Thank you for such a quick reply @Chris_Knoll!
So I used
# (I didn't get very inventive with the source key)
http://localhost:8080/WebAPI/cohortdefinition/3/report/OHDSI-CDMV5?mode=1
and the last few lines are:
{"methodName":"runWorker","fileName":"ThreadPoolExecutor.java","lineNumber":1149,"className":"java.util.concurrent.ThreadPoolExecutor","nativeMethod":false},
{"methodName":"run","fileName":"ThreadPoolExecutor.java","lineNumber":624,"className":"java.util.concurrent.ThreadPoolExecutor$Worker","nativeMethod":false},
{"methodName":"run","fileName":"TaskThread.java","lineNumber":61,"className":"org.apache.tomcat.util.threads.TaskThread$WrappingRunnable","nativeMethod":false},
{"methodName":"run","fileName":"Thread.java","lineNumber":748,"className":"java.lang.Thread","nativeMethod":false}],
"serverErrorMessage":{"line":1173,"column":null,"where":null,"schema":null,"sqlstate":"42P01","position":98,"severity":"ERROR","detail":null,"hint":null,"datatype":null,"constraint":null,"routine":"parserOpenTable","internalQuery":null,"internalPosition":0,
"message":"relation \"ohdsi.cohort_censor_stats\" does not exist","file":"d:\\pginstaller_12.auto\\postgres.windows-x64\\src\\backend\\parser\\parse_relation.c","table":null},
"sqlstate":"42P01","nextException":null,"errorCode":0,"message":"ERROR: relation \"ohdsi.cohort_censor_stats\" does not exist\n Position: 98",
"localizedMessage":"ERROR: relation \"ohdsi.cohort_censor_stats\" does not exist\n Position: 98","suppressed":[]},
"message":"PreparedStatementCallback; bad SQL grammar [select cs.base_count, cs.final_count, cc.lost_count from ohdsi.cohort_summary_stats cs left join ohdsi.cohort_censor_stats cc on cc.cohort_definition_id = cs.cohort_definition_id where cs.cohort_definition_id = ? and cs.mode_id = ?]; nested exception is org.postgresql.util.PSQLException: ERROR: relation \"ohdsi.cohort_censor_stats\" does not exist\n Position: 98",
"localizedMessage":"PreparedStatementCallback; bad SQL grammar [select cs.base_count, cs.final_count, cc.lost_count from ohdsi.cohort_summary_stats cs left join ohdsi.cohort_censor_stats cc on cc.cohort_definition_id = cs.cohort_definition_id where cs.cohort_definition_id = ? and cs.mode_id = ?]; nested exception is org.postgresql.util.PSQLException: ERROR: relation \"ohdsi.cohort_censor_stats\" does not exist\n Position: 98",
"suppressed":[]},
"headers":{"id":"6a055392-11d5-47f0-2222-22c710d88e6e","timestamp":1599183741355}}
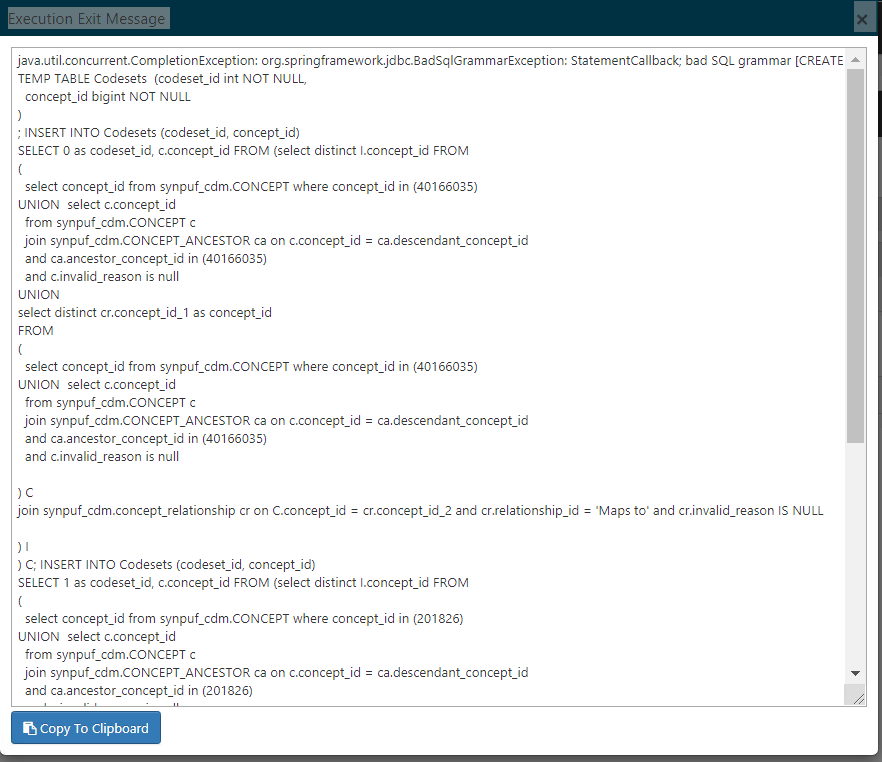
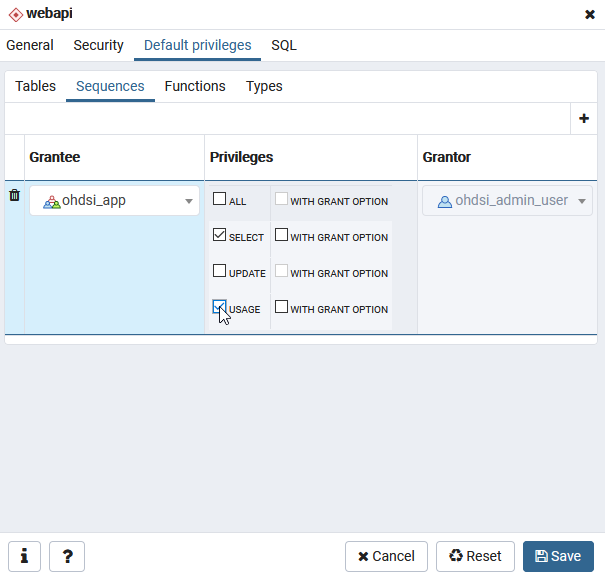
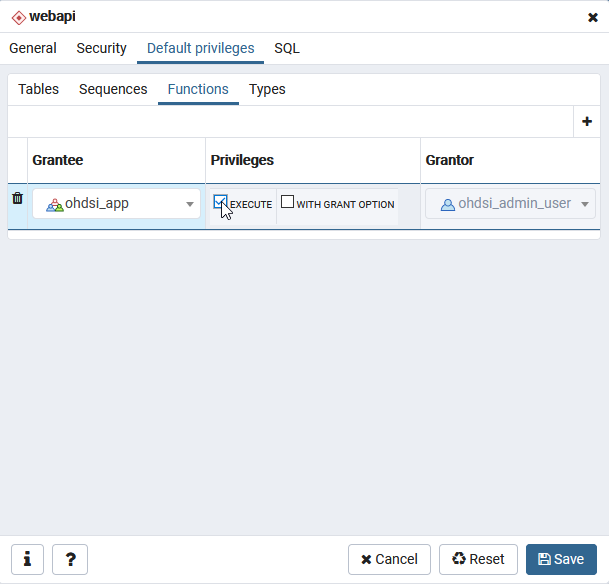
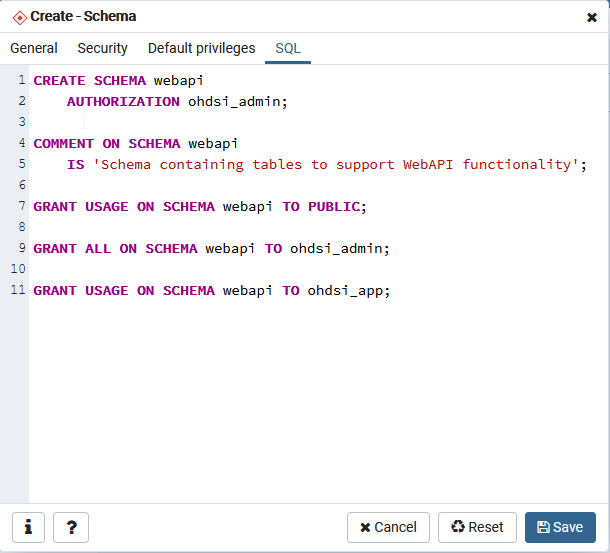
So it seems although the table cohort_censor_stats doesn’t exist when it’s expecting it to? (I can confirm I cannot find it in PGAdmin)
Does the fact that cohort_inclusion_stats_pkey from my last post exist mean there’s a versioning issue within Broadsea?
Thanks again
Ty