We are mapping CDS data to OMOP within an NHS Trust.
Regarding mapping from NHS Ethnic Category > OMOP race, we have made our own decisions but are aware of the Athena standard mappings for this. Some seem unrealistic for researcher use. For example, the below categories are all recommended to be mapped to “white”:
Mixed - White and Black Caribbean
Mixed - White and Black African
Mixed - White and Asian
Mixed - Any other mixed background
I’m keen to understand what others have done. Have you gone with the Athena mappings? Do you represent everything as 0 in OMOP to force the reader back to the source data? Or have you taken a similar approach to us, making your own decision about what to map where?
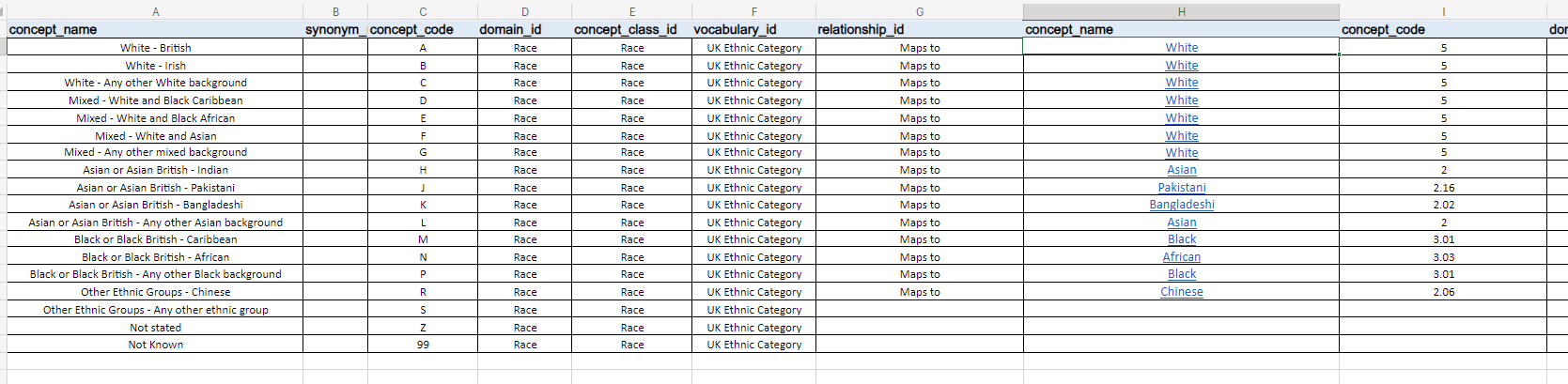
As part of the mapping execise we carried out for Great Ormond Street Hopstial (GOSH) and testing the community contribution, you can see the jounrey taken to add the first instance for NHS ethnicty code to the race domain in the follwoing GitHub issue.
At present for mapping the peson table this is the logic we have code and run
Yes, the logic in your example is the one we have used. I have attached a screenshot of one of the tabs that show the view of current mapping for NHS ethnicity codes to OMOP:
This was the 1st iteration of adding the NHS ethnicity codes. The Vocabulary working Group meetings are a great place to highlight and discuss new use cases
As part of it, no races or ethnicities get mapped, unless they are originated in the same coding system. But certainly we are not mapping “White Irish” to “White” (American). These categories do not work across country and societal borders. Fractions of races are even less supported by any definition allowing for a rational mapping. So, keep all the whites, blacks, greys and whatever colors in parallel., together with the ethnicities. An analyst pursuing some use case will have to make the right selection based on the location of the database and source of the data.
I think folks are planning a hackathon to create one big happy global pot of all of them. Stay tuned.