This is the first time I’m using custom concept list for the propensity score model, so I’m not sure how exactly it works. If I need a specific list of concepts + demographics, can I just select concepts to include and add demographics from the default list? This will mean that I leave concepts to exclude empty.
@aostropolets Could you share the code you’ve worked?
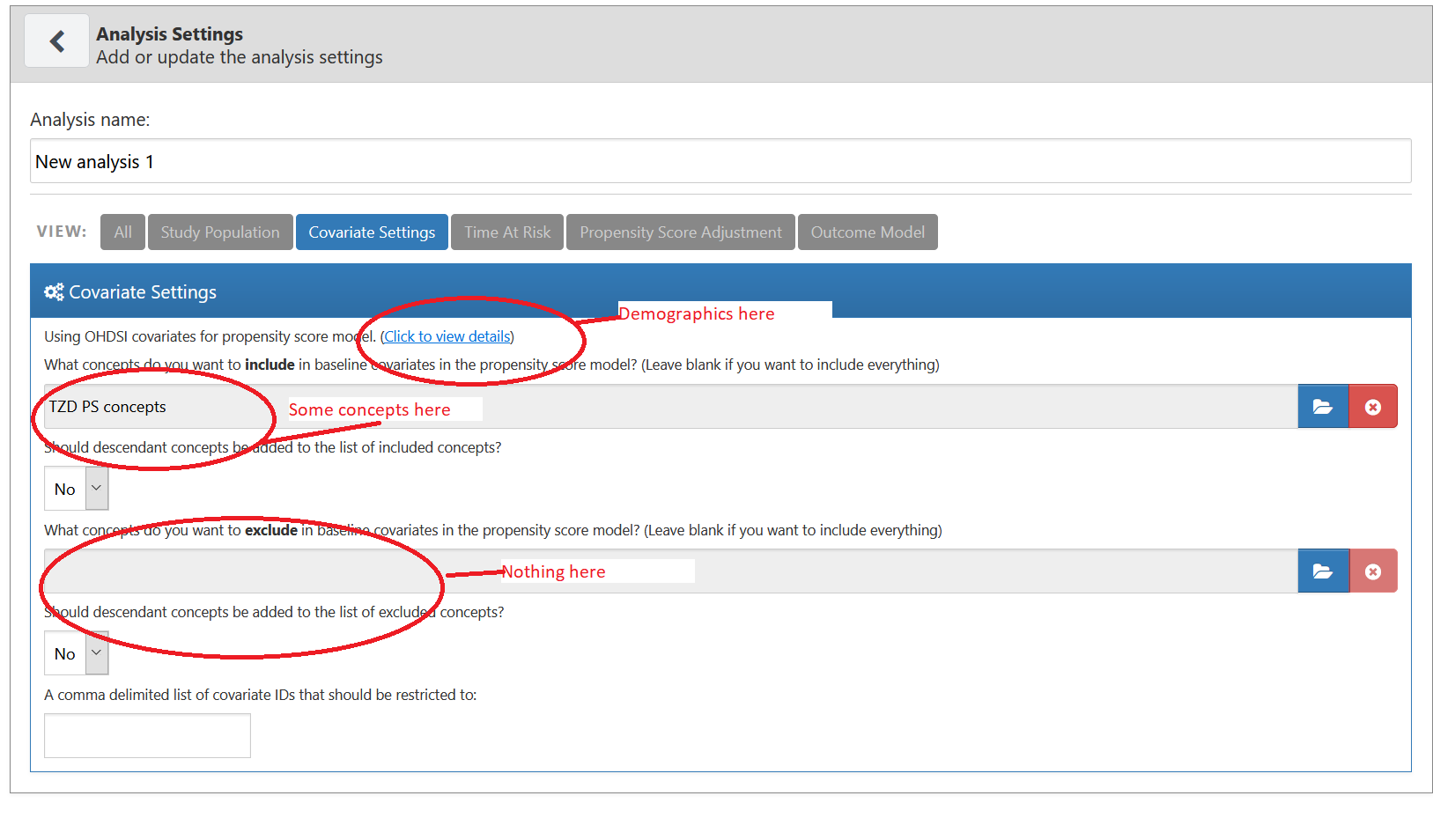
@aostropolets Though I’ve never used this before, but I think this would work 
Actually, the reason for this question is that I’m getting an error when running analysis with custom PS concepts.
The error occurs in the beginning of Cohort Method analysis and is as follows:
Error in strsplit(excludeConceptIds, split = “;”) :
non-character argument
Maybe, @schuemie has any ideas on what can be wrong here (I would be very grateful! ).
@aostropolets I cannot understand why you have an error with ‘excludedConceptIds’, because it looks like you’ve not used them.
It would be easier for me to find the reason of error if you share the code. Sorry, I’m not Martijn
This looks like a problem that was fixed a long time ago in the package skeleton. Unfortunately, updates move from skeleton to Hydra to Atlas to study package at a glacial pace.
Could you try replacing your R/CohortMethod.R file with this one?
2 Likes
@SCYou Thanks for reply! I asked Martijn because he knows these packages inside out and deals with these errors all the time
@schuemie Thanks a lot for suggestion! I tried it and doesn’t give me that error anymore. On the other hand, not it’s throwing
Warning: file("") only supports open = “w+” and open = “w+b”: using the former
Error in readChar(fileName, file.info(fileName)$size) :
invalid ‘nchars’ argument
I read that it may be because of an old version of Shiny but re-installing didn’t solve the problem. Do you think it’s about the package itself or about environment? I just run another PLE, which worked just fine; the only major difference was custom PS covariates.
It usually occurred when your file/folder system is not accessible. When did this error occur with which function?
At the beginning of cohort analysis. The thing is that I run the same package but without custom pa covariates and it runs smoothly…
Hi Anna,
I have the same error when using ATLAS 2.7.7 to build an Estimation Study.
Could you please share how did you fix this issue? (If you still remember)
Running CohortMethod analyses
Error in strsplit(excludeConceptIds, split = ";") :
non-character argument
Warning: Could not find logger DEFAULT
Thank you !