I recently tried cohort pathways feature in Atlas and have few questions.
q1) Let’s say I would like to find out the medication treatment sequence for T2DM patients.
Refer this demo to inspect my cohort and suggestions to improve are welcome
Target cohort - Patients with atleast 1 T2DM condition occurrence with 0 look back period. I guess look back period is not necessary here for condition occurrence. Because T2DM is always occurs once in life and people live with it. Right? I might be wrong… Any comments are welcome here
Event cohort - patients who had a drug exposure of SGLT2 Inhibitors, sulfonylureas, DPP4 etc. these are the drug classes followed for T2DM medication treatment. I have chose to exit the cohort based “end of drug exposure”
q2) cohort exit - For treatment pathway, does cohort exit strategy choice between “end of continuous observation” or “end of drug exposure” really matter? I understand the theory/idea behind cohort exit criteria. Here my question is only on does it really make any difference to this use case of treatment pathway? Meaning we are only interested in his medication treatment sequence. As the event cohorts look for presence of at least one desired medication (as configured), does exit really matter? Let’s say Jack has consumed Drug A from Jan 1st to Jan 31st and Drug B from Feb 10th to Feb 28th. Now whether I give end of continuous observation or end of continuous drug exposure with 30 days window, I will get the first line treatment as Drug A and second line treatment as Drug B. Am I right? any example to help me understand why to choose “end of continuous drug exposure” over “end of continuous observation”?
q3) Minimum cell count - I understand it’s about the number of people we wish to see in the event cohort to be considered as a pathway. But I also see something related to privacy here? How not showing the pathway can protect privacy? Sorry am not able to get this right here
q4) Combination Window - Let’s say I choose a value as “5”. I understand from Book of OHDSI, it is about medication overlap. For ex, let’s say we have Jack who is on Drug A from Jan 1st to Jan 21st. Whereas we also see him having Drug B from Jan 11th to Jan 21st. In this case the overlap between two drugs is 10 days which is greater than 5, so we will see this as a combination therapy in surburst plot. Am I right in interpreting this?
Diagnosis codes can be repeated throughout the patient’s history. A T2DM person may go to their doctor, and get their scripts renewed and there will be a coding for what the drugs are for. in the case of ‘0 lookback’, what about a person who just shows up in a practice after suffering from T2DM for years? With 0 days of lookback, how can you determine if this is a new case of T2DM? The reason why it’s an important question is that if you’re going to evaluate a patient’s journey through T2DM treatments, do you want to start watchign them in the middle of their journey, or do you want to ensure that they have just begun? You need prior lookback to determine that.
The cohort exit matters in the treatment pathway’s T cohorts because the T cohort defines the span of time you are going to look for events from your event cohorts. Do you only want to find events while the person is on an active treatment? Do you want to look for events any time after that first diagnosis? Your choice of exit determines what window of time you’re going to look at. For event cohorts, this is especially important because if you have event cohorts that start at first Rx and span the rest of time, you’ll have paths that look like A → A+B → A+B+C → A+B+C+D (ie: the exposures never finish). how you structure your event cohorts directly impacts how they will appear in the pathway analysis.
Some data vendors do not want you to report on any stratification of a popluation below a certain size. It is related to privacy laws. You woudn’t need to do this on a synthetic database.
Combination window isn’t about duration of overlap, it is about ‘proximity of dates’. If you have two different event dates that are fewer days than the combination window setting, those 2 dates will be brought together (hence the term ‘combined’) into a single date (the earlier of the two). This setting is used as a sort of ‘noise reduction’ where if you have a person that went A->B within the combo window and another person who went B->A in the combo window, then both people will be grouped as A+B.
Hi @Chris_Knoll - When I set a lookback period of 0 days and set it to earliest event, I will get his first time diagnosis for T2DM. Am I right here? Because since it’s 0 days of lookback, it will return all occurrence of T2DM dx codes from his data and when I pick the earliest, it gives us the first time he was diagnosed for T2DM and what was the treatment pathway initiated for his 1st T2DM. Isn’t this similar to finding persons who have just been diagnosed for T2DM?
As I am interested to find his medication treatment sequence, Under target cohort I believe I have to go for “end of continuous observation”. So that I can get all his drug sequence data whereas if I go for “end of continuous drug exposure”, that may not allow me to look at other drugs (except the one configured under exit criteria). Am I right? In latter case, I will not be able to find info on his other treatments.
Under “event cohorts”, since I would have selected a drug exposure of “DRUG A” in cohort entry criteria, now if I set “end of continuous observation”, it would still only consider “Drug A”'s presence in target cohort. Am I right?
I see that in your response here, you have chosen “fixed duration relative to initial event” with an offset of 1 day from start date.
Since in the event cohort definition, we have chosen “DRUG A” in the cohort entry criteria with 0 lookback, so it returns earliest event based on your setting. It returns 1st occurrence of “Drug A”. Since we already got to know that it is present in the event cohort, so you exit the cohort after 1 day itself? May I know the reason or it was just a quick example ? But if we do this aren’t we losing subsequent records which can prevent us from finding combination therapy items?
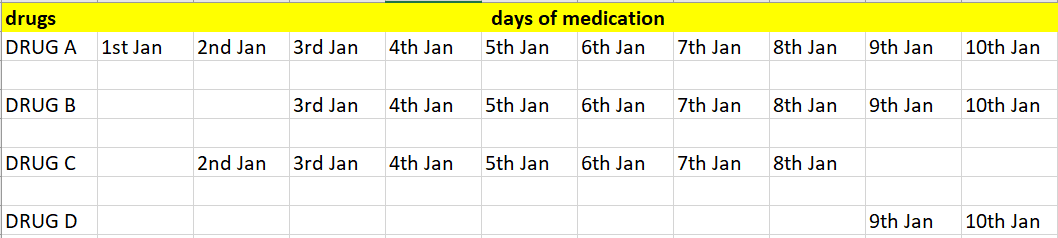
Let’s consider the below treatment sequence for a subject. tried to create it based on your pdf shared
Here for this subject, we know his 1st drug treatment is “DRUG A”. period
Next if I am gonna look at combination therapy and I set the window to be “5 DAYS”, then it’s “DRUG A, DRUG B and DRUG C” which are under combination therapy. Am I right?
If I set “2 DAYS” as combination window, then all 4 drugs would be under combination therapy. Am I right?
I did have a look at the pdf file that you shared.
Now based on your explanation of
By event date, for our usecase of treatment pathways (finding drug treatment sequence) it can only be drug exposure start date? Am I right?
Here event date for DRUG A - Jan 1st
event date for DRUG B - Jan 3rd
event date for DRUG C - Jan 2nd
event date for DRUG D - Jan 9th.
Now if our combination window is set to “5 days”, then I will still get DRUG A, DRUG B, DRUG C to be part of combination therapy. Am I right? So basically, if the difference between 2 event dates (drug A start date and drug B start date) is less than the combination window (5 days), then it will be considered as combination therapy?
This is a riddle, but you are right, and you are wrong. You are right in that the ‘earliest’ will return the first record of the event occurring. You are wrong that it is the person’s first, because unless you require a certain amount of prior observation, you can’t assert that this person is a ‘new’ diagnosis of T2DM.
Consider this: a patient goes meets a doctor for the first time. The doctor starts a new file for this patient, and so the person begins the observation period with the doctor. The doctor asks about his current conditions, and the person says ‘I have T2DM’. The doctor writes that down in his records for the first time that this person is T2DM. Is this person newly diagnosed? If you were to search the records of all people with T2DM with 0 days of prior observation, you’d identify this person. But this person isn’t a ‘new’ case of T2DM.
Consider another patient of this doctor. This patient has been with the doctor for a year. One day, the patient walks in and gets a test that results in a diagnosis of T2DM. The doctor writes it down, and the date of the diagnosis is 367 days of this person’s observation period with the doctor. This patient in this case is a ‘new’ case of T2DM because you have 367 days of prior observation to determine that this person has been ‘clean’ of T2DM and now has it.
I hope that makes sense. There’s been a few threads around the forums that describe this, so you may need to so a search on the forums to get more ideas on this topic.
That’s fine, so if you want to see any drug exposures after the diagnosis until the end of the person’s observation, then you just set the T’s cohort exit to end of continuous observation. If you wanted to see only those drugs during the period of a continuous drug exposure, then you’d set the exit to be the continuous exposure. These are two completely valid use-cases but give you a window of time that means different things (all time after vs. only during a period of continuous exposure to a drug).
If that Drug A event cohort is the only event cohort in your analysis, then it will only look for Drug A’s presence in the Target cohort but only during the time window defined by the target cohort’s start and end date. If a certain patient experienced Drug A prior to entering the target cohort, then it won’t appear in the result unless you set drug A to have recurrent episodes (by defining a cohort exit. If you make your Drug A event cohort never end, then you won’t see it in the pathway if it begain prior to the T’s cohort start date.
For lookback, you can set the days to 0 in your event cohort because you really don’t care if there is enough prior observation to determine if there is a washout or a ‘new’ exposure to the drug. However, setting the lookback to 0 doesn’t mean you return the earliest event…the earliest event is a different setting from the lookback. In the example I gave, I didn’t specify ‘earliest’ event because I do want to see all the distinct exposures to the drug for each person…this is so that the exposures that occur after the Target Cohort’s start_date will appear in the pathway if it exists. If i make my event cohorts ‘earliest’ then i’ll only get 1 exposure per person, and you usually don’t want that in your event cohorts. Therefore, to your point, we would not lose subsequent events. I think the confusion here was that you thought that the event chorts were set up to be ‘earliest per person’, but they are not, for exactly the reason you describe.
Those DRUG A - DRUG D are all event cohorts, what’s missing is the time window of your Target Cohort…but for sake of argument, let’s say that the person you are describing (with the 4 drugs) all these exposures occur during their presence in the Target Cohort.
In both the case of 5 day collapse and 2 day collapse, all the dates in your examples are within 2 days of each other…I have to check the implementation but I believe the Drug A on Jan 1 will be combined to the Drug C on Jan2 and the Drug B will also be combined to the same date as Drug A and Drug C. But, let’s pretend that it doesn’t work like that and we start with the 5 day collapse: with a 5 day collapse, you will have 1 combination exposure of A+B+C starting on Jan 1, and finishing on a drug exposure of A+B+C+D on Jan 10. With a 2 day collapse, you will have Drug A+B on Jan 1, followed by Drug A+B+C on Jan 3, Drug A+B+C+D on Jan 8 and finishing with A+B+D on Jan 10. For completeness, if you set a collapse window of 0 days, you would get Drug A → Drug A+C → DRUG A+B+C ->Drug A+B+D. Sorry if this is a bit unclear, the way you have your drug examples staggered makes it a little hard to construct in my mind, i would have sorted those drug exposures by their start date so that it’s not so confusing to have drug B start after drug C.
No, i was referring to either the start date or the end date of a given episode in an event cohort. we use both the start dates and end dates of the event cohorts to determine when the actual event combination ends.
Right, if the dates are within the combination window, they will be considered a combination exposure.
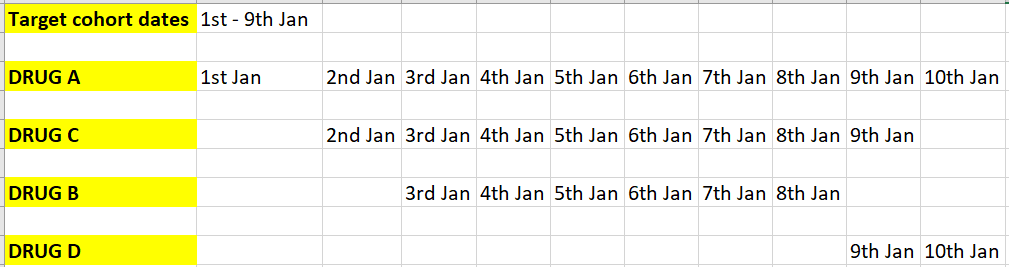
@Chris_Knoll - Thanks for your response and patience. Hopefully this will be the last question on this topic. Please bear with me. I have modified the example based on your suggestion
so now,we have target cohort date which is from 1st Jan - 9th Jan
MONOTHERAPY - This subject has 4 drug treatments (first line therapy to 4th line therapy). period this is done.
If we are looking at COMBINATION THERAPY with a window of 5 days -
a) Drug A starts on Jan 1st and ends on 10th
b) Drug C starts on Jan 2nd and ends on 9th
c) Drug B starts on Jan 3rd and ends on 8th
d) Drug D starts on Jan 9th and ends on Jan 10th
So now w.r.t to target cohort start date which is Jan 1st , all these are within 5 day combination window (except DRUG D), so our combination therapy start date (just by looking at start dates) will be Jan 1st (lowest of all). Am I right till here?
now w.r.t to target cohort end date which is Jan 9th, it is only Drug B,Drug C & Drug D which satisfies the 5 day window.
So from step 1) - DRUG A , B & C and step 2) - DRUG B,DRUG C & DRUG D, it is only Drug B & Drug C for whomboth the event dates (drug exposure start and end dates) fall within the target cohort start and end dates.** So it’s only DRUG B & DRUG C which are under combination therapy fromJan 2nd - Jan 8th. Am I right?
Drug D will just be present as a monotherapy. Right?
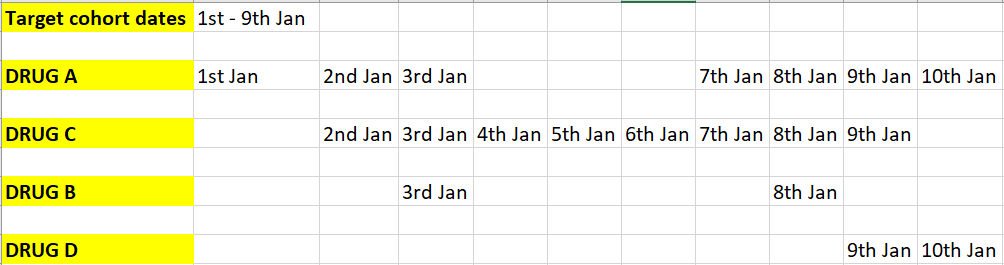
same target cohort dates and combination window of 5 days but different dates for drug treatments.
DRUG A episode 1 - Jan 1st- 3rd
DRUG A episode 2 - Jan 7th - 10th
DRUG C single episode - Jan 2nd - Jan 9th
DRUG B episode 1 - Jan 3rd
DRUG B episode 2 - 8th Jan
DRUG D episode 1 - Jan 9th - 10th
In a case like this, am I right to understand that DRUG C & DRUG B will remain under combination therapy as their exposure start and end dates fall within 5 days of target cohort dates (provided I choose “all events” under cohort entry criteria of event cohort (DRUG B)?
If I had chosen “earliest event” under cohort entry criteria of event cohort (DRUG B), it would have restricted it to Jan 3rd record and in this case it violates the 5 day comb window condition, so basically there will be no combination therapy. Am I right?
In essence, for treatment to be called as combination therapy we want to have both exposure start and event dates fall within a combination window. Any one event date fails, it will not be part of combination therapy.
I think the fundamental issue I think we are having here is about terminology: you’re taking about ‘combination therapy’ as if the tool can identify the intent of the treatments was to be used as a ‘combination therapy’ regimen. But, this is not the case.
I totally understand the confusion between calling this paramter ‘combination window’ and what you are thinking as a ‘combination therapy’, but the only thing that the ‘combination window’ parameter is trying to solve is the following:
Given 2 patients:
Patient 1 has Drug A 2 days before Drug B
Patient 2 has Drug A 2 days after Drug B.
Do you want to have in the result:
1 person had A->B
1 person had B->A combination window = 0 days
Or
2 people had A+B. combination window = 5 days
That’s it! It’s not making a judgement about identifying combination therapies. It is allowing you to reduce ‘pathway noise’ by taking events that happened on two different days, and considering them all happening on the same day if they are within a time window (this is the ‘combination window’).
If you want to interpret the event cohorts that overlap as ‘combination therapy’ you are free to do so, but if you point out something that really isn’t a combination therapy, the tool is only showing you what patterns are appearing in the data. It’s not evaluating if 2 overlapping things are clinical applications of combination therapy.
Thanks for your patience and answering my questions. Last question with a combination window of 5 days, we see that 2 people are combined to have (A+B). This is possible only when BOTH the drug exposure start date and drug exposure end date fall within combination window. Am I right?
Meaning
person 1 (from your example above)
IF difference (drug_exposure start date of A, drug_exposure start date of B) < 5 AND difference (drug_exposure end date of A, drug_exposure end date of B) < 5
THEN COMBINE
else
NOT COMBINE
Not quite: it ‘collapses’ any dates within 5 days of each other to the same date. In code, all dates (starts and ends) are put into 1 large list of dates, and then each date is determined if it should be ‘re-assigned’ to another date. Then once the distinct dates are given their re-assignments, the start dates and end dates are updated, and then the pathway analysis is performed.
If you put in a combination window of 9999999, every start and end date will be reassigned to the same (earliest) start date. This is an extreme and not-intended-to-be-real example, but hopefully clarifies the mechanism.
If you had to write it in code, this is the pseudo code would be something like:
List<Date> allDates = getAllDatesFromEventCohorts();
allDates.sort(); // order dates from earliest to latest
HashTable<Date,Date> replacments = new Hashtable<>();
collapseDate = allDates[0]; // default collapseDate is the first date
for (i =1; i< allDates.length(); i++) // note, start at the second, because the first will not ever be reassigned, and we need to look at the prior, so [i-1] needs to be valid.
{
if (DateDiff(allDates[i-1], allDates[i]) < comboWindow)
{
replacements.put(allDates[i], collapseDate); // record a replacement date for this date
}
else
{
collapseDate = allDates[i]; // update the replacement date since it is outside of the combine window of the previous date
}
}
// Finally go to each start and end date from your cohort events
// and replace the start/end date with the replacement.
I have tried to create a scenario based on the pseudo code that you shared. The below example is for one patient who has two event cohorts (drug A and drug B). can you confirm my understanding below? uploaded the excel file if you wish to make any changes to my example.
In your pseudo code, under the else clause do we have to update the hash-table as well?. Is it missing? May I know what’s the use in just updating collapse date?
I get an output like below and based on my example, I feel it shouldn’t be combined. can you confirm?
Input
drug
start date
end date
alldates(sorted)
drug A
1st Jan
10th Jan
1
drug B
4th Jan
18th Jan
4
10
18
Initial settings
collapse date (CD)
1st Jan
Hashtable
empty
comb window
5 days
For loop
alldates[i-1]
alldates[i]
< comb window?
Hashtable
CD
i=1
1
4
TRUE
4th Jan = 1st Jan
1st Jan
i=2
4
10
FALSE
10th Jan
i=3
10
18
FALSE
18th Jan
Interim - Output
drug
start date
end date
drug A
1st Jan
10th Jan
drug B
1st Jan
18th Jan
Since the end dates of both events doesn’t satisfy the comb window condition, we don’t combine these two events. Am I right?
You have the algorithm correct (except in your final output, drug B’s start date should have been reassigned from 4th Jan to 1st Jan).
You should look at the attached PDF again for an explanation on how combination periods are defined. For your example:
Event Output
drug
start date
end date
drug A
1st Jan
10th Jan
drug B
1st Jan
10th Jan
drug B
10th Jan
18th Jan
Note how we ‘split’ Drug B’s event cohort into 2 segments based on Event A’s drug end date.
Now, we combine A & B together into a ‘A+B’ combination because both A and B have a matching Start and End date together. The final path is:
A+B → B
For clarity, let’s do the same thing on a non-adjusted example where we have a collapse window of 0 days:
0 Day Example
drug
start date
end date
drug A
1st Jan
10th Jan
drug B
4th Jan
18th Jan
These get split into:
Event Cohort Splits
drug
start date
end date
drug A
1st Jan
4th Jan
drug A
4th Jan
10th Jan
drug B
4th Jan
10th Jan
drug B
10th Jan
18th Jan
Combining the event cohorts who share a start and end date, we find that we can combine A+B on 4th Jan - 10th Jan, with a final path output of:
A->A+B->B
One element from the pseudo algorithm I gave you was the final step:
// Finally go to each start and end date from your cohort events
// and replace the start/end date with the replacement.
This means you re assign every start/end date for every event cohort to the replacement date that was stored in the hash table. That could mean that an event cohorts start date and end date are reassigned to the same date. For the pathway analysis, we’re not interested in the literal date, but rather assigning dates together for purposes of ‘reducing pathway noise’
I understand from you that we do this minimize noise. By noise minimization, we just combine separate events which are overlapping into one event. But can there be any other interpretation to this? Meaning if doctors/researchers look at this, i feel that they might/will interpret that these medications/treatments were under combination therapy? Of course, with the clause that we consider ‘n’ comb window days to make this work. bringing together two events if they satisfy ‘n’ comb window days conditions
You got it, only thing I would correct is in your ‘allDates’ you didn’t grab the distinct dates. we don’t need to check each instance of the same date, just need the unique dates. But, it came up with the same answer.
If you have a 5 day combination window, and you see in the output:
A → B : 10 people
B → A: 5 people
A+B → end: 50 people
You can say her that the use of drugs a and b together typically are administered in close proximity (within 5 days) but there are a few cases where A-then-B or B-then-A appear in data, and in those cases the exposure is separated by more than 5 days.
I think it makes sense to run the analysis with a 0 day gap, 5 day gap and 14 day gap just to see how the patterns in the pathway change with those different settings.
Suppose I want to use Cohort pathways to understand what percentage of patients newly diagnosed with COPD have one, two, three, etc emergency room visits after their diagnosis? The general problem is that I would like to know how many times patients in my target cohort enter and exit an event cohort. I’m having trouble implementing this since it seems like the second event in a cohort pathway must be a different event cohort than the first event. If I only have one event cohort and a patient enters and exits the event cohort 10 times their pathway will look the same as a patient who enters and exits the same event cohort only once.
I’m interested in seeing the repeats in the pathway. Is there a way to capture multiple occurrences of the same event as separate steps in a cohort pathway analysis in Atlas?
(By “multiple occurrences” I mean a patient enters, exits, then re-enters and exits the event cohort during one continuous observation period.)
Hi, @Adam_Black,
Sorry for late reply. I think counts of occurrences post-index isn’t the target usecas of pathway analysis. We have introduced (in 2.8) the pathway analysis option to ‘allow repeats’ which means things that show up as A->B->A->C->D->A will not be reduced to A->B->C->D if you set the allow repeats option. But we always will reduce A->A->A->B->B->B to A->B. Data in CDMs are typically that messy.
Instead, what you can do is use the new custom feature function that lets you specify an expression to count distinct dates post index. In this way, you can define an expresison like so:
count distinct dates
of Visit Occurrences with visit_concept_id of Emergency Room concept set
starting between 1 day after and all days after index
(index in this case will be cohort start date)
In the characterization report output, you will get a row of data showing you the min/p10/p25/median(p50)/p75/p90/max of the distinct ER visit dates per person. In this way, it’s a bit more powerful than pathway analysis for this usecas because you get 1 distribution statistic which tells you about the frequency of er visits post index in the population.
I have one correction tot he above output that I missed the first time (someone asked me about this example and I want to make sure I am accurate).
The problem with the above is that the DrugA end date should have been re-assigned to the 1st (making it look like drugA went from Jan 1 to Jan 1. That’s just the logic of the gap day reassignment: the 8th gets carried back to 1st because the 8th, 5th and 1st are within 5d when you hop from 8th to 5th back to first.
Note, this doesn’t chaange the resulting pathway: the splits now say DrugA 1st-1st, drugB 1st-1st, DrugB 1st-14th, Durg C 1st - 1st, 1st-14th, and 14th to 23rd yielding A+B+C --> B+C --> C as the example presents…but calculating different dates…the important point here is that if you’re using gap days, the dates can get re-assigned in a way that you shouldn’t look at the literal dates anymore, rather it’s just trying to reduce the noise from the different variations of switching.
As always, if you want the ‘true’ representation in the data, use 0 days gap and it will use the raw data. I think it’s sometimes a good idea to try it with 0 vs. > 0 gap just to see how the gap impacts the patterns.