I know it could better asked on stackoverflow but it seems it is more friendly here and I get more information related to OMOP.
There are quite some 800 files and let’s say 1 million lines in each text file, which is actually fixed width csv.
How do you process data at that size?
I know a bit of programming but I am terrible at C++ (and probably it is not worth my time to learn the whole thing but to wait for Python to run overnight).
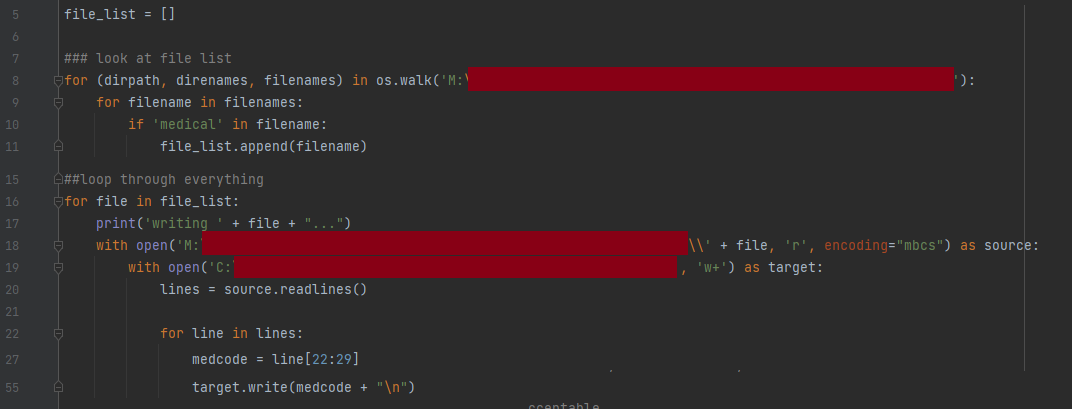
I used very basic vanilla Python packages. Those are open(… ,“r”), loop each line and edit, then write the lines into a new .csv. The program is very slooooooow, it likely takes 6 hours for a run (and who know I get an error in the morning).
And every line has to be edited of course, mapping to OMOP, before feeding into SQL.
So the real problem is, what kind of Python package you use to read and manipulate file at that big size?
Or can I feed it into SQL first and then manipulate from there, would it be a lot faster? Since it is on a HPC.
Hi
have you thought of using pyspark?
is scalable it terms of hardware , you can do more with less hardware but it can be more hard the logic of thinking in map/reduce, but with pyspark it can seem like a supercharged pandas.
What kinds of processing are you trying to do? Can you process CSV files one record at a time, or is there some window (per-patient?) that must be tracked? I think knowing more about the requirements would help us make a more informed recommendation.
You say your input is “fixed width csv”. I’m not sure what this means. Is it actually comma separated? and if so, do cells use double quotes? I ask because the primary expense of reading text files is often parsing numeric values, instead of leaving them as a string value.
Let’s say it is a fixed-width text file, well defined. So it can be turned into a comma separated csv. Each line in the text file represents a medical record. I will manipulate it such that it can be OMOPed onto a SQL.
Great. Just to clarify, you say “loop each line and edit”, is this edit local in scope, it only requires data from that line?
So. In this case, you can quite efficiently zoom though each file, pulling only the fields you need. Make sure you don’t parse content (ie convert to a number) that is discarded or simply passed-though. In particular, I don’t think importing the data into another system is going to be any more efficient than processing the file directly.
If your Python script is in a public repository, I could look and comment. I’d first look to see if you’re doing any unnecessary work or memory allocations. If that doesn’t do the trick, consider using Julia (or any compiled language, like Go) instead of Python or R, both of which are interpreted.
You can also write the parser, mapper, and insertion into an OMOP database using Java with a JDBC connector to the OMOP database. What you describe is a relatively simple program to write and executes on anything - just a matter of time depending on your computer memory and disk performance. I do this importing EHR, ECG, and EMS data into OMOP.
Interpretive languages are going to be much slower to execute compiled languages. If speed and low memory constraints is an issue - I’d also consider C and C#.
Thanks. Indeed it is a relatively short script. I suspect it is a language issue or if there is a package that the underlying thing was written in C++ that could be faster