Recently, we had a bunch of industry folks come together, hosted by J&J, to discuss OHDSI and what is needed to help adoption and drive use cases. We ended up with a good list of challenges. I am sure the public sector has exactly the same kind of belly aches, so it makes sense to me to deal with this at the community level.
One of the high priority items is cataloging data available in CDM. Or course “available” is not a formal or contractual obligation. Instead, since OHDSI is an open collaborative, every data holder is free to make the data available to research by people outside their organization or not. But since they are participating in the OHDSI community, my hunch is most if not all of them should be interested to conduct research in collaboration.
Except we have no way of knowing who has what data and what is in it. This posting is to ask the community if folks are thinking or working on solutions like that, that we could promote to the collaborative.
Fantastic challenge! The data catalog is a very hot topic in the Pharma / Heathcare industry - I believe there are a few commercial and open source products (CKAN/DKAN) floating out there, some are actually pretty good, all would require some (intense) level of customization and integration. And depending on who you ask - they can be very broad or very focused.
In my mind, a typical Data Catalog is, essentially, a registry of data sets. The registry can be used by the users to discover data sets that are relevant for a certain task at hand based on a set of metadata attributes and data set stats describing it.
Regardless, the main challenges that always need to be addressed to keep data catalogs alive and useful are:
keep data in the data catalog fresh and up to date, in sync with source data
use of a standard, consistent and relevant vocabularies to describe the data set as meta data to improve the “discoverability” of data
integration into the business process where data is being used.
The data catalogs typically include the following meta data:
general attributes - name, description, time span, geographical location, ownership, license type.
business area/process relevant attributes - therapeutic areas, population, drug and diseases covered, population, geographical distribution, use of standard vocabularies. This information is typically generated by automatic data profiling tools and is integrated into the data catalog record. Achilles is a great example of one of this - just a fantastic tool!
data lineage - versioning, link with other data sets (raw data or analysis outcome insights) or even a process.
data quality attributes - describe the level of data trustworthiness.
compliance and security - data privacy related and access information etc…
The Odysseus Arachne platform is built to be used to conduct federated as well as local studies in a collaborative way. It includes a simple to use yet quite sophisticated data catalog. It is playing a clear supporting role within the business process (study) allowing data node owners to register and describe their respective data sets for the purpose of them becoming discoverable by study teams. The study teams use the Arachne data catalog to find data set and subsequently request and gain appropriate level of controlled access to it. Since we have integrated it with OHDSI Achilles, the researcher can also use the data catalog record to perform a high level feasibility of the data set for a certain type of the analysis.
It is a very interesting topic - I would be happy to present what have been done so far and further discuss this in one of our OHDSI WG meetings.
In EMIF we have built a very customizable data data catalog running as webservice.
We use this tool now in multiple IMI projects which are communities with their own user permissions etc. Each can have its own questionnaire etc. Each database can add relevant publications etc etc.
You can define any type of multi level questionnaire with search facilities and compare databases.
Data custodians can log in and change their own information etc.
Achilles (and Atlas) is also integrated in this tool.
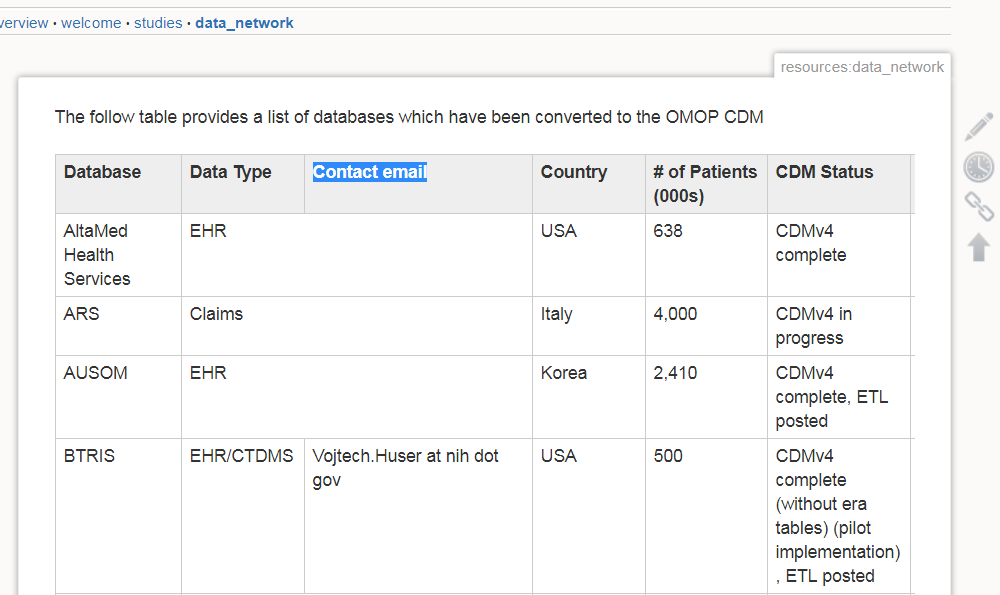
I support the addition of a good data catalogue and have proposed this before for OHDSI but there was little interest at the time. It could contain a lot of interesting information you do not get from Achilles.
The NIH has been trying to do this for a while. It’s wroth looking at https://biocaddie.org/ for what the funding agencies are requiring. The
primary bottleneck usually ends up being around incentives, and around
standardizing the fields to collect, and the values to fill in those
fields. This group, https://metadatacenter.org/, is funded to fix that
problem.
Worth looking at Biocaddie + Cedar to see what can be re-used (or at least
see what has been tried, and didn’t work).
I’m leading the core development team at biocaddie and we have developed a biomedical data search engine called DataMed (www.datamed.orghttp://www.datamed.org). DataMed collects, normalizes, and indexes diverse biomedical datasets following a unified metadata model called DATS. If we are interested in building a data catalog for OHDSI, we can share our DataMed architecture and codes. Thx
From the VA perspective, the more we can point to the number of other
people in the community using and contributing to OMOP and OHDSI, the
easier it is to continue to get leadership support. So, I think this is a
great idea!
+1 on this discussion! (Just getting back from a long holiday so don’t mind my delayed enthusiasm)
@Vojtech_Huser I have colleagues that have asked each other for an ACHILLES profile of a data set before requesting access. It would be very ideal to find ways to both honor data agreements but also make it easier for people to perform basic searchable tasks. The problem the Wiki is that it’s fairly manual to feed information. There’s a lot of dead ends in the Wiki that never get the information they deserve.