We are constructing a real-time CDM, which means a CDM system converting new increased EMR data into CDM in daily basis. The project is going well.
However, our issue is the Achilles: how can we apply the new changes in CDM into Achilles. In our server, running the Achilles against the full CDM takes about 40 hours, which is too long. Is there any way running the Achilles against the new added CDM data only, and adding them into the preexist Achilles JASON file?
Rae
That’s a hard issue: the Achilles statistics build on each other. The statistics built from the analysis 1-10 are used in all the later analysis, making it a little complicated to make it so it is more on demand. Some statistics need the entire set of data to sort to calculate things like medians and the quartiles. It is these operations that are probably making your execution very slow (and also probably some complicated Vocabulary queries that are not efficient).
Could you tell me what your database platform is? (Postgresql, MSSql, Oracle) and would you be willing to execute some of the database index scripts that we’ve used in our own environment to help performance?
We are using MSSQL. The scripts for index will be very helpful to us.
Hi, @rwpark,
There’s a list of minimum indexes at this link:
https://raw.githubusercontent.com/OHDSI/CommonDataModel/master/Sql%20Server/OMOP%20CDM%20indexes%20required%20-%20SQL%20Server.sql
If you have multiple CDMs in the same database with different schemas (such as one in .dbo and another in .cdm1) you’ll need to alter this script to add the schema in front of each table name. Otherwise you should be able to connect to the database and execute it directly on your cdm. Note: this sets up a ‘clustered’ index on many of your tables, and depending on your data size, it could take a long time to execute.
These index are tuned to fetch patient level data from the tables, but I have a feeling that there are secondary indexes that you may be able to apply to help speed up Achilles processing. I don’t have a set of those indexes, however you can do the following steps to let SQL server tell you what indexes would help (but you should do these steps after appying the above indexes)
- Execute your achilles() R command but add the sqlOnly = TRUE parameter to the call. Example:
achilles(connectionDetails, cdmDatabaseSchema = "dbo", sqlOnly = TRUE)
This will output the Achilles analysis script to the local directory.‘output’.
- Open up your Microsoft SQL Management Studio and you can paste one of the analysis queries (if you can track down one of the one’s that takes a very long time to execute, then you can just focus on that one query), but if you highlight the SQL script text and click the ‘Display Estimated Execution Plan’ button, it will give you Index recommendations. here’s an example:
For this sql:
-- 101 Number of persons by age, with age at first observation period
insert into {cdmDatabaseSchema}.ACHILLES_results (analysis_id, stratum_1, count_value)
select 101 as analysis_id, year(op1.index_date) - p1.YEAR_OF_BIRTH as stratum_1, COUNT_BIG(p1.person_id) as count_value
from {cdmDatabaseSchema}.dbo.PERSON p1
inner join (select person_id, MIN(observation_period_start_date) as index_date from {cdmDatabaseSchema}.OBSERVATION_PERIOD group by PERSON_ID) op1
on p1.PERSON_ID = op1.PERSON_ID
group by year(op1.index_date) - p1.YEAR_OF_BIRTH;
--
Change {cdmDatabaseSchema} to your own schema (such as DBO)
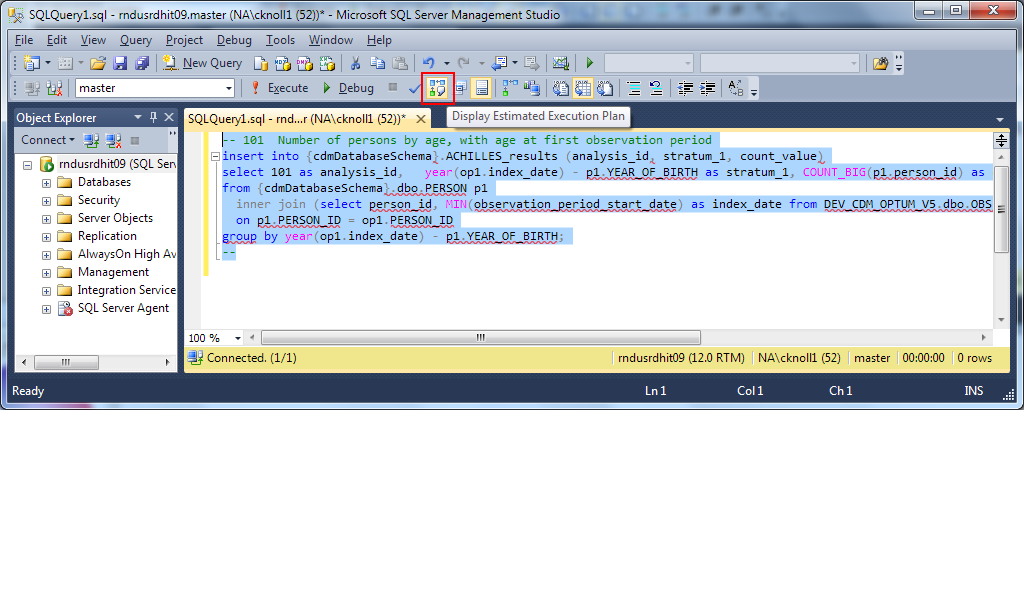
Above is the example where i pasted in the sql and highlighted the show execution plan.
If you click it with the sql highlighted, you’ll get this output:
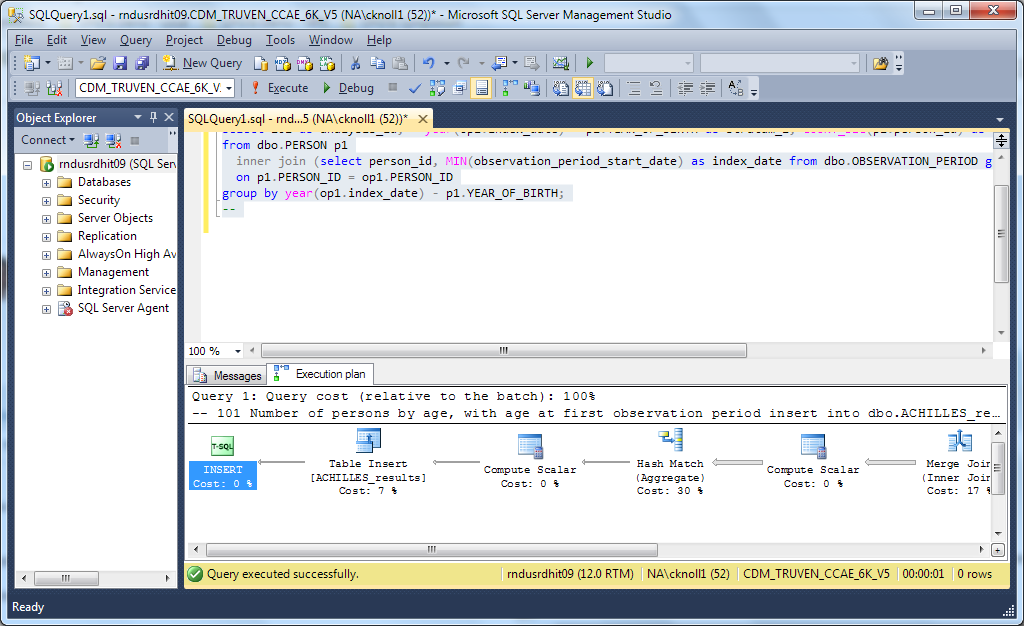
If you need indexes, you’ll see a message in the box that says “Query Cost…”. You can right-click and it will give you the option to generate CREATE INDEX statements.
You should do this for any Achilles fragment SQL that gives you trouble.
In addition, make sure you have a good amount of RAM on the serer (128MB would be a minimum if you’re working with a large dataset). RAM helps a lot.
-Chris
3 Likes
You can also identify the analyses that matter to you the most and run only those. (or have an exclusion list).
In R, you would use the analysis id parameter. This is described here:
(@lee_evans , is there perhaps syntax of hyperlink that could prevent the forum from expanding the link into a preview)
2 Likes
Thank you!
We applied the indexing SQL, and it takes less than 1 hours.
We are also finding necessary indexes for Achilles by applying the method you recommended.
We will merge them together and will post it here later.
1 hour is much better! Thanks for working through the indexing issues. And I look forward to seeing the index suggestions you found!
-Chris
Thank you very much.
The code for Achilles Heel only is simple but powerful. Especially we are facing extreme overload in the iterative DQM processes.
Running the Achilles except some unnecessary analyses is awesome. We had made some null table to escape the unnecessary analyse, but this code is much easier and robust.
The Heel summary table is also wonderful. We needed it!
Here is the additional SQL queris for indexing the Achilles DB.
After running the Patrick’s indexing SQL, we had run the all the Achilles SQL and found required additional indexing queries,as Chris Knoll demonstrated how to do it in the above thread.
Patrick’s indexing SQL, https://raw.githubusercontent.com/OHDSI/CommonDataModel/master/Sql%20Server/OMOP%20CDM%20indexes%20required%20-%20SQL%20Server.sql , is required before running this SQL, because we found these indexing queris after running the Patrik;s queris.
/****************************************************************************************************************************************
***************************************************** Non Cluster Index **************************************************************************************************************************************/
/* PERSON */
USE [Camel_DB]
GO
CREATE NONCLUSTERED INDEX [<PERSON_1, sysname,>]
ON [dbo].[PERSON] ([person_id])
INCLUDE ([year_of_birth],[gender_concept_id] );
GO;
CREATE NONCLUSTERED INDEX [<PERSON_2, sysname,>]
ON [dbo].[PERSON] ([location_id])
INCLUDE ([person_id]);
GO;
CREATE NONCLUSTERED INDEX [<PERSON_3, sysname,>]
ON [dbo].[PERSON] ([provider_id]);
GO;
CREATE NONCLUSTERED INDEX [<PERSON_4, sysname,>]
ON [dbo].[PERSON] ([care_site_id]);
GO;
/* OBSERVATION */
USE [Camel_DB];
GO;
CREATE NONCLUSTERED INDEX [<OBSERVATION_1, sysname,>]
ON [dbo].[OBSERVATION] ([provider_id]);
GO;
CREATE NONCLUSTERED INDEX [<OBSERVATION_2, sysname,>]
ON [dbo].[OBSERVATION] ([visit_occurrence_id]);
GO;
CREATE NONCLUSTERED INDEX [<OBSERVATION_3, sysname,>]
ON [dbo].[OBSERVATION] ([value_as_number],[unit_concept_id])
INCLUDE ([observation_concept_id]);
GO;
/* OBSERVATION_PERIOD */
CREATE NONCLUSTERED INDEX [<OBSERVATION_PERIOD_4, sysname,>]
ON [dbo].[OBSERVATION_PERIOD] ([PERSON_ID])
INCLUDE ([OBSERVATION_PERIOD_START_DATE]);
GO;
CREATE NONCLUSTERED INDEX [<OBSERVATION_PERIOD_5, sysname,>]
ON [dbo].[OBSERVATION_PERIOD] ([OBSERVATION_PERIOD_START_DATE],[OBSERVATION_PERIOD_END_DATE])
INCLUDE ([PERSON_ID]);
GO;
/* VISIT */
CREATE NONCLUSTERED INDEX [<VISIT_1, sysname,>]
ON [dbo].[VISIT_OCCURRENCE] ([care_site_id]);
GO;
/* CONDITION */
CREATE NONCLUSTERED INDEX [<CONDITION_1, sysname,>]
ON [dbo].[CONDITION_OCCURRENCE] ([provider_id]);
GO;
CREATE NONCLUSTERED INDEX [<CONDITION_2, sysname,>]
ON [dbo].[CONDITION_OCCURRENCE] ([visit_occurrence_id]);
GO;
/* CONDITION_ERA */
CREATE NONCLUSTERED INDEX [<CONDITION_ERA_1, sysname,>]
ON [dbo].[CONDITION_ERA] ([person_id])
INCLUDE ([condition_concept_id],[condition_era_start_date]);
GO;
/* PROCEDURE */
CREATE NONCLUSTERED INDEX [<PROCEDURE_1, sysname,>]
ON [dbo].[PROCEDURE_OCCURRENCE] ([provider_id], [visit_occurrence_id]);
GO;
/* DRUG */
CREATE NONCLUSTERED INDEX [<DRUG_1, sysname,>]
ON [dbo].[DRUG_EXPOSURE] ([provider_id]);
GO;
CREATE NONCLUSTERED INDEX [<DRUG_2, sysname,>]
ON [dbo].[DRUG_EXPOSURE] ([visit_occurrence_id])
GO;
CREATE NONCLUSTERED INDEX [<DRUG_3, sysname,>]
ON [dbo].[DRUG_EXPOSURE] ([days_supply])
INCLUDE ([drug_concept_id])
GO;
CREATE NONCLUSTERED INDEX [<DRUG_4, sysname,>]
ON [dbo].[DRUG_EXPOSURE] ([refills])
INCLUDE ([drug_concept_id])
GO;
CREATE NONCLUSTERED INDEX [<DRUG_5, sysname,>]
ON [dbo].[DRUG_EXPOSURE] ([quantity])
INCLUDE ([drug_concept_id])
GO;
CREATE NONCLUSTERED INDEX [<DRUG_6, sysname,>]
ON [dbo].[DRUG_EXPOSURE] ([drug_concept_id])
INCLUDE ([drug_source_value])
GO;
/* DRUG_ERA */
CREATE NONCLUSTERED INDEX [<DRUG_ERA_1, sysname,>]
ON [dbo].[DRUG_ERA] ([person_id])
INCLUDE ([drug_concept_id],[drug_era_start_date])
GO;
/* MEASUREMENT */
CREATE NONCLUSTERED INDEX [<MEASUREMENT_1, sysname,>]
ON [dbo].[MEASUREMENT] ([person_id])
INCLUDE ([measurement_concept_id],[measurement_date]);
GO;
CREATE NONCLUSTERED INDEX [<MEASUREMENT_2, sysname,>]
ON [dbo].[MEASUREMENT] ([provider_id]);
GO;
CREATE NONCLUSTERED INDEX [<MEASUREMENT_3, sysname,>]
ON [dbo].[MEASUREMENT] ([visit_occurrence_id]);
GO;
CREATE NONCLUSTERED INDEX [<MEASUREMENT_4, sysname,>]
ON [dbo].[MEASUREMENT] ([value_as_number],[value_as_concept_id]);
GO;
CREATE NONCLUSTERED INDEX [<MEASUREMENT_5, sysname,>]
ON [dbo].[MEASUREMENT] ([value_as_number],[unit_concept_id])
INCLUDE ([measurement_concept_id]);
GO;
CREATE NONCLUSTERED INDEX [<MEASUREMENT_6, sysname,>]
ON [dbo].[MEASUREMENT] ([value_as_number],[unit_concept_id],[range_low],[range_high])
INCLUDE ([measurement_concept_id]);
GO;
CREATE NONCLUSTERED INDEX [<MEASUREMENT_7, sysname,>]
ON [dbo].[MEASUREMENT] ([value_as_number]);
GO;
/* PROVIDER */
CREATE NONCLUSTERED INDEX [<PROVIDER_1, sysname,>]
ON [dbo].[PROVIDER] ([care_site_id]);
GO;
/* PAYER_PLAN_PERIOD */
CREATE NONCLUSTERED INDEX [<PAYER_PLAN_PERIOD_1, sysname,>]
ON [dbo].[PAYER_PLAN_PERIOD] ([person_id])
INCLUDE ([payer_plan_period_start_date],[payer_plan_period_end_date]);
GO;
/* ACHILLES_results */
CREATE NONCLUSTERED INDEX [<ACHILLES_RESULTS, sysname,>]
ON [dbo].[ACHILLES_results] ([count_value]);
GO;