Hello everyone,
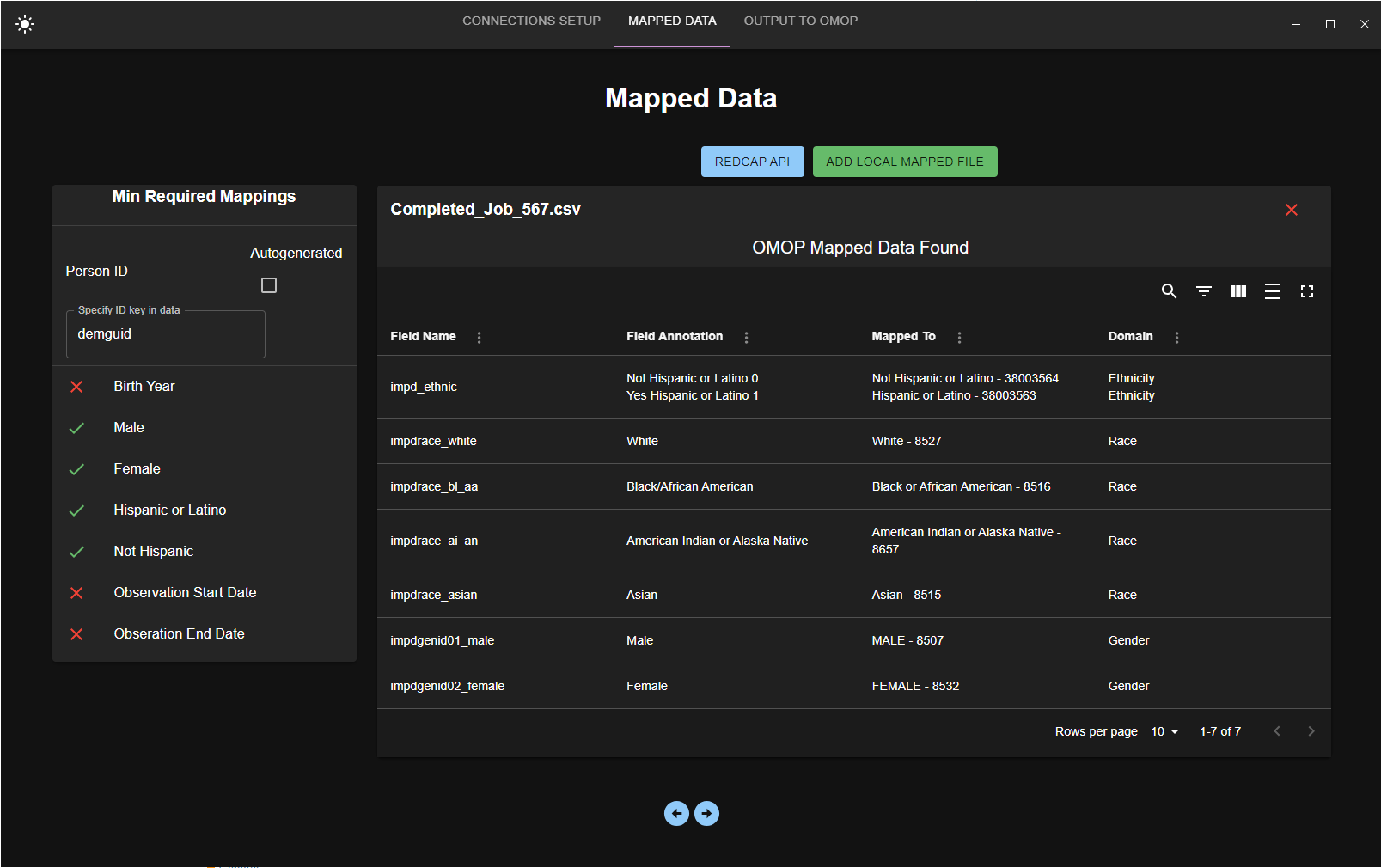
I have created a web app that compares form survey questions/answers/custom text to standard SNOMED terms (the vocabulary can be expanded, just keeping it SNOMED for simplicity at the moment). This was developed to go from REDCap data to the OMOP CDM. Now, there’s an interface to submit the REDCap data dictionary and it returns the top 5 similar standard terms. Once someone goes in and maps all these survey questions/answers to a standard SNOMED concept they can export it to a CSV/XLSX.
Once we have this mapping CSV/XLSX, we can import this file into the desktop companion app, perform the ETL, and spit out some SQL files or just directly write to a database if we wanted to. The reason we made it a desktop was to avoid the many security implications being on the public web since at this point we will need to obtain the actual patient answers (PHI). I’m at the point where I’m doing the ETL logic for this and I have come across some rather difficult challenges. The first being the ‘person’ table requires the race and gender. I have added a field in the desktop app where the user can specify the key name for where to get this data for the person. However, the values for this data can vary wildly in REDCap. We aimed to make this as flexible as possible and not just for our use case. This presents a challenge that requires yet another stage of mapping unless I have all this mapped data at once. Is this the usual case? Do you map all of your data at once and then perform the ETL?
Any sort of guidance or tips would be greatly appreciated.
Thanks all!