dear all,
I generate the cohort, but the numbers of people and records are always the same, just like the picture shows. So I am confused about the num, what is the difference?
The Records column shows you the total number of episodes in a cohort, while the People tells you the distinct patients in the cohort. If they are different (and it will always be Records >= People), it means that at least one person has more than 1 episode in the cohort.
If you use the ‘earliest event per person’ in your cohort definition, then there can only be one episode per person in a cohort.
Even if you don’t use ‘earliest event’ and pick ‘all events’, you could still only get one episode per person if your exit criteria would cause all events of a person to collapse into a single episode.
and also if that person really had just one episode in his/her entire observation period, right? ![]()
thank you very much @Chris_Knoll. I think I get what you say, but when the exit is end of the observation and I choose ‘all events’, the results also are the same.I don’t konw what is the problem, maybe I think I do not correctly understand the mean of the continuous observation. Just like the picture1 shows, if I set the continuous observation like picture2, I want to know the episodes in the red line like picture3 will all be in the cohort?So in this setting, the records num will be bigger than people num?
picture 1:
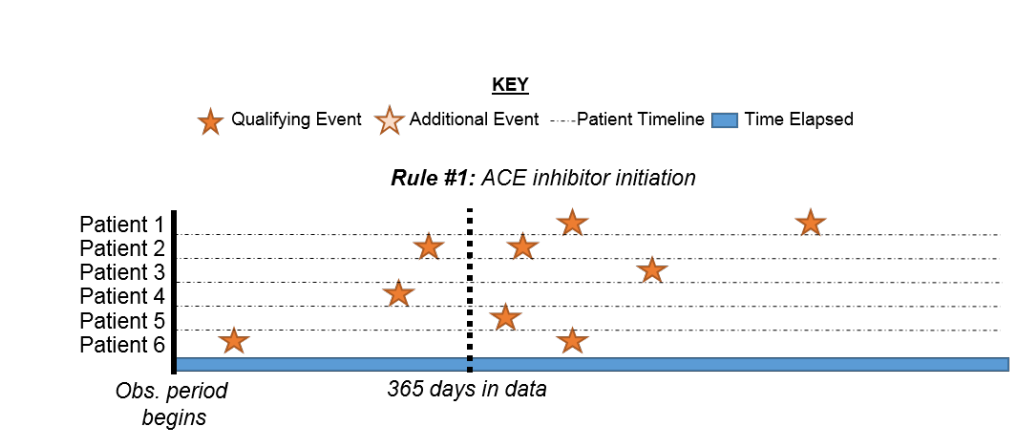
picture 2:
picture 3:
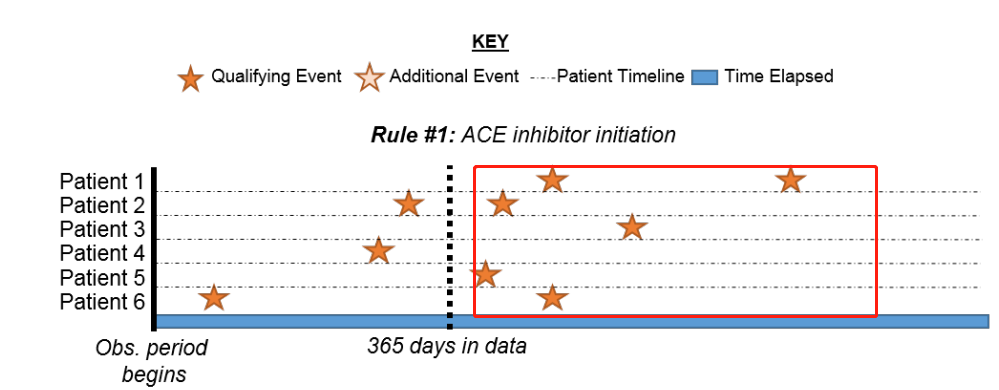
Right, this is the case where I explained it here:
In your picture, for the qualifying events where each of those stars in the red box are going to be used to create the cohort episodes. Since you have said that the individual events are going persist until end of observation, then the earliest event will be collapsed into any event after the earliest event. This will result in 1 event per person.
Like this:
|------------------------------|
|-----------------------|
|-------------|
Since cohorts can’t have overlapping episodes per person, the above becomes:
|------------------------------|
So, those 3 events become one episode per person, and records = persons.
What you are dealing with now is exactly what the records/person counts are trying to show you. You are expecting that you should have more than 1 episode per person, but the result is telling you that you only have 1 per person. Time to look at your cohort definition!
If you are expecting more than one event per person, then you need to specify how the qualifying events end. You do this through ‘Cohort Exit’ settings of your definition. The simplest one is that you say the event ends a fixed number of days after the event starts.
Give that a try, and run your cohort.
-Chris
1 Like
thank you very much @Chris_Knoll. Following your advice, I reset the event end 30 days after the event starts and choose ‘all events’, and then I get the cohort whose record num is bigger than person num. But at the same time, I find the events num is also bigger than the records num, just like the picture shows, I am a little confused about the meaning of the events num.

When you clicked ‘View Reports’, the lower part of the screen shows the ‘Inclusion Report’.
The Inclusion report indicates the number of cohort entry events that were qualified for your cohort. The ‘total events’ = ‘cohort entry’ events, and ‘matched’ = ‘events which satisfied all inclusion criteria’. In your cohort definition, you have no inclusion rules, so by default, all of the events ‘match’.
To reference back to your original picture, the ‘matched’ events would be all the starts in the red box (assuming you are only showing those events which match all inclusion criteria). If your diagram included ‘all cohort entry events, before inclusion rules applied’, then all the stars that were evaluated to check if they should be included in the cohort would be the ‘total events’.
Remember, in the end, we collapse all those ‘matched’ events into cohort episodes (described in the prior threads). So, in your example, 498,165 events got combined into 251,249 episodes, across 73,706 people.
If you actually had inclusion rules defined, you could say something like 'Among 732,462 entry events, 498,165 events matched all inclusion rules, which got combined into 251,249 episodes, across 73,706 people.
-Chris
Thank you very much @Chris_Knoll, I think I get what you say. There is just a little question.
Like the picutre1, as what you say, the events in the two red box are all matches (assuming I am only showing those events which match all inclusion criteria). And then for records, it is only the first event, is it right? thank you very much.
picture 1:
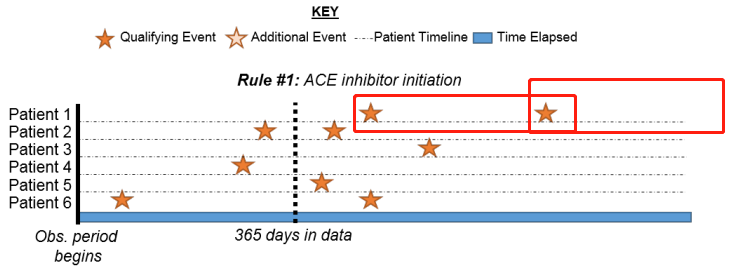
–panda
Records = episodes in the cohort.
If you made your Cohort Exit ‘until end of observation’, then the two stars would be ‘combined’ into a single episode, and you would just have 1 record (episode) for that person.
If you made your Cohort Exit ‘30 days after start’, then you would get 1 episode (record) for each of the stars you boxed, in that case it would be 2 records (episodes) for that person.
The Total Events/Matched Events are only useful for understanding your inclusion rules, so think about those numbers in a different context.
-Chris
1 Like
Get it @Chris_Knoll, Thank you very much
@Chris_Knoll - I am encountering the same issue but not in seeing the difference between records and people.
But the number shown under “records” (755) is different from what we have in db (783)
My question is when I give “fixed duration relative to an event”, I gave offset as 1 day (each record occurred on different dates to be treated separate)
But I still don’t see 783 instead it is 755.
I tried with 0, 1 & 30 days as well and it shows the same count of 755 instead of 783.
When I get the person count in the db, i see it is 783.
May I know what is use of having “date offset to 0 days”? Any example on when can this be useful?
For example (non-ideal), let’s say a person has record of smoking observation on 1st Jan 10.30 AM.
We have another record of smoking observation for the same person for 1st Jan 11.45 PM.
When I set 0 days as offset under “fixed duration event”, does Atlas removes them as they are overlapping (SAME DAY but not time)? Note am not using “end of continuous observation” to collapse it
Just trying to understand how collapse works for 0 days offset? If it doesn’t collapse for 0 days ,then it is same as “end of continuous observation”?
Can help us with this?
1 Like
On the cohort definition editor, you can see the actual SQL that was generated for the cohort. You can execute those statements in your own SQL IDE, and determine why/why not you are not finding the people you expect.