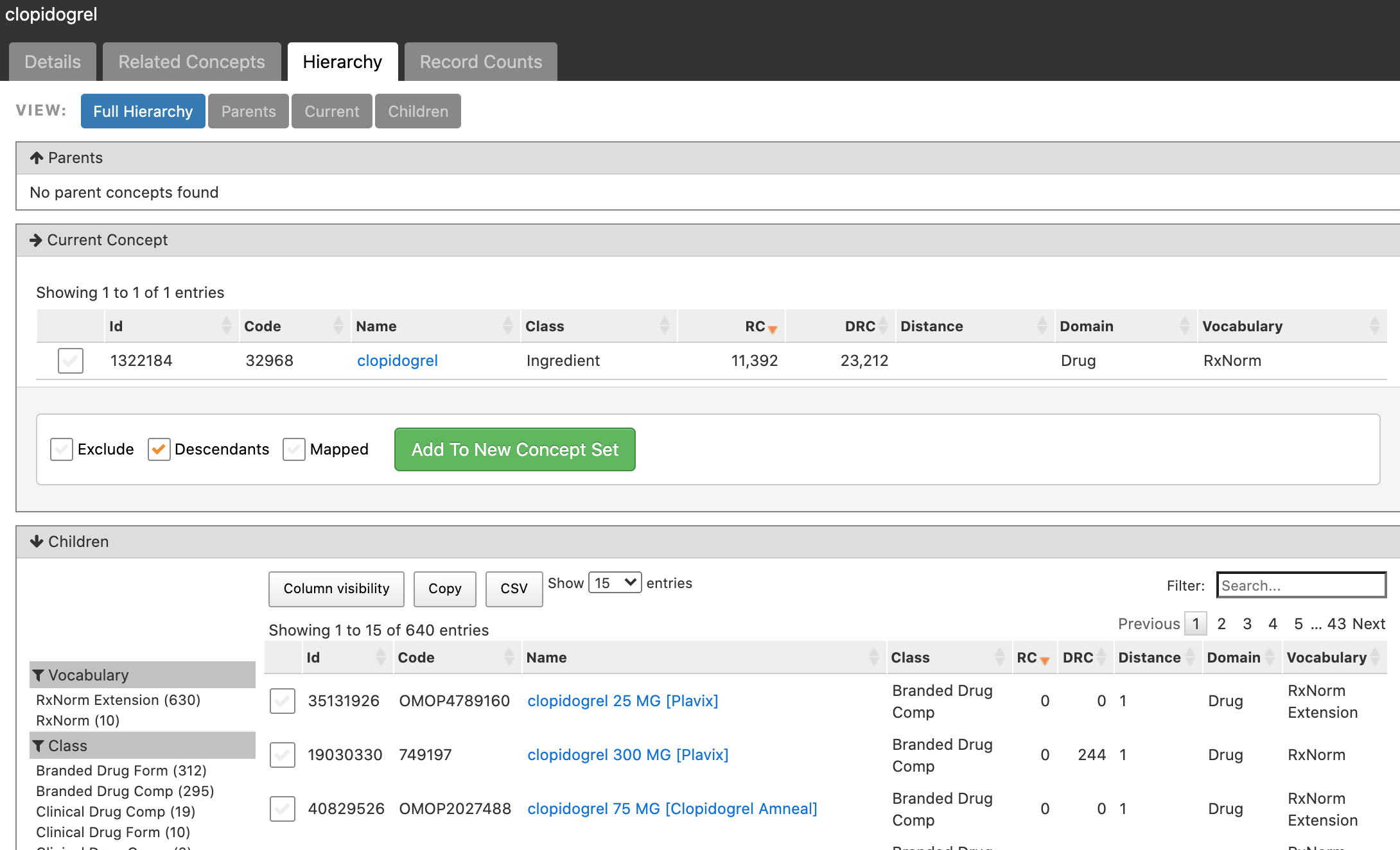
Having access to the concept hierarchy within drug concepts, making it possible to query for an individual ingredient would greatly simplify my drug concept sets! Alternately, recording ingredients and amounts separately would work.
One main address is put into Location table as mentioned in the above post. The rest addresses are loaded into Observation table using concept_id = 4083586 (Patient address). The actual address (123 main street etc.) is loaded into value_as_string column. One row for each address. Load as many rows as you want.
a patient has several clinicians
One main clinician is put into Provider table. The rest clinicians are loaded into Observation table using concept_id = 4269007 (Has provider). The actual provider’s name or Id are loaded into value_as_string column. One row for each clinician. Load as many rows as you want.
All good ideas, but we need to come from the use case. Can you provide these, @slis? In particular, what analytical outcome or insight do you want to achieve with the dual location? Or with any location for that matter.
The second problem I don’t understand at all. A patient taking two drugs will get two records in the DRUG_EXPOSURE table.
The multiple providers: Again, what is the use case? What do you want to know?
Remember, the CDM is not a generic self-storage for any type of data. It’s an analytical model to support specific scientific questions. The data are modeled for that purpose. Everything that doesn’t have a purpose is not needed.
Here is how to get the individual ingredients, see QueryLibrary (ohdsi.org) and search for ingredient.
SELECT
D.Concept_Id drug_concept_id,
D.Concept_Name drug_name,
D.Concept_Code drug_concept_code,
D.Concept_Class_id drug_concept_class,
A.Concept_Id ingredient_concept_id,
A.Concept_Name ingredient_name,
A.Concept_Code ingredient_concept_code,
A.Concept_Class_id ingredient_concept_class
FROM
concept_ancestor CA,
concept A,
concept D
WHERE
CA.descendant_concept_id = D.concept_id
AND CA.ancestor_concept_id = A.concept_id
AND LOWER(A.concept_class_id) = 'ingredient'
AND getdate() >= A.VALID_START_DATE
AND getdate() <= A.VALID_END_DATE
AND getdate() >= D.VALID_START_DATE
AND getdate() <= D.VALID_END_DATE
AND CA.descendant_concept_id IN (1836434)
or a short cut method because drug strength has the ingredients for a drug
SELECT drug.concept_id, drug.concept_name AS drug_name, ingredient_concept_id, ing.concept_name as ingredient_name
FROM concept drug
LEFT OUTER JOIN drug_strength ON drug_concept_id = concept_id
LEFT OUTER JOIN concept ing ON ing.concept_id = ingredient_concept_id
WHERE drug.concept_id IN( 1836434)
Thanks! I’d seen the hierarchy functionality at one time, the ingredient class another, and hadn’t put them together.
This creates a concept set with the individual drugs in a quick and easy way, and will make life easier to create the concepts sets. Those concept sets match directly to the concepts used in drug_exposure. I was thinking of a step in between where you specify the ingredient in your cohort, and the hierarchy mapping happens when it is queried. It makes for a concise specification, but it could also mean your query is different if a new drug with that ingredient appears.