I am from the vantage6 development team and am looking into coupling the OMOP CDM to our infrastructure. I’ve tried several things, but am looking for some advice an thoughts on this topics. Let me start by explaining our initial idea without too much prior knowledge about the OMOP CDM.
Disclaimer: Sorry if I made any errors, assumptions or silly remarks bellow as I am by no means familiar with the OHDSI tools
Initial Idea
Vantage6 typically requires record level data to do its analysis on. So the initial step was to determine which tools we can use from the OHDSI community. The following steps had to be executed:
Create JSON cohort definition ← Using ATLAS or OHDSI/Capr
Cohort Creation ← vantage6 uses OHDSI/CirceR and OHDSI/SQLRenderer to construct valid OMOP CDM SQL. Finally the OHDSI/DatabaseConnector can be used to create the cohort table.
Data Extraction
Option 1: we extract data from the OMOP CDM and create a fixed tabular dataframe for the cohort
Option 2: the user can specify which data items (based on concept ids) are extracted
vantage6 post processing ← not so interesting for this post
vantage6 analysis ← not so interesting for this post
This can be done as we already have a somewhat working prototype of this. Jay! The downside of this approach is:
vantage6 requires a direct connection with the database (WebAPI would be safer/preferable)
A lot of custom code has to be written for step (3), which needs to be maintained.
So a preferable solution would be to use OHDSI/FeatureExtraction preferably in combination with OHDSI/WebAPI. After playing around with both packages for a little bit, I have some questions/remarks:
The FeatureExtraction module adds a layer on top of the CDM. With that I mean I do not have complete flexibility to extract the data I want and am stuck with the convetions (interface). this package gives me. ← Am I wrong here?
The webAPI does not let me access the FeatureExtraction but only the analyses (webapi/feature-analysis) that make use of this module ← There is no way to retrieve the FeatureExtraction data or submit a query from this interface?
Please let me know if you have any thoughts on this, much appreciated!
PS: vantage6 is mostly written in Python, to avoid doing things twice we intend to wrap all used R packages into a Python interface, these will be shared back with the community PPS: I was only able to add two links to this question, so I had to remove all links, sorry about that…
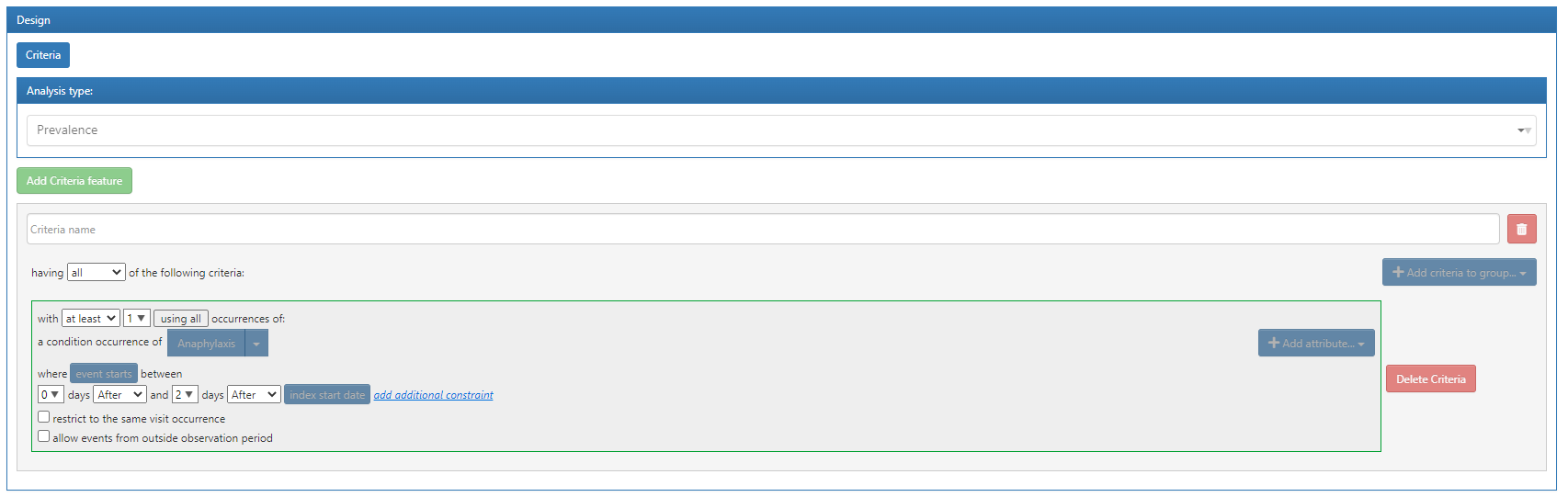
There are pre-defined analyses in FeatureExtraction but there is instructions in the vignette on how to create ‘custom features’ which is simply creating custom SQL that will build the features and telling FeatureExtraction to execute it.
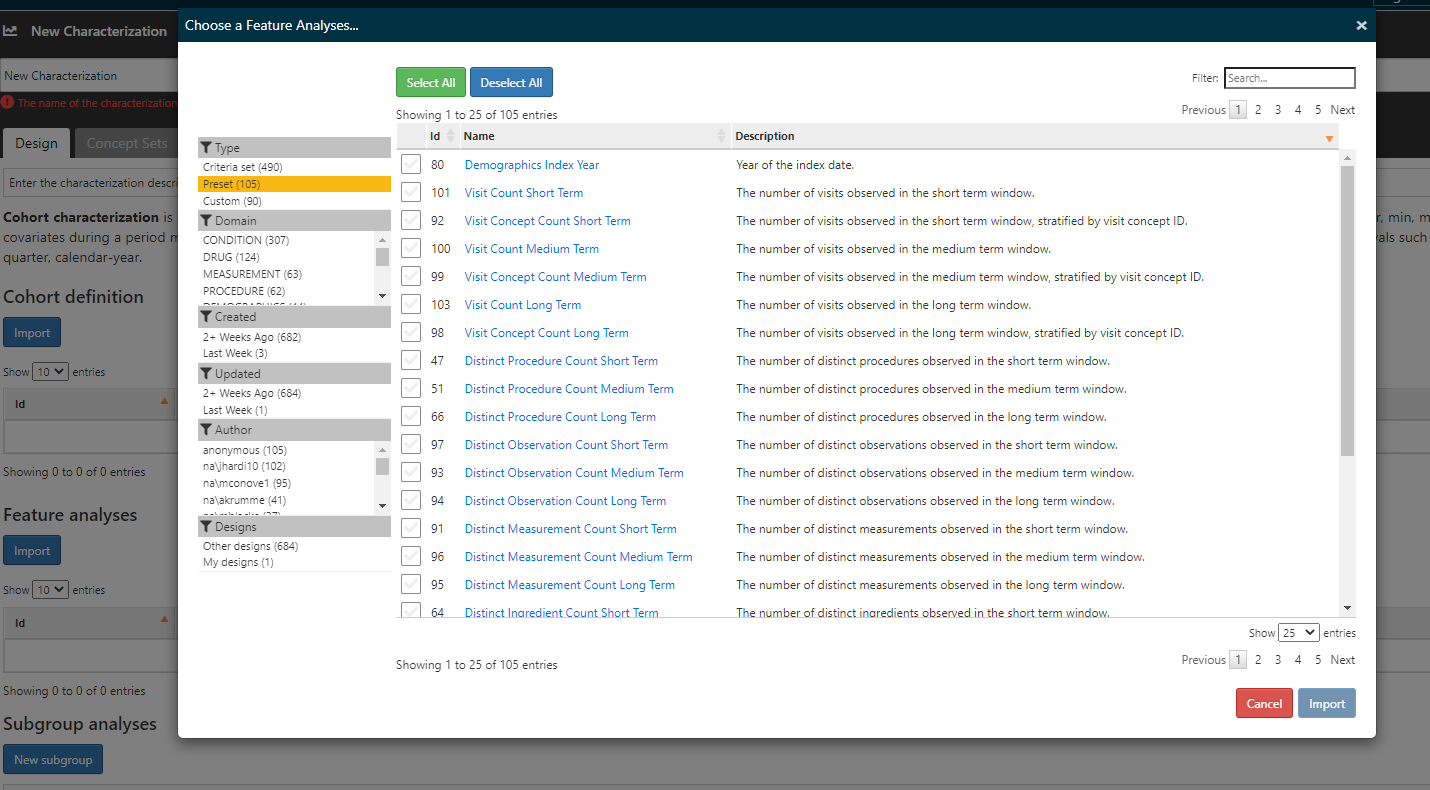
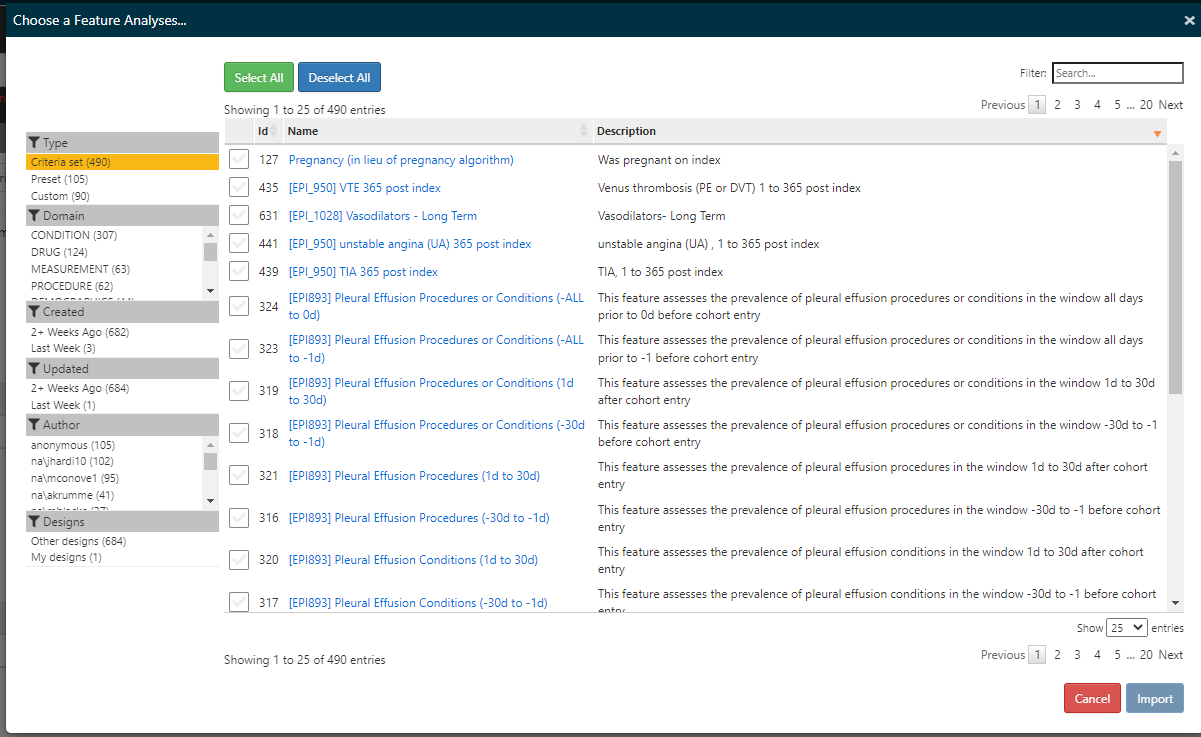
You can do this in Atlas by defining a ‘custom feature’ as a SQL expression in an Atlas Cohort Characterization. You can also define features using cohort definition criteria expressions. By default, Atlas will present ‘preset’ features, but you are able to create custom features as well. here’s a screenshot of Atlas where you click the ‘import’ under ‘feature analysis’ in Cohort Characterization:
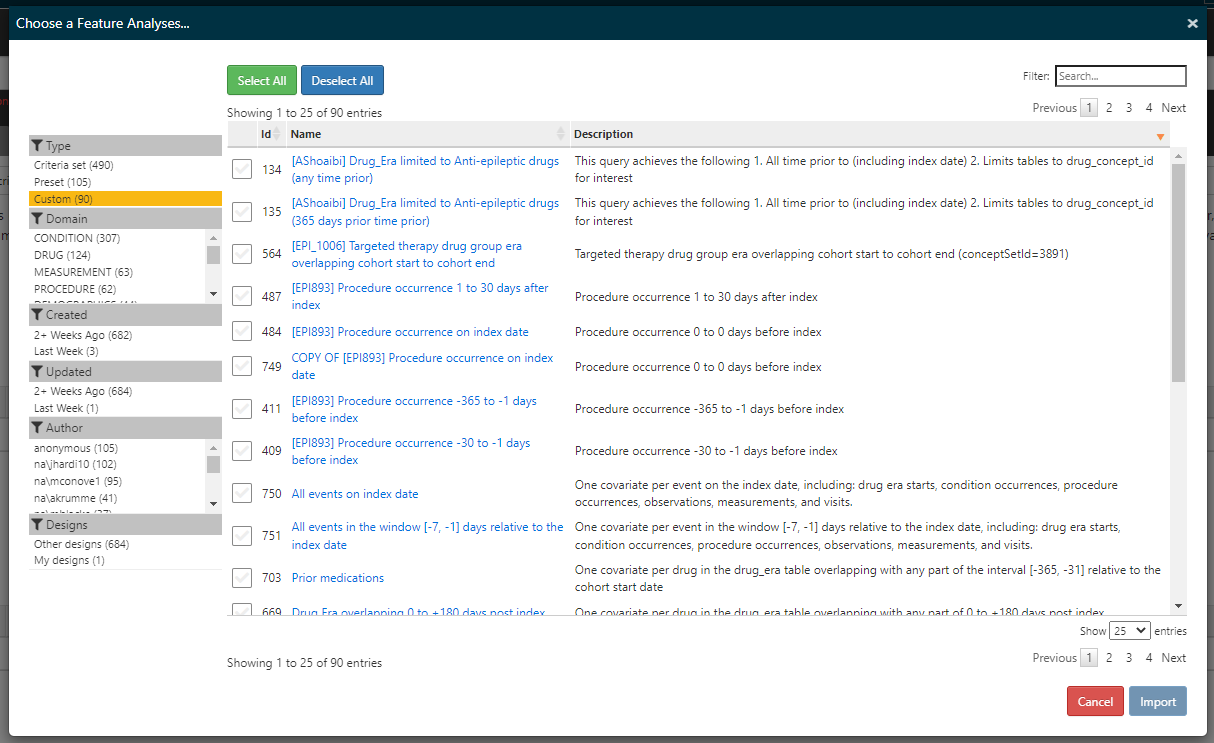
The above is filtered to just the ‘presets’ and you should recognize these as the standard Feature Extraction analyses. But in our env we also have customs:
‘Criteria Features’ are safer because it’s pretty well tested going from criteria to SQL. If you go the route of writing custom sql, you may have more trouble because of syntax errors and such that you won’t find out until you try to execute the analysis.
I should also add, the way Atlas uses FeatureExtraction is to population level characterization, meaning that the results saved to the DB are aggregated statistics (ie: counts) of number of people with the given feature. If you are trying to create a study population where you have patient-level records with features for use in things like building a PS model, then you will have to do that in R, as Atlas is focused on the characterization (ie: aggregated view) and not the patient level features.
I wonder if I am missing something. I’ve heard people talk about federated analysis using the OHDSI tools. With which tools do they achieve this?
I am assuming all participants compute their aggregates and share these (in some way) with a neutral party that combines them. So how would a participant compute their aggregate? Through ATLAS? That would mean that the WebAPI offers enough to do such analysis (or are we talking about very simple analysis, like descriptive stats). But aggregates for federated learning do not always make sense on their own, for example when computing an average the neutral part requires the sum and count of the covariate.
I think I can use the FeatureExtraction module to obtain the covariates, however I am still looking for a way of doing this through a HTTP request rather than setting up a SQL connection directly from vantage6. Ofcourse we can write a tiny app that hosts an API on top of the OMOP data source, but I don’t want to reinvent the wheel.
All of them. A study package (and in the future, a Strategus analysis specification) is defined and distributed across the OHDSI network (ie: anyone willing to perform the analysis) and, because the tools are standardized, the results are generated in a standard form. A coordination center will receive the analysis results (which can be something like a Characterization (ie: aggregates) or something more complicated like a Population Level Estimation (ie: risk ratios) or a prediction (ie: a model). Typically the network execution is not done inside Atlas, but it is feasable to have one of the analyses from atlas run, and then a ‘coordinating Atlas’ could be configured to render results from different ‘sources’ (ie: the nodes on a network). But, in practice, this is usually handled by a custom Shiny application to view results.
I don’t think we aggregate results across sources to calculate a sort of ‘meta analysis’ for things like proportions, but we do ‘aggregate’ results into the same shiny app so people can browse results by data partner. We do a meta analysis based on Population Level Estimatinos, tho, in the case of producing forrest plots for risk ratios.
If you mean covariates at the person level, then no there’s not a HTTP service that implements an endpoint to yield patient level covariates. Closest thing there is to that is to interact with WebAPI via HTTP to create Characterization designs and kick them off via HTTP and fetch results via HTTP (which is effectively what Atlas does, but at the population-summary-level not at the patient-level).
I think the easiest way to do what you want is to implement a PlumbR API that wraps FeatureExtraction functions but provides a HTTP interface to those functions. Most of our libraries are built to be ‘interactive’ (ie: make a call, look at data futz with settings, run again). If you were to put in an HTTP api in something like plumber, you’d want to define a sort of ‘business transactions’ that receives a standard input (like a JSON document) and defines a standard output. Most large-scale operations coudl take hours, so this isn’t something you’d want to do with synchronous HTTP (ie: request-response) and instead you’d want to define some sort of job-scheduler that performs the workload async (much like what WebAPI does for CDM analyses).
is “Go through the Save our Sisyphus tutorials”. This was a comprehensive 2-month series of weekly tutorials (Mar-May 2023) that tell you everything you need to know about how to design and execute an OHDSI network study.