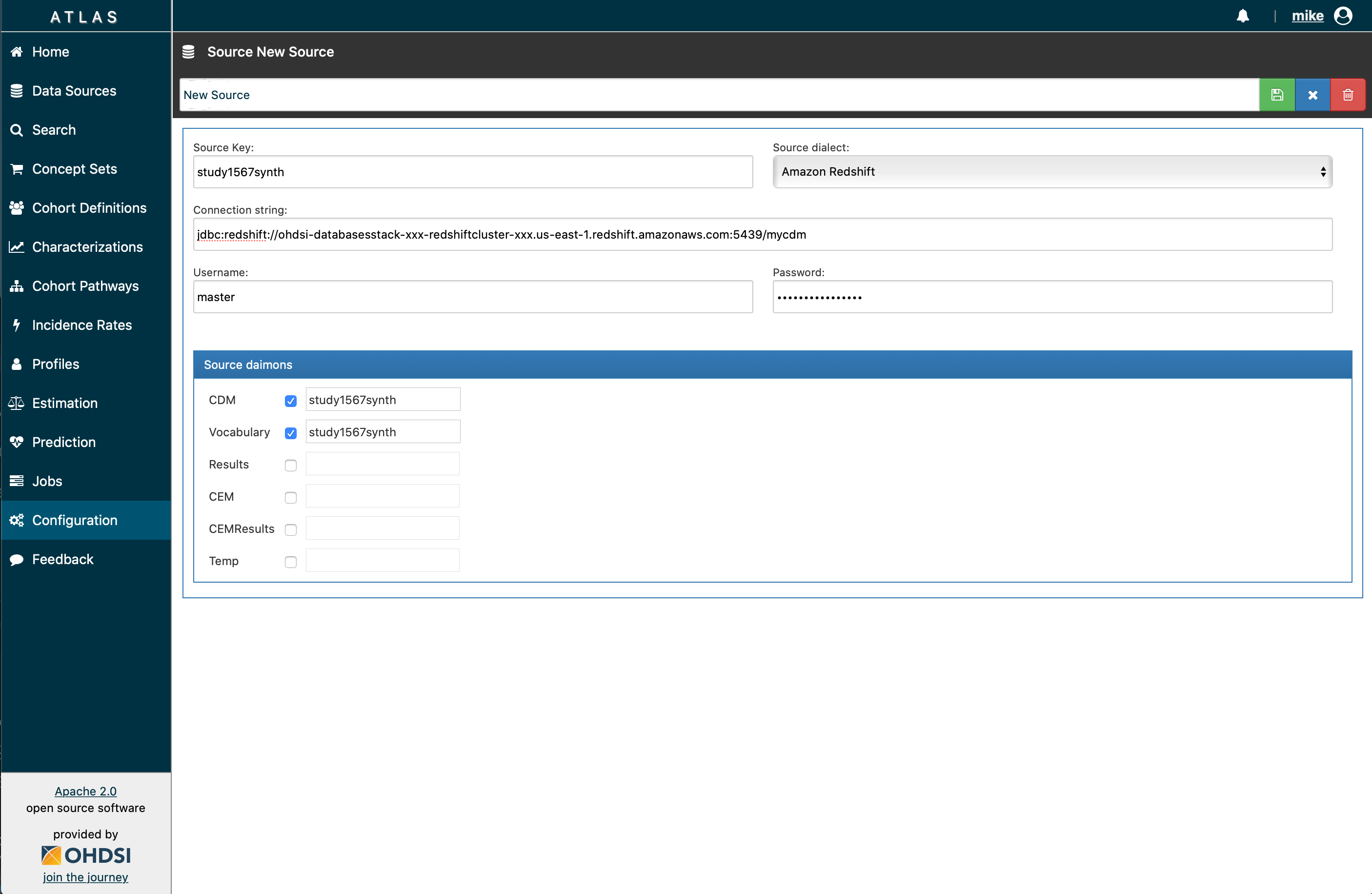
I’ve recently completed standing up our OHDSIonAWS stack in our AWS account and I opted to use all synthetic datasets that were referenced in the CloudFormation template. Everything works great for those datasets, and I can easily query them and look at the data in Atlas. Now, the organization I work for is going to be generating a ton of data that I’m attempting to stand up an automated data pipeline for, and my question is the following: what is the process of adding new datasets to the Redshift cluster on AWS?
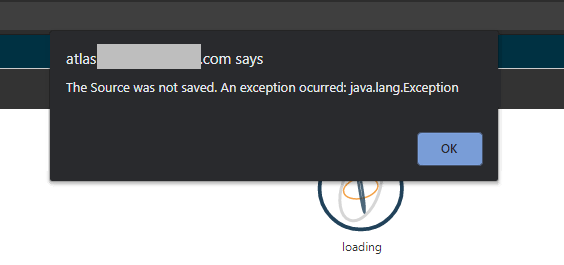
I’m a little stuck on what my next steps should be. I’ve created the SQL scripts to copy the data from CSV files located in S3, populated the person table and added all the vocabularies in Redshift’s query editor, and verified that all the data exists in Redshift. Now, my problem is that I am having issues with using the configuration panel in Atlas 2.75 to add a new dataset to the web API. Every time I submit the dataset (using the schema name that I created in Redshift), Atlas always responds with an error that says:
The Source was not saved. An exception ocurred: javax.persistence.EntityExistsException
More pieces of information that may be helpful:
I have the internet gateway restricted to only allow traffic from inside our internal network’s CIDR range.
I’m using the JDBC connection that Redshift gives me to attempt to load the dataset, along with the master user’s password.
I do not have a results schema at this point (this is all synthetic data currently and I’m trying to just get familiar with loading data into the system).
Am I missing something glaringly obvious? To me it seems like Atlas can’t find the dataset, but I know it exists in Redshift.
A wild guess, but still: would you please check if the source key for the new dataset (that’s the first field after the human-readable dataset name) is equal to that of some other dataset you’ve added previously?
@mnlubke,
Sorry, I was wrong. I remember getting a similar error when saving dataset with a source key that was used previously, but in this case Atlas throws a generic Exception from a SourceService method:
In your case, EntityExistsException is thrown not by Atlas itself but somewhere from Spring level (probably here). I wasn’t able to find any reported issues for this on WebAPI GitHub though.
I wonder if this is related to the identity sequence that is used when inserting new sources. There’s a source_sequence sequencer that is used to assign the next source ID, but if the initial records inserted in to the webapi.source table used a hard-coded integer instead of one from the sequence, then you’ll have a ‘re-used identity’ when you insert from the UI.
To check, can you run the query on your PostgreSQL instance (i’m assuming in the AWS configuration, there is a PostgreSQL instance):
select currval('{schema}.source_sequence')
See what number you get. If it is a number that already exists as a source_id, then that would possibly explain the error. If it is the case, you can reset the sequence to the value of the MAX(source_id) in your source table:
select setval('{schema}.source_sequence',{maxId}); -- next value will be maxId + 1
In addition, there is a source_daimon_sequence that is used to create an ID for the records in {schema}.source_daimon. You may run into the exact same problem with the source_daimon table, but with the source_damion_id column. The solution is the same: use setval() to update the source_daimon_sequence to the max value in the table so that a new entity ID will be created when the source is saved from the UI.
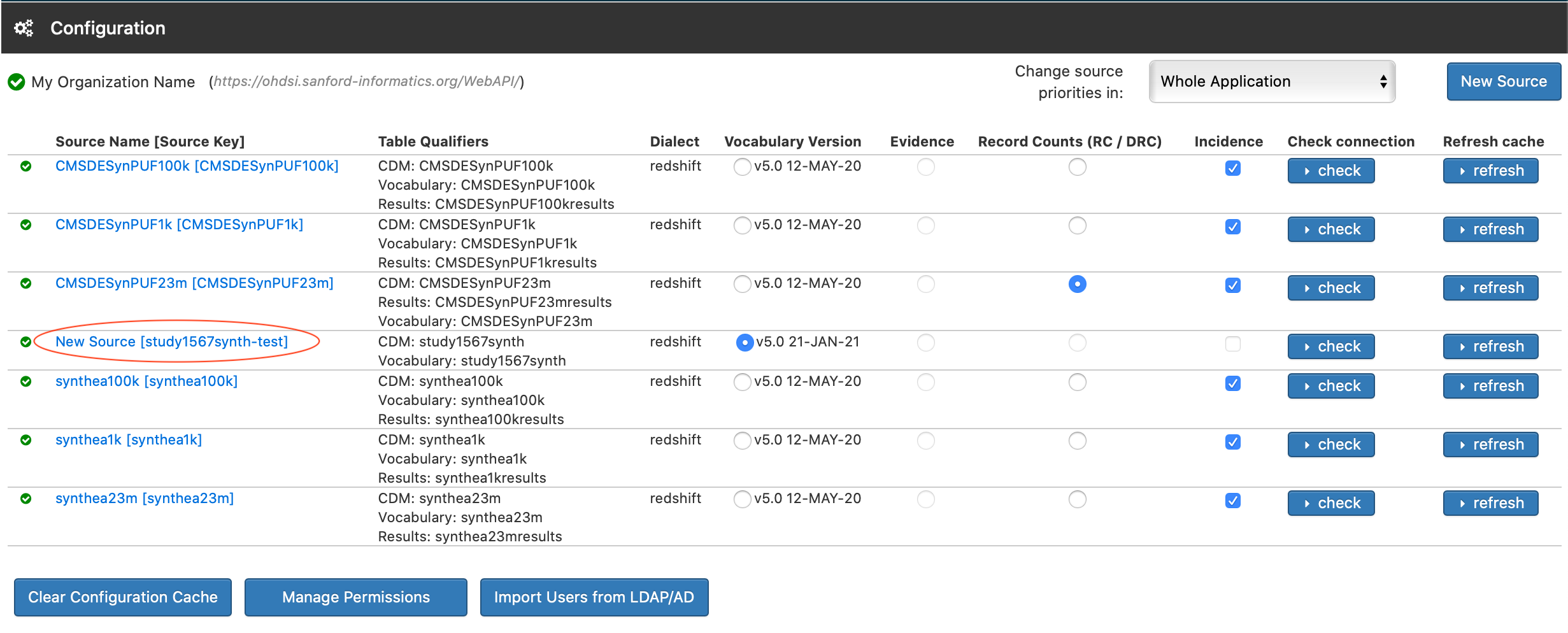
Thanks a TON for your response. You really helped get me on the correct path here. I had to do a little bit of reverse engineering to figure out how to even access the RDS instance on AWS, but I was able to do it. I went ahead and set both the webapi.source_sequence and webapi.source_daimon_sequence values to their maximums and was able to actually add the dataset to via the UI. When I ran the currval function I received the following: ERROR: currval of sequence "source_daimon_sequence" is not yet defined in this session
I set the vals like you mentioned, went back to the web UI, and added the sets and they were added successfully!
I added permissions so that my user could view the datasets, but I still don’t see them in Atlas yet as a selectable data source. Is this because I don’t have a results schema set?
It could be cached, although when a new source is added, it should automatically clear the source cache.
But you can also do this by going to the URL in a browser:
/WebAPI/source/refresh
That will print out all the sources, and you can check to see if that helps, otherwise you may need to re-login. I’m sorry I’m not familiar with the security setup for restricting datasources.