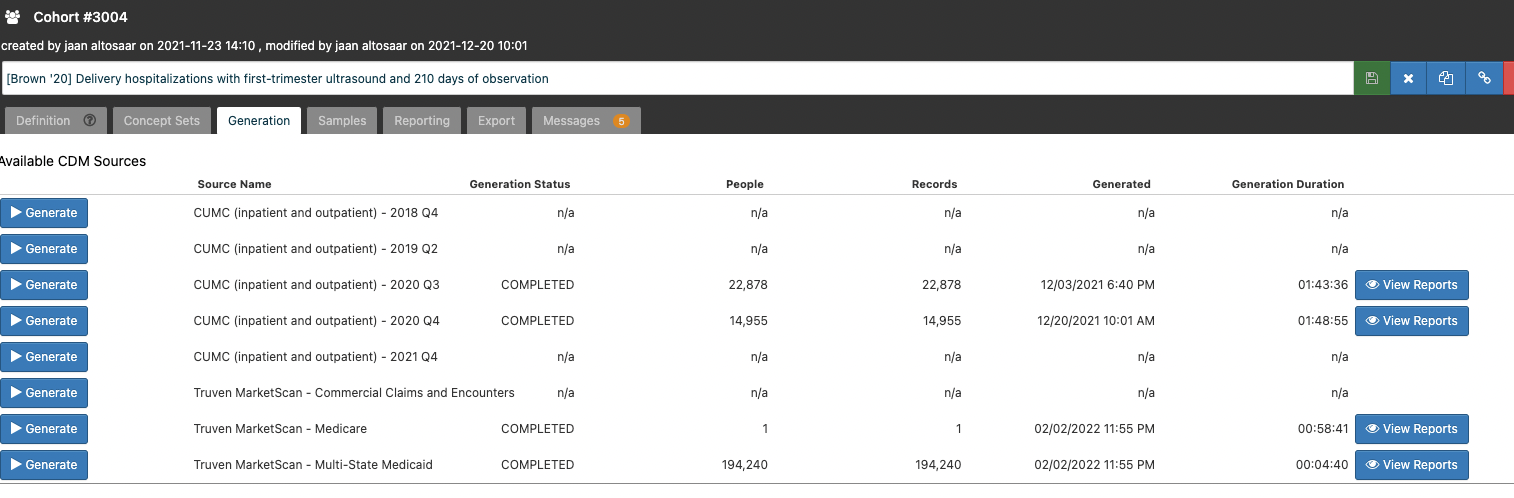
Note that there are 100k+ people in the other data sources, but only a single person in Medicare.
How would you debug this?
Any help would be appreciated. @toekneesunshine and I looked at the exported SQL but it is messy, and all the concept sets are compressed into a single line, so something like a stack trace or binary search to comment out parts of the query will be difficult. Has anyone debugged errors like this that are data source dependent?
Alternatively, is there a point person at Truven to ask about potential preprocessing in the data that is different than the Multi-state Medicaid data, leading to only a single person in this cohort?
Hi @jaan , it looks like your cohort is looking for pregnant women. Note the ibm marketscan medicare database only contains retirees who opt for supplemental medicare coverage, so this is almost all >65 years old, so we wouldnt expect to see pregnant women in there.
Thanks for sharing your JSON, it makes it easy to diagnosis what may be going on. A quick look, I think it has to do with your first entry event: ‘SMM 17-21 procedure indicators’, which appears to have some codes that wouldn’t be exclusive to a pregnancy episode, and these procedures aren’t being restricted to either an inpatient visit or requiring a condition indicating pregnancy.
MDCD, MDCR, and CCAE will likely have similar diagnosis codes, but the impact on pregnancy-related codes will be quite different (since MDCR generally shouldn’t have pregnancies).
CUIMC will have different codes, given that its EHR and not restricted only to ICD-based billing codes.
Would a histogram of codes in the cohort definition across MDCD, MDCR, CCAE, and CUIMC help understand whether the pregnancy-related codes or the lack of ICD-based billing codes in some data sources is the issue?
I am also wondering whether looking at the ETL pipeline for these data sources, to see how the data is loaded into Atlas could help understand why MDCR only has a single patient compared to the others.