For ex: I have more than 1000 unique drug names. However, the drug names has spelling mistakes. In addition, all these 1000 terms are after shortlisting based on frequency count.
For ex: we have ISONIAZID 300MG TAB , ISONAZID 300MG TAB, ISNIAZID 300MG
Through manual review, I found out that they all are same but just a spelling mistake (or space issues). But the problem is there are several other drugs with such spelling mistakes and I am not sure how can I group all of them into one (meaning rename it with right spelling)?
But is there anyway to correct this spelling mistake and map this to OMOP concepts efficiently.
Meaning, if I had like 200-300 I would have done it manually but since we have more than 1000, not sure how to get rid of this spelling mistakes in an efficient manner.
Or do I have to manually correct the spelling mistakes?
I tried Usagi as well. So, is it like
I upload raw terms (which contains spelling mistakes) csv in Usagi
Get the closest match
And again review this 1K records and fix the outliers (which are mapped incorrectly)
How do you handle issues like this during your mapping phase? Any tips/approach that you follow is very helpful to know. I understand it may not be possible to achieve 100pc accuracy while mapping but learning from your experience will definitely be helpful
Hi Akshay, in my experience, Usagi handles spelling mistakes very well. Still, you have to review manually. You can reduce this work by 1) limiting Usagi to the drug domain and 2) sorting desc by the resulting score. Probably you can approve the top x % straight away. (select the mappings while holding shift, edig->approve all).
Something that could make your task difficult, is that your drug names also contain strength and dose form in the same string. I assume the typo’s are probably in the ingredient name. I would propose a quick pre-processing step where you remove the strength and dose form. Should be relatively straightforward in e.g. Python. Then, re-import in Usagi with the RxNorm ingredients class as target. This should map most of your names with typo’s to the correct ingredient.
Thanks for the response. I have a few short but quick questions
Let’s say for ex I have source drug name as “Metformin 850 MG”. I understand that you are suggesting me to split the above string into 3 parts as “Metformin”, “850 MG” and “TAB”. But my question is in the drug_concept_id field of drug_exposure table, should we key in the concept_id for “Metformin 850 MG” which is 44041258 or “Metformin” which is 1503297?
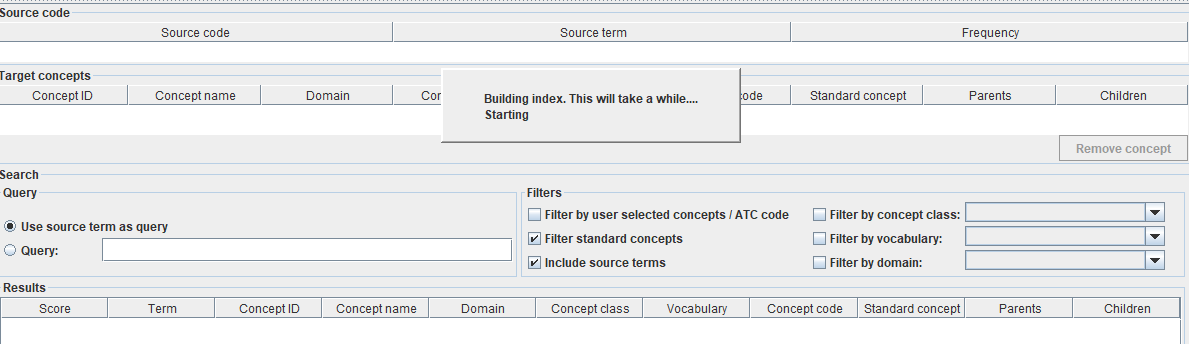
Second, regarding Usagi I encounter something unusual with my Usagi execution. For ex: today all my mapping output is “Unmapped”. I am not sure why. I uploaded the vocab files and built index when I downloaded Usagi and it was working fine couple of days back. But today the output is just “Unmapped” for all my source values. Any idea on why can this happen?
How long does building an index again take? Because It’s been running for more than 45 mins but it isn’t complete yet. My laptop specs is given below
Though when my index was built successfully last time, I couldn’t find any values populated under the “Filter by concept class”, “Filter by domain”, “Filter by vocabulary”. Do you know why the filter values aren’t shown in drop down?
I assume by the below, you are asking me to use the filter and set it to “RxNorm”. Right?
You could try using Jaro-Winkler distance to calculate similarity and choose the most appropriate concept. Had a previous experience building a typo-correcting input validation system, this simple metric allowed to mitigate ~96% of spelling mistakes.
You would want to use 44041258 indeed. But to get to that concept, splitting into ingredient name, strength and form might help. See linked poster in my previous reply.
That is interesting, there can be many reasons for this, so hard to tell what it is for you.
Something has gone wrong then in the indexing of the vocabulary files. Your index files (created in the same directory where you run Usagi from), should contain a file named ConceptClassIds.txt, DomainIds.txt and VocabularyIds.txt. I suspect that these have not been created for you.
Yes, set the vocabulary filter to ‘RxNomr’ and class filter to ‘Ingredient’