Hi everyone, I connected R to Snowflake and ran the DQ dashboard. I’m curious to know whether the computation was done locally in R or utilized Snowflake’s computation power?
When using test data with 1000 patients and thread=1, it took approximately 38 minutes to complete the DQ check. However, my actual CDM data is much larger, with around 1,000,000 patients in the person table. What’s the optimal approach for running the DQ check on this massive dataset?
Great question! The heaviest computation occurs in the SQL queries run for each check - calculating the # of failed rows / # denominator rows.
That said, as you’ve observed, this SQL can be quite slow and is not necessarily optimized to use the full computational power of your warehouse. You’ve got a few options for speeding up your DQD run at the moment:
Increase number of threads. However, I don’t expect this to have a huge impact on a full DQD run because threading is done at the check type level. There are a relatively small number of check types compared to the number of SQL queries run for some of the larger check types (for example, plausibleUnitConceptIds has over 1000). If you end up disabling some of the check types you may end up seeing a larger impact from this option
Follow the instructions here to generate & execute SQL queries that parallelize execution of many individual check queries within each check type. This is a brand new feature and I’d be very happy if it ended up helping you out! The workflow is a bit clunky at the moment but if we find these queries are beneficial for many users we may consider refactoring the main DQD code to make available a similar approach
Disable any checks not necessary for your use case. Less checks = less queries = faster DQD run. Disabling the concept checks (i.e. set checkLevels = c("TABLE", "FIELD")) in particular could be very impactful. The concept checks have by far the largest number of queries run and in my experience eat up a large portion of execution time. There are only 2 concept check types, plausibleUnitConceptIds and plausibleGender. While I don’t love suggesting you sacrifice features as a solution, if you can live without these checks for your use case then this is definitely a simple option for you. I’ll note as well that we are in the middle of a project to overhaul the plausible unit lists for plausibleUnitConceptIds due to reports of false positive failures on this check - another reason why you might be OK skipping it
Please let me know how it goes & if you have any additional questions!
All HADES packages are designed to run on large databases, and tend to perform large data operations on the server, not in R. Running DQD on a database with 1 million patients should not be a problem. (If it does take a long time that may indicate you need to scale up the Snowflake instance)
PS - I meant to add that all 3 of the above (non-ideal) solutions relate to topics we’ll be discussing & addressing in upcoming DQD development work - use of threading in R; approach to building/formatting the check SQL; what set(s) of checks to include by default in DQD
I’ve run DQD on a database with over 300 million patients.
Keep in mind, if you are restricting the sample size using database functions, it is likely going to still execute full table scan style reads on the database, unless optimized with indices on the appropriate data elements.
Make sure you are running DQD on a environment which will not encounter any network disruptions, or infrastructure disruptions. Sometimes virtual desktops/workspaces have timeout periods or black-out periods. These need to be disabled.
If you encounter specific trouble, please post! We can lend a hand. Good luck.
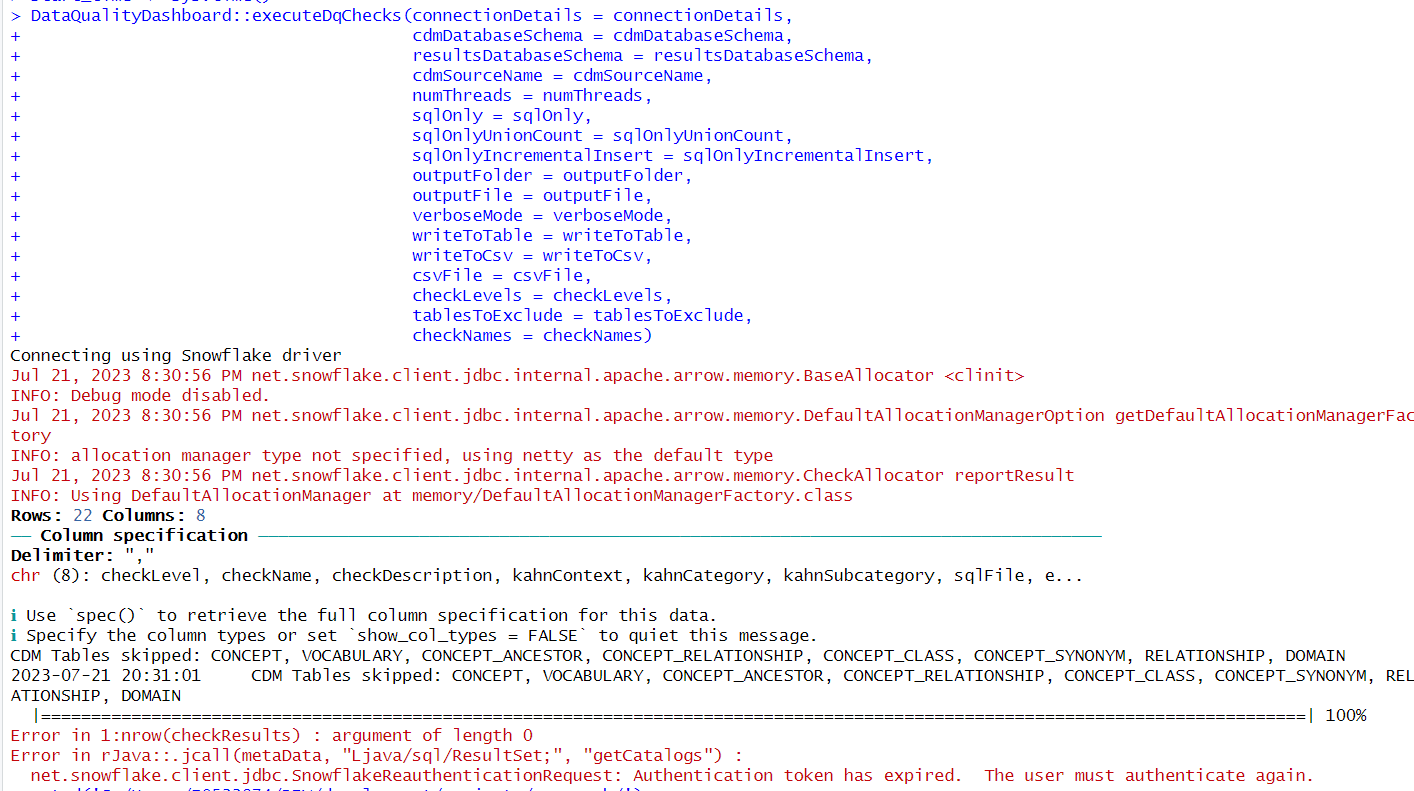
Thanks for your reply. After a long time run, it shows 100% complete but with the below error message. Does it mean the execution is not completed successfully?
Error in 1:nrow(checkResults) : argument of length 0
Error in rJava::.jcall(metaData, “Ljava/sql/ResultSet;”, “getCatalogs”) :
net.snowflake.client.jdbc.SnowflakeReauthenticationRequest: Authentication token has expired. The user must authenticate again.
Hi @Siyan , can you please share the full output from running DQD (i.e. what shows prior to the errors)? It seems potentially like you didn’t get any results based on that first error there…but hard to say since I’m not sure exactly where that got logged. Same goes for the second error which seems to imply your auth token expired sometime during the run.
One way to know for sure if it worked would be to check the output json file - whether or not one exists at all, and if so use the DQD viewer to review the results.
Thanks! It seems like no checks are getting run - I think that when DQD tries to reconnect to the DB in order to run the checks it’s getting that auth token error (the first time it connects, it’s pulling metadata from CDM_SOURCE). I’m not familiar with how Snowflake connections work; does this sound like something that’s expected to occur in your setup? Note also you’ve got numThreads = 20 which means you’ll be opening 20 simultaneous connections using the login creds you’ve supplied - not sure if this is related to your issue but worth flagging.
One other thing to note is that you have sqlOnly = FALSE but sqlOnlyIncrementalInsert = TRUE. If you were intending to run in sqlOnlyIncrementalInsert mode (and just generate the incremental insert SQL queries but not run them) you also need to set sqlOnly = TRUE. I will file an issue to raise a warning if this wrong combo of parameters is passed in, to make this more clear. I believe this is probably the source of the 2nd error you’re seeing; some code for sqlOnlyIncrementalInsert got run that’s pulling from an empty dataframe (I will also file an issue to fix this).