Hi there,
I am trying to build new Feature Analyses using ATLAS for continuous variable (e.g., BMI). How should I set it up so that only the latest value of BMI per patient was use to calculate the distribution?
Also, could someone explain how the Feature analyses parameters work?
Your example of the distribution feature that selects the ‘value as number’ from the measurement table for BMI measurement codes is how you would do this. It will show up in your characterization results with the avg, stddev, and IQRs for all measurements found within 1 year prior and including your cohort start date.
Re: Feature Analysis Paramaters: this is a feature extraction specific thing, and unless you need to change the meaning of ‘short term’, ‘medium term’ or ‘long term’ from -30, -180, -365 defaults, you can ignore these as none of the custom feature definitions use them.
Thanks @Chris_Knoll. And what should I do if I want to restrict to only using the latetest BMI measurement before index date per patient? As far as I understand with the current set up, all BMI values in the span of 1 year prior to index → index date are used.
That’s correct. There isn’t a way using criteria to select the ‘latest’ record for counting, but it does sound like a good enhancement. Currently, the only way to return 1 measurement value per person is to apply the aggregate functions (average, max, min) for the value as number instead of the raw value as number that you show above.
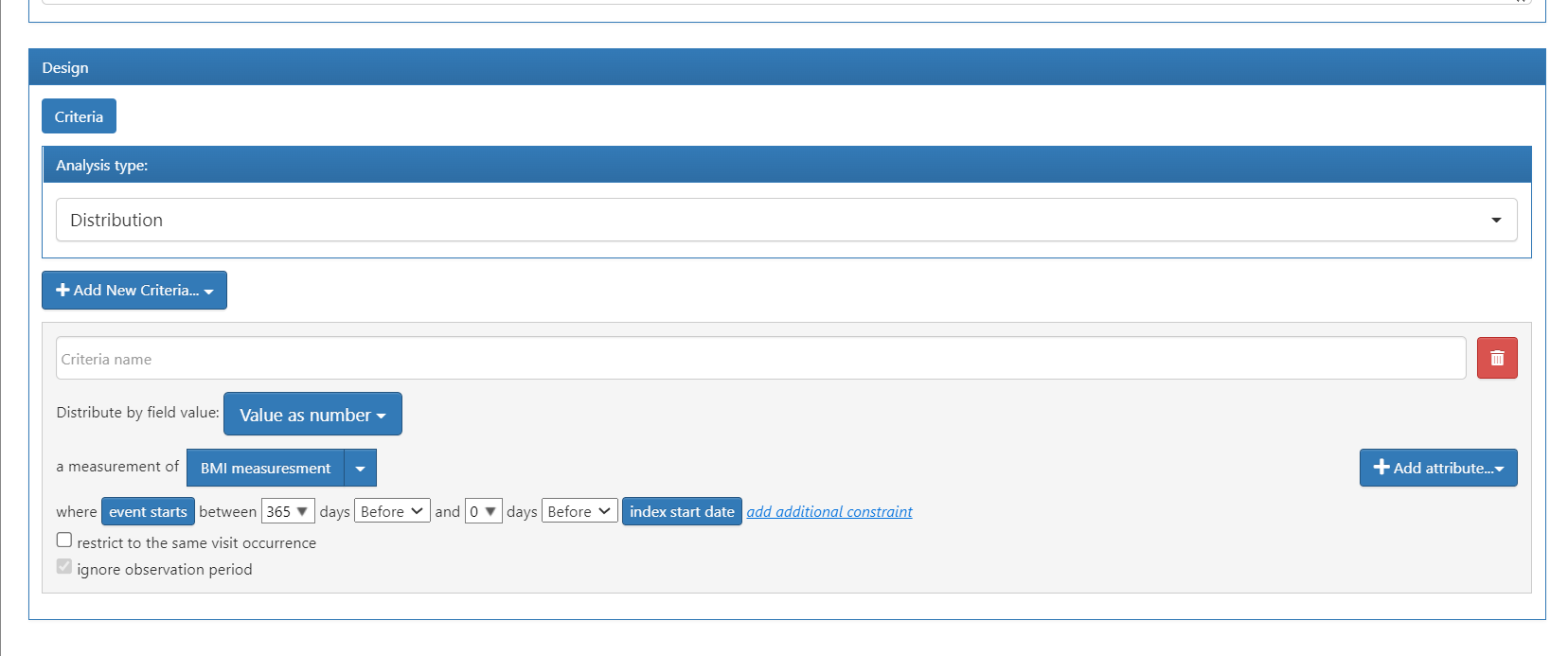

 I think having the option of using the latest value makes sense esp in the case of lab values
I think having the option of using the latest value makes sense esp in the case of lab values