Hi,
I’m setting up an OMOP CDM datasbase & tools for the first time in our organization.
The configuration is as follows:
- HW: 8 Xeon cores, 64GB RAM, 2GB SSD
- OS: Windows Server 2019
- DB: PostgreSQL 12
- CDM: version 5.1
- Data: IQVIA IMRD (~13M patients, largest table ~2.3G rows)
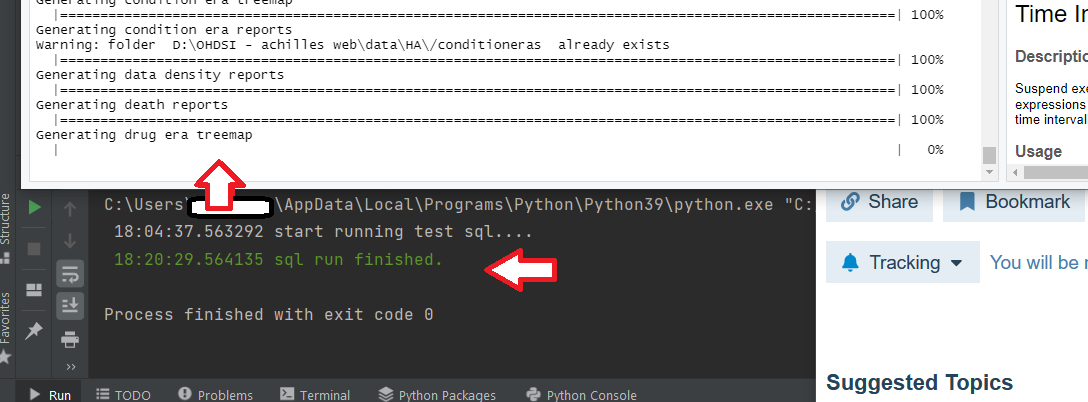
Following the detailed instructions, I’ve loaded the data, created constraints and indexes, and set up webAPI & Atlas. When running Achilles to create the data statistics I noticed that some of the queries take extremely long time to complete, so that running the entire SQL script generated by achilles may take few days (!).
My questions are:
-
What is the typical execution time of achilles initial run on a dataset of this size?
-
Are the sql queries generated by achilles optimized for a specific dialect? are the performance depend on the specific dbms?
-
for one query (11 Number of non-deceased persons by year of birth and by gender), a change in the syntax resulted in a large performance gain, which indicate that the query can be optimized for better performance:
The original (did not finish overnight):
SELECT
11 as analysis_id, CAST(year_of_birth AS VARCHAR(255)) as stratum_1,
CAST(gender_concept_id AS VARCHAR(255)) as stratum_2,
cast(null as varchar(255)) as stratum_3, cast(null as varchar(255)) as stratum_4, cast(null as varchar(255)) as stratum_5,
COUNT(distinct person_id) as count_value
FROM
imrd1903.person person
where person_id not in (select person_id from imrd1903.death)
the modified version (completed after 25 seconds):
SELECT
11 as analysis_id, CAST(year_of_birth AS VARCHAR(255)) as stratum_1,
CAST(gender_concept_id AS VARCHAR(255)) as stratum_2,
cast(null as varchar(255)) as stratum_3, cast(null as varchar(255)) as stratum_4, cast(null as varchar(255)) as stratum_5,
COUNT(distinct person_id) as count_value
FROM
imrd1903.person person
WHERE NOT EXISTS
(
SELECT NULL
FROM imrd1903.death death
WHERE person.person_id = death.person_id
)
Any other inputs and tips for improving the performance on the described system will be appreciated.
Thanks,
Guy.