I recently managed to set up the “default” OMOP CDM schema on a PostgreSQL database, thanks to the .sql scripts available in the OMOP Github repository and a Python script aiding the insertion of Athena vocabularies.
I used the word “default” above, because I’m trying to set up a OMOP compliant database for a project in which also biomedical images will be collected. In fact, I’d like to implement a OMOP schema extension as the one that was conceived by the Bioimages WG (https://www.ohdsi.org/wp-content/uploads/2023/10/6-Park-BriefReport.pdf), but given that the linked paper provides only some structure for the implementation, I’d like to discuss about the actual PostgreSQL implementation with someone that possibly had my same necessity.
Also, once the database will be set up with the proper schema extension, I’ll need to interface it with a Python project. I’d like to know if someone had previously worked with Python to interact with the database, to discuss about the best modules to use in order to create an Object-Relational Mapping of the tables (SQLAcodegen?), and to actually query the database with Python code (SQLAlchemy?).
Thank you for your time, any type of help is appreciated!
The normal mode of working with OMOP CDM “backend” is OHDSI family of R packages. Which is not ideal – R is a wonderful language when it comes tabular data operation and statistical analysis, but it is not a good general purpose language, like Python is. And in 2024, it is way easier to find a Python developer than an R one. I would imagine that image data is also not a prime use-case by R libraries.
I am currently gathering use-cases for a Python toolset for purposefully interacting with an OMOP CDM instance. There are a number of OMOP space projects that rely on logic and libraries which are not the best supported in R, and as such are written in Python. Two I know of:
PyOMOP which interfaces LLM for writing queries against OMOP-converted data
Jackalope core which provides semantic post-coordination support in OMOP CDM following SNOMED model
Both use SQLAlchemy ORM to abstract interaction with the database. There are also some in-house developed tools that use simple dbt-style SQL templating. I think, for a general use-case, Jackalope’s implementation of database interface is generic enough to be copied and extended for other use-cases. Otherwise, SQL templating can take you surprisingly far – 99.9% of the time people choose to use an ORM for compatibility purposes find it that they never actually use compatibility features.
But there absolutely should be a Python library to interface with OMOP. There already are existing Python tools to interact with OMOP, each of which has to invent a boilerplate-clad bicycle to make their tool connect to the OMOP instance. And there are many more other universal use-cases to be fulfilled which could use this library:
Local 2bil concept management
Simplifying updating vocabularies from Athena
Vocabulary authoring support for community contributions
Transitioning custom mappings from source_to_concept_map to modern management model
AI interfacing
I would argue that most of the code for such tool is actually already written, and just needs a PyPI home and a license. I plan to raise this issue on the next Open-Source Workgroup call, but I’ll tag people who could be interested for now: @Daniel_Smith@beapen@Denys_Kaduk@Alexdavv@yupengli
Thank you @Eduard_Korchmar, your answer has been very explicative, as you provided me with a couple of useful projects that I can explore and adapt for my purposes, other that providing me with a view of how far official OHDSI support has come in the regards of Python development.
You have been quite provvidential as I have an academic background mostly as a data scientist; I have an interest in SW development but the only language I can confidently utilize is Python (with all its pros and cons).
I have just a couple more questions:
How can I remain updated about the developments of the Open-Source Workgroup?
Would you say that the “Implementers” area of the forum is the right area to ask about a schema extension to handle bioimages? Do you have any suggestion on who to ask about this topic? Otherwise I’ll try to find a way to “patchwork” my way into inserting bioimages (as a filepath or as a binary blob) into the “default schema”, perhaps in the “procedure_occurrence” table.
Thank you again for your very clear answer and for your time!
All OHDSI Workgroups are hosted on community Teams, there is a form to apply:
There is a dedicated Medical Imaging Workgroup, that you could also join with the above link. There is a medical imaging OMOP extension in active development.
Thanks @Eduard_Korchmar . I agree, and have indeed developed some tooling with SQLalchemy in on-prem workloads, boto for work with AWS infrastructure, and custom jinja templating prior to our current pipes in DBT. Some of our other workloads at Emory utilize CS or Python, and DBT gets kicked off by either. R packages will certainly be run for doing things such as Achilles and DQD, but otherwise, some of the work needs to be done elsewhere (e.g., NLP performed via standalone app or custom python pipeline).
Would definitely be interested in seeing where this goes!
I will make my best effort to have an initial development proposal with feature milestones to present for the toolset to the closest Open-Source WG Call, or next one, sadly more likely.
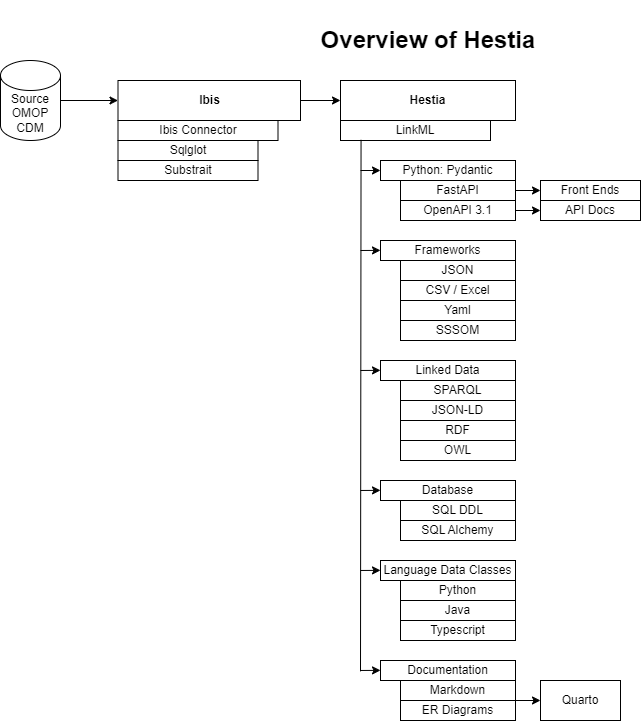
@OHDSI-Nabla There have been a few projects in the past that, similar to yours, come up against this issue and have identified a similar need. A few of us on the Open Source WG have tossed back and for ideas for a bit. A few weeks ago, I finally got around to making something more formal out of it through Hestia. While this is in its early stages, I would welcome any collaborators and ideas. @Eduard_Korchmar I agree that most of the code is already written or can be translated from R.
I am still working on bringing in some code from my messy local repo to this tidier repository, but the Dev branch is in a good state to start building.
There are a few goals of the project so far:
Representing the OMOP CDM in LinkML
Offloading/abstracting SQL translation and connectors to Sqlglot and Ibis.
Composable API for OHDSI tooling using OpenAPI v3.1.0 standards.
Fast and efficient vocabulary search using LanceDB or DuckDB vector similarity.
Decoupling backend and frontend.
Automated Human and Machine (e.g. GPT with Actions) readable API Documentation.
@hspence and @Eduard_Korchmar , just an aside (maybe?) regarding common data elements (CDE) development within the NIH and it’s subdivisions.
There was a great presentation at the NIH Workshop on Advancing CDEs(Advancing the Use and Development of Common Data Elements in Research Workshop), and I wanted to post their workflow, as there is some overlap with yours @hspence , but with a different toolkit to address some of the documentation, as well as an addition to the generation of mappings (CurateGPT). This is from day 2, session IV, “Making the ‘Common’ in CDEs More Common”