I have a dataset that contains NDC, Brand Name, and Generic Name fields.
My question is how to find out whether an NDC belongs to a brand named drug or generic drug.
I checked the FDA new API, and they also provide the brand and generic names along with the queried NDC. The only thing that FDA offers to help for this matter is a pdf that contains a list of all generic drugs names but without their NDC codes, therefore, it is not useful!
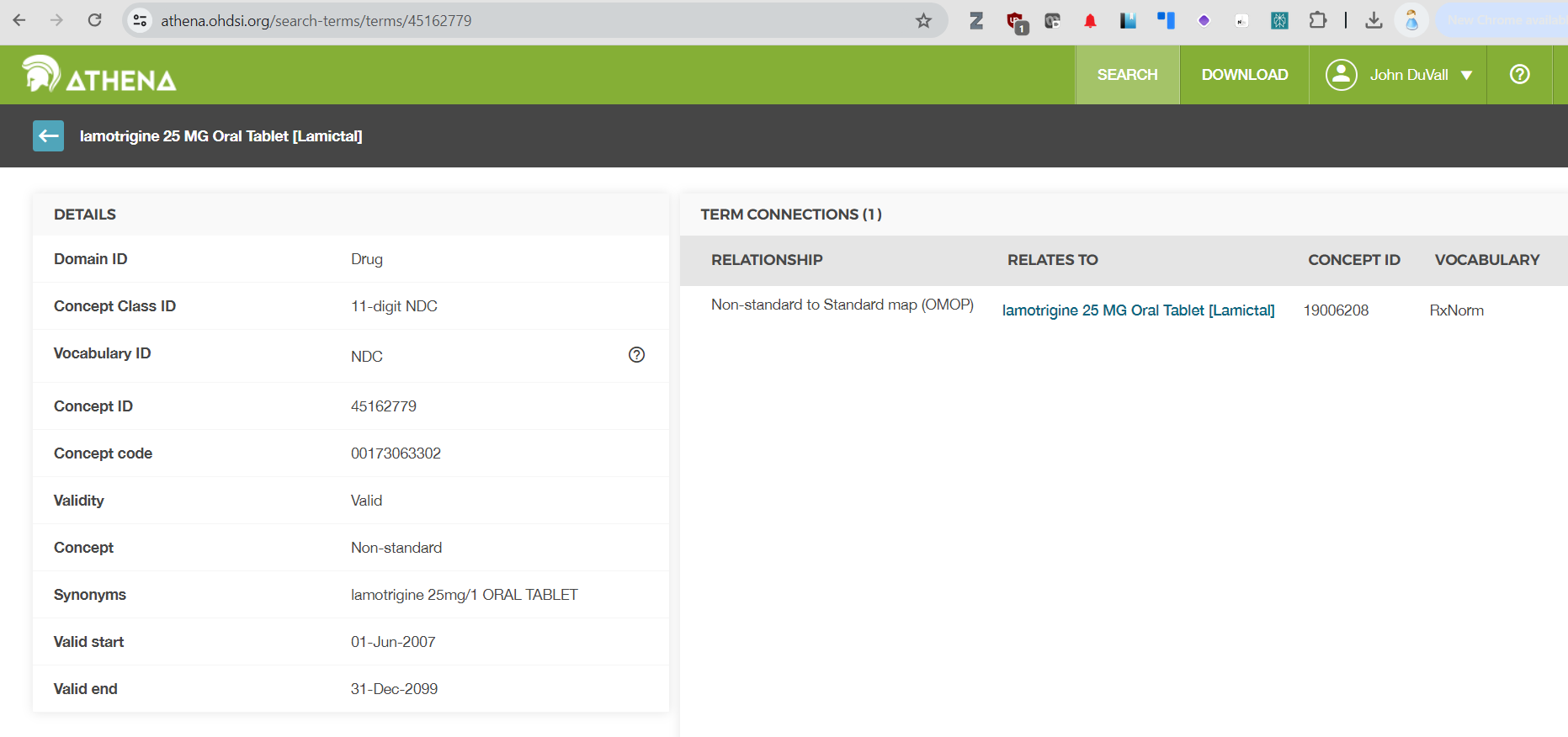
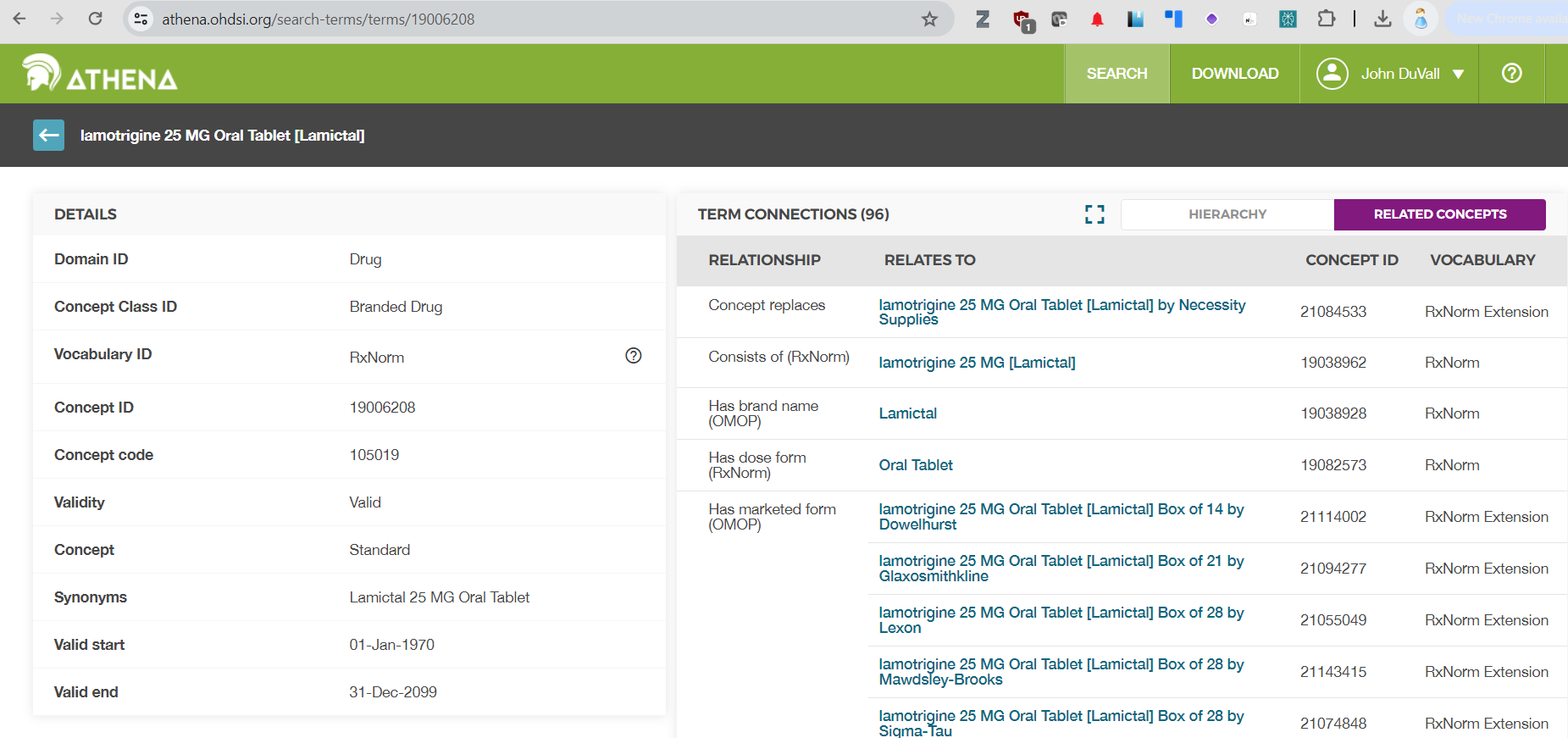
@Ramy_Alsaffar: What @Gowtham_Rao is doing is to filter for Branded drug concepts. But if you have an NDC, just follow the mapping to the standard RxNorm, and it will tell you if it is Branded or not.
You starting line indicates that you probably don’t have OMOPed data but you want to only use OMOP Vocab to get a nice NDC-based lkup table.
You need to download the vocabulary and make sure you have it in a database and indexed. The joins in the query below can be slow if not indexed.
Consider a similar query (for ATC) that was “walking” the realtionships just like you need to do too.
select
atc.concept_id as atc_id, atc.concept_name as atc_name, atc.concept_code as atc_code, atc.concept_class_id as atc_class,
ndc.concept_id as ndc_id, ndc.concept_name as ndc_name, ndc.concept_code as ndc_code, ndc.concept_class_id as ndc_class
from concept atc
join concept_ancestor a on a.ancestor_concept_id=atc.concept_id
join concept_relationship r on r.concept_id_1=a.descendant_concept_id and r.invalid_reason is null and r.relationship_id='Mapped from'
join concept ndc on ndc.concept_id=concept_id_2 and ndc.vocabulary_id='NDC'
where atc.vocabulary_id='ATC'
Your starting point should be different. The query above starts with concept table and the ATC vocab. You may want to start with branded drugs or all ingredients.
For each join - study on what it joins.
If you struggle, ask for further help. Once finished, consider posting your final query.
Thank you very much Fabricio.
I tested the code and it works perfectly.
However, I just want to double check few points about NDC formats, the TTY types, and missing NDCs with you please.
1-
I have an 11-digit (5-4-2) NDC format dataset. Does NLM have all NDC formats in their database? or there is a limitation here?
I printed the intermediate values of your function and saw that the available NDC formats are either 9 or 10 digits. Basically, my 11-digit NDC is being converted to 10-digit NDC.
2-
I applied your function on a subset of NDCs and found that several NDCs do not exist in the NLM database. Do you know or recommend another API that I can query those missing NDCs?
3-
In your code, you are assuming if a drug is not brand named then it is a generic.
But I checked the TTY page, and there are few TTYs that do not specify the drug category whether it is a generic or brand named like: (SCD, SCDC, SCDF, PIN, MIN, PSN…)
Could you please give me some explanation about these other TTYs.
RxNorm is the only free resource I know (commercial databases might also have this data). From an analysis I did (see https://github.com/fabkury/ndc_map/blob/master/ddcs%20-%20AMIA%202017%20Poster.pdf), 15-22% of the NDCs found in Medicare and all-payer databases are not recognized by RxNorm, but the unrecognized NDCs might represent as little as 2.4% of the total prescriptions (which is the case of Medicare data).
RxNorm CUIs can represent different things, from an individual generic active ingredient to a particular drug product on the market; but NDCs represent labeler + active ingredients + packaging, so, from the perspective of telling brand-names apart from generics, you shouldn’t find RxNorm CUIs with “ambiguous” TTYs when querying /ndcproperties.
I ran through the RxNorm API a random sample of 4,000 NDCs from the FDA NDC database and not a single one of them had a RxNorm CUI with “ambiguous” TTY – all RxNorm CUIs either had a brand-name TTYs (BPCK, SBD), or one of the generic TTYs (GPCK, SCD), or were completely unrecognized (no RxNorm CUI found for the NDC). If you’re concerned, a good approach could be to adapt the function I wrote to return the TTY itself, then produce a frequency table of them.
Thanks for your reply.
I tried to register an account to download the dataset filtered by @Gowtham_Rao, but I am getting an error msg to contact system administration. I sent an email to "support@odysseusinc.com" about this problem but didn’t receive a reply yet.
@Ramy_Alsaffar - some of our engineering team members are still coming back from holidays - please allow a couple of days to investigate and respond to the issue you are facing. Apologies for the inconvenience that this is causing
I hope I am not giving you a headache, but I have few more question for you please.
Regarding the problem of identifying Brand VS Generics, I followed your algorithm and it helped me identify a good percentage of the NDC codes I have.
However, by coincidence, I found few hundreds NDC codes that are associated with ANDA but are identified as brand-named drug by using TTY.
My understanding is that NDA codes belong to brand-named drugs while ANDA codes belong to generic drugs.
Is there a scenario where a drug associated with an ANDA is considered as brand-named instead of a generic drug? Or this is simply a mistake?
My second question is related to mapping NDC codes to NDA codes. I started a new topic, please follow this link if you want to join solving this problem:
And my third question is related to Authorized Generics, please follow this link:
Also, if I want to contact NLM directly about their data, do you recommend someone that can reply to my questions officially?
@Kyle_Pestano: What @Mike_Nerovnya said. But there is a cheapo way of doing it: Take the mapping to RxNorm, and it will tell you whether the mapping landed on a Branded or a Clinical (not branded) drug.
Hi @fabkury Thank you for providing this solution.
I’m encountering 1 issue with this solution, there are a few NDCs having multiple RXCUI value, and having different TTY what should we consider it, a Branded or Generic medicine then?
Do those target RxNorm codes belong to the Ingredient class? If so, the source NDC concept is obviously generic, as Ingredients can not have a Brand Name; if not, this is a bug that needs to be fixed.